 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Autoencoders for Interpretable Emotion Control in Text-to-Speech
May 31, 2026Integrating large language models (LLMs) into text-to-speech (TTS) systems has improved speech expressiveness, yet interpretable emotional control remains challenging. Existing approaches primarily rely on external conditioning or global activation steering, offering limited insight into the internal representations underlying emotional control. In this work, we analyze emotion-related variation in the semantic hidden states of LLM-based TTS models using sparse autoencoders (SAEs) to identify sparse latent features. Our analysis shows that emotional variation is distributed across multiple sparse latent features, while intervening on a small subset enables interpretable emotion control. Building on this observation, we introduce a feature-level intervention framework for bidirectional emotion induction and suppression without modifying backbone parameters. We further show that distinct latent features are associated with specific acoustic attributes (e.g., pitch), suggesting that emotional expression arises from coordinated latent contributions rather than a single global shift. Empirically, steering these sparse latent features achieves comparable or superior emotion induction and suppression performance relative to global steering and existing TTS baselines.
Hy-MT2: A Family of Fast, Efficient and Powerful Multilingual Translation Models in the Wild
May 21, 2026Hy-MT2 is a family of fast-thinking multilingual translation models designed for complex real-world scenarios. It includes three model sizes: 1.8B, 7B, and 30B-A3B (MoE), all of which support translation among 33 languages and effectively follow translation instructions in multiple languages. For on-device deployment, with AngelSlim 1.25-bit extreme quantization, the 1.8B model requires only 440 MB of storage and improves inference speed by 1.5x. Multi-dimensional evaluations show that Hy-MT2 delivers outstanding performance across general, real-world business, domain-specific, and instruction-following translation tasks. The 7B and 30B models outperform open-source models such as DeepSeek-V4-Pro and Kimi K2.6 in fast-thinking mode, while the lightweight 1.8B model also surpasses mainstream commercial APIs from providers such as Microsoft and Doubao overall.
Explore the vulnerability of black-box models via diffusion models
Jun 09, 2025



Recent advancements in diffusion models have enabled high-fidelity and photorealistic image generation across diverse applications. However, these models also present security and privacy risks, including copyright violations, sensitive information leakage, and the creation of harmful or offensive content that could be exploited maliciously. In this study, we uncover a novel security threat where an attacker leverages diffusion model APIs to generate synthetic images, which are then used to train a high-performing substitute model. This enables the attacker to execute model extraction and transfer-based adversarial attacks on black-box classification models with minimal queries, without needing access to the original training data. The generated images are sufficiently high-resolution and diverse to train a substitute model whose outputs closely match those of the target model. Across the seven benchmarks, including CIFAR and ImageNet subsets, our method shows an average improvement of 27.37% over state-of-the-art methods while using just 0.01 times of the query budget, achieving a 98.68% success rate in adversarial attacks on the target model.
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
MedEthicEval: Evaluating Large Language Models Based on Chinese Medical Ethics
Mar 04, 2025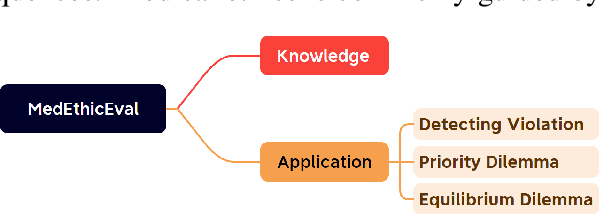


Large language models (LLMs) demonstrate significant potential in advancing medical applications, yet their capabilities in addressing medical ethics challenges remain underexplored. This paper introduces MedEthicEval, a novel benchmark designed to systematically evaluate LLMs in the domain of medical ethics. Our framework encompasses two key components: knowledge, assessing the models' grasp of medical ethics principles, and application, focusing on their ability to apply these principles across diverse scenarios. To support this benchmark, we consulted with medical ethics researchers and developed three datasets addressing distinct ethical challenges: blatant violations of medical ethics, priority dilemmas with clear inclinations, and equilibrium dilemmas without obvious resolutions. MedEthicEval serves as a critical tool for understanding LLMs' ethical reasoning in healthcare, paving the way for their responsible and effective use in medical contexts.
Hybrid Memory Replay: Blending Real and Distilled Data for Class Incremental Learning
Oct 20, 2024



Incremental learning (IL) aims to acquire new knowledge from current tasks while retaining knowledge learned from previous tasks. Replay-based IL methods store a set of exemplars from previous tasks in a buffer and replay them when learning new tasks. However, there is usually a size-limited buffer that cannot store adequate real exemplars to retain the knowledge of previous tasks. In contrast, data distillation (DD) can reduce the exemplar buffer's size, by condensing a large real dataset into a much smaller set of more information-compact synthetic exemplars. Nevertheless, DD's performance gain on IL quickly vanishes as the number of synthetic exemplars grows. To overcome the weaknesses of real-data and synthetic-data buffers, we instead optimize a hybrid memory including both types of data. Specifically, we propose an innovative modification to DD that distills synthetic data from a sliding window of checkpoints in history (rather than checkpoints on multiple training trajectories). Conditioned on the synthetic data, we then optimize the selection of real exemplars to provide complementary improvement to the DD objective. The optimized hybrid memory combines the strengths of synthetic and real exemplars, effectively mitigating catastrophic forgetting in Class IL (CIL) when the buffer size for exemplars is limited. Notably, our method can be seamlessly integrated into most existing replay-based CIL models. Extensive experiments across multiple benchmarks demonstrate that our method significantly outperforms existing replay-based baselines.
Fine-grained Text Style Transfer with Diffusion-Based Language Models
Jun 12, 2023



Diffusion probabilistic models have shown great success in generating high-quality images controllably, and researchers have tried to utilize this controllability into text generation domain. Previous works on diffusion-based language models have shown that they can be trained without external knowledge (such as pre-trained weights) and still achieve stable performance and controllability. In this paper, we trained a diffusion-based model on StylePTB dataset, the standard benchmark for fine-grained text style transfers. The tasks in StylePTB requires much more refined control over the output text compared to tasks evaluated in previous works, and our model was able to achieve state-of-the-art performance on StylePTB on both individual and compositional transfers. Moreover, our model, trained on limited data from StylePTB without external knowledge, outperforms previous works that utilized pretrained weights, embeddings, and external grammar parsers, and this may indicate that diffusion-based language models have great potential under low-resource settings.
XMorpher: Full Transformer for Deformable Medical Image Registration via Cross Attention
Jun 15, 2022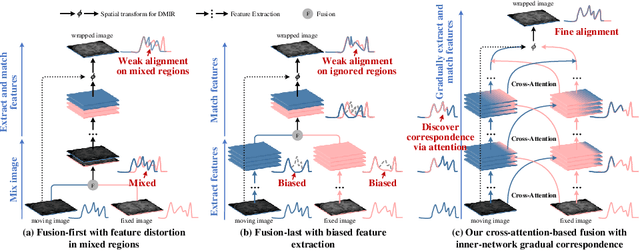
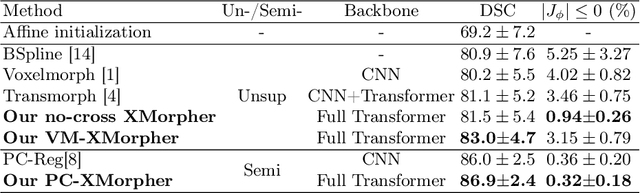
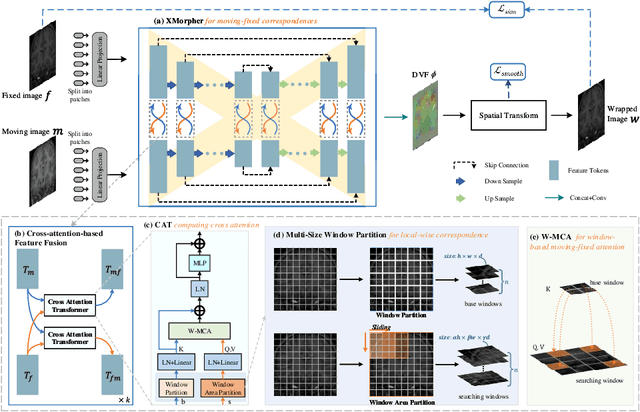
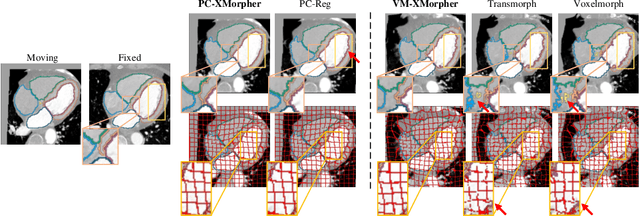
An effective backbone network is important to deep learning-based Deformable Medical Image Registration (DMIR), because it extracts and matches the features between two images to discover the mutual correspondence for fine registration. However, the existing deep networks focus on single image situation and are limited in registration task which is performed on paired images. Therefore, we advance a novel backbone network, XMorpher, for the effective corresponding feature representation in DMIR. 1) It proposes a novel full transformer architecture including dual parallel feature extraction networks which exchange information through cross attention, thus discovering multi-level semantic correspondence while extracting respective features gradually for final effective registration. 2) It advances the Cross Attention Transformer (CAT) blocks to establish the attention mechanism between images which is able to find the correspondence automatically and prompts the features to fuse efficiently in the network. 3) It constrains the attention computation between base windows and searching windows with different sizes, and thus focuses on the local transformation of deformable registration and enhances the computing efficiency at the same time. Without any bells and whistles, our XMorpher gives Voxelmorph 2.8% improvement on DSC , demonstrating its effective representation of the features from the paired images in DMIR. We believe that our XMorpher has great application potential in more paired medical images. Our XMorpher is open on https://github.com/Solemoon/XMorpher