 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Minimal Fine-Tuning of VLMs
Dec 22, 2025We introduce Image-LoRA, a lightweight parameter efficient fine-tuning (PEFT) recipe for transformer-based vision-language models (VLMs). Image-LoRA applies low-rank adaptation only to the value path of attention layers within the visual-token span, reducing adapter-only training FLOPs roughly in proportion to the visual-token fraction. We further adapt only a subset of attention heads, selected using head influence scores estimated with a rank-1 Image-LoRA, and stabilize per-layer updates via selection-size normalization. Across screen-centric grounding and referring benchmarks spanning text-heavy to image-heavy regimes, Image-LoRA matches or closely approaches standard LoRA accuracy while using fewer trainable parameters and lower adapter-only training FLOPs. The method also preserves the pure-text reasoning performance of VLMs before and after fine-tuning, as further shown on GSM8K.
Scalable Video-to-Dataset Generation for Cross-Platform Mobile Agents
May 19, 2025Recent advancements in Large Language Models (LLMs) and Vision-Language Models (VLMs) have sparked significant interest in developing GUI visual agents. We introduce MONDAY (Mobile OS Navigation Task Dataset for Agents from YouTube), a large-scale dataset of 313K annotated frames from 20K instructional videos capturing diverse real-world mobile OS navigation across multiple platforms. Models that include MONDAY in their pre-training phases demonstrate robust cross-platform generalization capabilities, consistently outperforming models trained on existing single OS datasets while achieving an average performance gain of 18.11%p on an unseen mobile OS platform. To enable continuous dataset expansion as mobile platforms evolve, we present an automated framework that leverages publicly available video content to create comprehensive task datasets without manual annotation. Our framework comprises robust OCR-based scene detection (95.04% F1score), near-perfect UI element detection (99.87% hit ratio), and novel multi-step action identification to extract reliable action sequences across diverse interface configurations. We contribute both the MONDAY dataset and our automated collection framework to facilitate future research in mobile OS navigation.
Visual Test-time Scaling for GUI Agent Grounding
May 01, 2025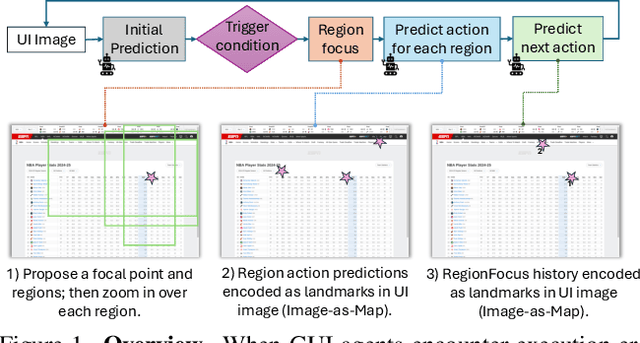
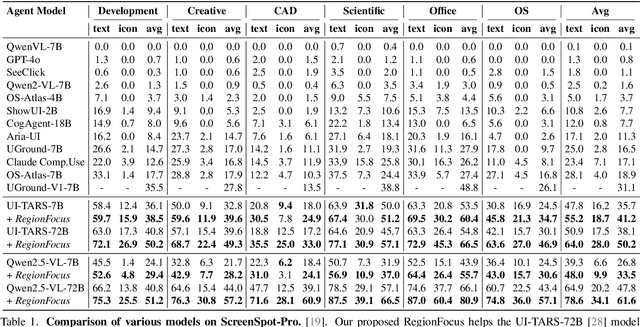
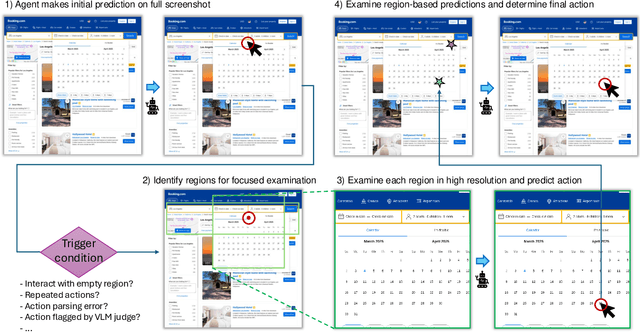
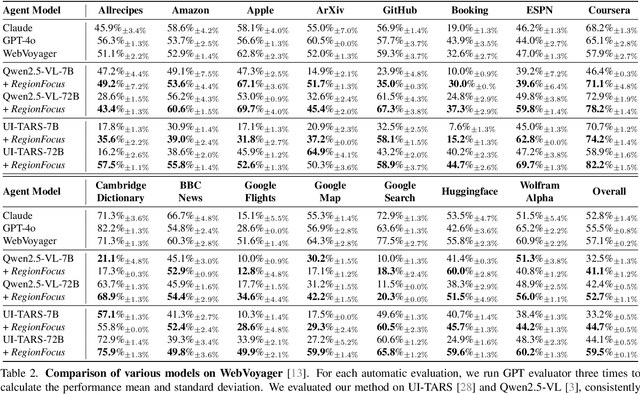
We introduce RegionFocus, a visual test-time scaling approach for Vision Language Model Agents. Understanding webpages is challenging due to the visual complexity of GUI images and the large number of interface elements, making accurate action selection difficult. Our approach dynamically zooms in on relevant regions, reducing background clutter and improving grounding accuracy. To support this process, we propose an image-as-map mechanism that visualizes key landmarks at each step, providing a transparent action record and enables the agent to effectively choose among action candidates. Even with a simple region selection strategy, we observe significant performance gains of 28+\% on Screenspot-pro and 24+\% on WebVoyager benchmarks on top of two state-of-the-art open vision language model agents, UI-TARS and Qwen2.5-VL, highlighting the effectiveness of visual test-time scaling in interactive settings. We achieve a new state-of-the-art grounding performance of 61.6\% on the ScreenSpot-Pro benchmark by applying RegionFocus to a Qwen2.5-VL-72B model. Our code will be released publicly at https://github.com/tiangeluo/RegionFocus.
Probing Visual Language Priors in VLMs
Dec 31, 2024



Despite recent advances in Vision-Language Models (VLMs), many still over-rely on visual language priors present in their training data rather than true visual reasoning. To examine the situation, we introduce ViLP, a visual question answering (VQA) benchmark that pairs each question with three potential answers and three corresponding images: one image whose answer can be inferred from text alone, and two images that demand visual reasoning. By leveraging image generative models, we ensure significant variation in texture, shape, conceptual combinations, hallucinated elements, and proverb-based contexts, making our benchmark images distinctly out-of-distribution. While humans achieve near-perfect accuracy, modern VLMs falter; for instance, GPT-4 achieves only 66.17% on ViLP. To alleviate this, we propose a self-improving framework in which models generate new VQA pairs and images, then apply pixel-level and semantic corruptions to form "good-bad" image pairs for self-training. Our training objectives compel VLMs to focus more on actual visual inputs and have demonstrated their effectiveness in enhancing the performance of open-source VLMs, including LLaVA-v1.5 and Cambrian.
View Selection for 3D Captioning via Diffusion Ranking
Apr 11, 2024



Scalable annotation approaches are crucial for constructing extensive 3D-text datasets, facilitating a broader range of applications. However, existing methods sometimes lead to the generation of hallucinated captions, compromising caption quality. This paper explores the issue of hallucination in 3D object captioning, with a focus on Cap3D method, which renders 3D objects into 2D views for captioning using pre-trained models. We pinpoint a major challenge: certain rendered views of 3D objects are atypical, deviating from the training data of standard image captioning models and causing hallucinations. To tackle this, we present DiffuRank, a method that leverages a pre-trained text-to-3D model to assess the alignment between 3D objects and their 2D rendered views, where the view with high alignment closely represent the object's characteristics. By ranking all rendered views and feeding the top-ranked ones into GPT4-Vision, we enhance the accuracy and detail of captions, enabling the correction of 200k captions in the Cap3D dataset and extending it to 1 million captions across Objaverse and Objaverse-XL datasets. Additionally, we showcase the adaptability of DiffuRank by applying it to pre-trained text-to-image models for a Visual Question Answering task, where it outperforms the CLIP model.
Scalable 3D Captioning with Pretrained Models
Jun 16, 2023We introduce Cap3D, an automatic approach for generating descriptive text for 3D objects. This approach utilizes pretrained models from image captioning, image-text alignment, and LLM to consolidate captions from multiple views of a 3D asset, completely side-stepping the time-consuming and costly process of manual annotation. We apply Cap3D to the recently introduced large-scale 3D dataset, Objaverse, resulting in 660k 3D-text pairs. Our evaluation, conducted using 41k human annotations from the same dataset, demonstrates that Cap3D surpasses human-authored descriptions in terms of quality, cost, and speed. Through effective prompt engineering, Cap3D rivals human performance in generating geometric descriptions on 17k collected annotations from the ABO dataset. Finally, we finetune Text-to-3D models on Cap3D and human captions, and show Cap3D outperforms; and benchmark the SOTA including Point-E, Shape-E, and DreamFusion.
Fine-grained Text Style Transfer with Diffusion-Based Language Models
Jun 12, 2023



Diffusion probabilistic models have shown great success in generating high-quality images controllably, and researchers have tried to utilize this controllability into text generation domain. Previous works on diffusion-based language models have shown that they can be trained without external knowledge (such as pre-trained weights) and still achieve stable performance and controllability. In this paper, we trained a diffusion-based model on StylePTB dataset, the standard benchmark for fine-grained text style transfers. The tasks in StylePTB requires much more refined control over the output text compared to tasks evaluated in previous works, and our model was able to achieve state-of-the-art performance on StylePTB on both individual and compositional transfers. Moreover, our model, trained on limited data from StylePTB without external knowledge, outperforms previous works that utilized pretrained weights, embeddings, and external grammar parsers, and this may indicate that diffusion-based language models have great potential under low-resource settings.
Multimodal Subtask Graph Generation from Instructional Videos
Feb 17, 2023



Real-world tasks consist of multiple inter-dependent subtasks (e.g., a dirty pan needs to be washed before it can be used for cooking). In this work, we aim to model the causal dependencies between such subtasks from instructional videos describing the task. This is a challenging problem since complete information about the world is often inaccessible from videos, which demands robust learning mechanisms to understand the causal structure of events. We present Multimodal Subtask Graph Generation (MSG2), an approach that constructs a Subtask Graph defining the dependency between a task's subtasks relevant to a task from noisy web videos. Graphs generated by our multimodal approach are closer to human-annotated graphs compared to prior approaches. MSG2 further performs the downstream task of next subtask prediction 85% and 30% more accurately than recent video transformer models in the ProceL and CrossTask datasets, respectively.
Neural Shape Compiler: A Unified Framework for Transforming between Text, Point Cloud, and Program
Dec 25, 20223D shapes have complementary abstractions from low-level geometry to part-based hierarchies to languages, which convey different levels of information. This paper presents a unified framework to translate between pairs of shape abstractions: $\textit{Text}$ $\Longleftrightarrow$ $\textit{Point Cloud}$ $\Longleftrightarrow$ $\textit{Program}$. We propose $\textbf{Neural Shape Compiler}$ to model the abstraction transformation as a conditional generation process. It converts 3D shapes of three abstract types into unified discrete shape code, transforms each shape code into code of other abstract types through the proposed $\textit{ShapeCode Transformer}$, and decodes them to output the target shape abstraction. Point Cloud code is obtained in a class-agnostic way by the proposed $\textit{Point}$VQVAE. On Text2Shape, ShapeGlot, ABO, Genre, and Program Synthetic datasets, Neural Shape Compiler shows strengths in $\textit{Text}$ $\Longrightarrow$ $\textit{Point Cloud}$, $\textit{Point Cloud}$ $\Longrightarrow$ $\textit{Text}$, $\textit{Point Cloud}$ $\Longrightarrow$ $\textit{Program}$, and Point Cloud Completion tasks. Additionally, Neural Shape Compiler benefits from jointly training on all heterogeneous data and tasks.
RANDOM MASK: Towards Robust Convolutional Neural Networks
Jul 27, 2020

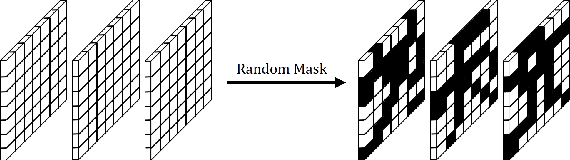

Robustness of neural networks has recently been highlighted by the adversarial examples, i.e., inputs added with well-designed perturbations which are imperceptible to humans but can cause the network to give incorrect outputs. In this paper, we design a new CNN architecture that by itself has good robustness. We introduce a simple but powerful technique, Random Mask, to modify existing CNN structures. We show that CNN with Random Mask achieves state-of-the-art performance against black-box adversarial attacks without applying any adversarial training. We next investigate the adversarial examples which 'fool' a CNN with Random Mask. Surprisingly, we find that these adversarial examples often 'fool' humans as well. This raises fundamental questions on how to define adversarial examples and robustness properly.