 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePri4R: Learning World Dynamics for Vision-Language-Action Models with Privileged 4D Representation
Mar 02, 2026Humans learn not only how their bodies move, but also how the surrounding world responds to their actions. In contrast, while recent Vision-Language-Action (VLA) models exhibit impressive semantic understanding, they often fail to capture the spatiotemporal dynamics governing physical interaction. In this paper, we introduce Pri4R, a simple yet effective approach that endows VLA models with an implicit understanding of world dynamics by leveraging privileged 4D information during training. Specifically, Pri4R augments VLAs with a lightweight point track head that predicts 3D point tracks. By injecting VLA features into this head to jointly predict future 3D trajectories, the model learns to incorporate evolving scene geometry within its shared representation space, enabling more physically aware context for precise control. Due to its architectural simplicity, Pri4R is compatible with dominant VLA design patterns with minimal changes. During inference, we run the model using the original VLA architecture unchanged; Pri4R adds no extra inputs, outputs, or computational overhead. Across simulation and real-world evaluations, Pri4R significantly improves performance on challenging manipulation tasks, including a +10% gain on LIBERO-Long and a +40% gain on RoboCasa. We further show that 3D point track prediction is an effective supervision target for learning action-world dynamics, and validate our design choices through extensive ablations.
MASH-VLM: Mitigating Action-Scene Hallucination in Video-LLMs through Disentangled Spatial-Temporal Representations
Mar 20, 2025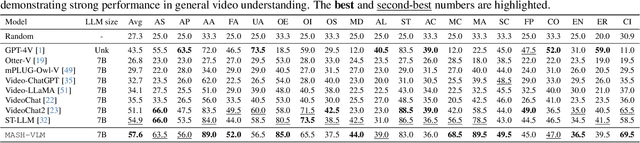
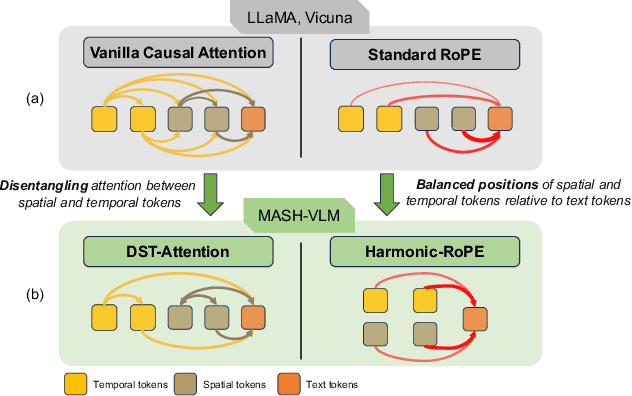
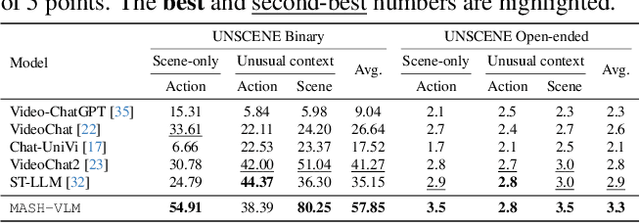
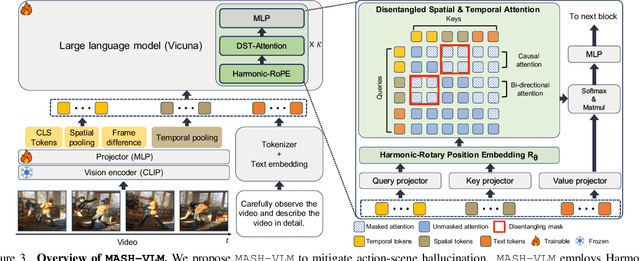
In this work, we tackle action-scene hallucination in Video Large Language Models (Video-LLMs), where models incorrectly predict actions based on the scene context or scenes based on observed actions. We observe that existing Video-LLMs often suffer from action-scene hallucination due to two main factors. First, existing Video-LLMs intermingle spatial and temporal features by applying an attention operation across all tokens. Second, they use the standard Rotary Position Embedding (RoPE), which causes the text tokens to overemphasize certain types of tokens depending on their sequential orders. To address these issues, we introduce MASH-VLM, Mitigating Action-Scene Hallucination in Video-LLMs through disentangled spatial-temporal representations. Our approach includes two key innovations: (1) DST-attention, a novel attention mechanism that disentangles the spatial and temporal tokens within the LLM by using masked attention to restrict direct interactions between the spatial and temporal tokens; (2) Harmonic-RoPE, which extends the dimensionality of the positional IDs, allowing the spatial and temporal tokens to maintain balanced positions relative to the text tokens. To evaluate the action-scene hallucination in Video-LLMs, we introduce the UNSCENE benchmark with 1,320 videos and 4,078 QA pairs. Extensive experiments demonstrate that MASH-VLM achieves state-of-the-art results on the UNSCENE benchmark, as well as on existing video understanding benchmarks.
Probing Visual Language Priors in VLMs
Dec 31, 2024



Despite recent advances in Vision-Language Models (VLMs), many still over-rely on visual language priors present in their training data rather than true visual reasoning. To examine the situation, we introduce ViLP, a visual question answering (VQA) benchmark that pairs each question with three potential answers and three corresponding images: one image whose answer can be inferred from text alone, and two images that demand visual reasoning. By leveraging image generative models, we ensure significant variation in texture, shape, conceptual combinations, hallucinated elements, and proverb-based contexts, making our benchmark images distinctly out-of-distribution. While humans achieve near-perfect accuracy, modern VLMs falter; for instance, GPT-4 achieves only 66.17% on ViLP. To alleviate this, we propose a self-improving framework in which models generate new VQA pairs and images, then apply pixel-level and semantic corruptions to form "good-bad" image pairs for self-training. Our training objectives compel VLMs to focus more on actual visual inputs and have demonstrated their effectiveness in enhancing the performance of open-source VLMs, including LLaVA-v1.5 and Cambrian.
OmniSplat: Taming Feed-Forward 3D Gaussian Splatting for Omnidirectional Images with Editable Capabilities
Dec 21, 2024



Feed-forward 3D Gaussian Splatting (3DGS) models have gained significant popularity due to their ability to generate scenes immediately without needing per-scene optimization. Although omnidirectional images are getting more popular since they reduce the computation for image stitching to composite a holistic scene, existing feed-forward models are only designed for perspective images. The unique optical properties of omnidirectional images make it difficult for feature encoders to correctly understand the context of the image and make the Gaussian non-uniform in space, which hinders the image quality synthesized from novel views. We propose OmniSplat, a pioneering work for fast feed-forward 3DGS generation from a few omnidirectional images. We introduce Yin-Yang grid and decompose images based on it to reduce the domain gap between omnidirectional and perspective images. The Yin-Yang grid can use the existing CNN structure as it is, but its quasi-uniform characteristic allows the decomposed image to be similar to a perspective image, so it can exploit the strong prior knowledge of the learned feed-forward network. OmniSplat demonstrates higher reconstruction accuracy than existing feed-forward networks trained on perspective images. Furthermore, we enhance the segmentation consistency between omnidirectional images by leveraging attention from the encoder of OmniSplat, providing fast and clean 3DGS editing results.
StyLandGAN: A StyleGAN based Landscape Image Synthesis using Depth-map
May 13, 2022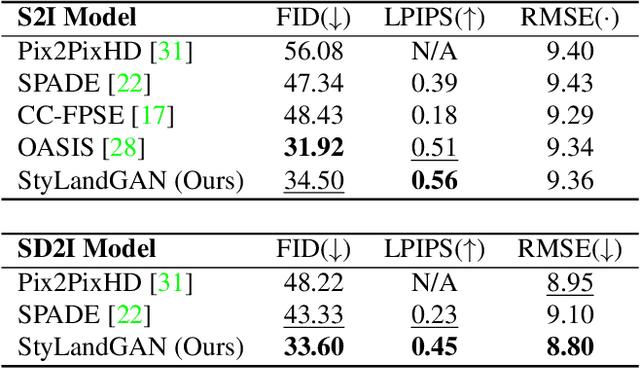

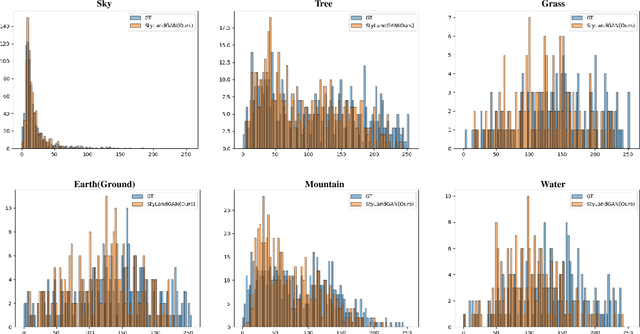
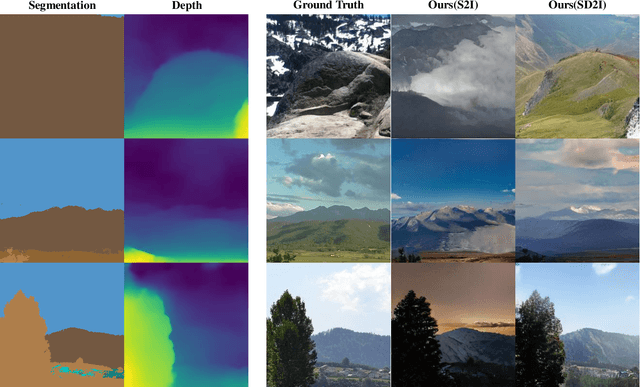
Despite recent success in conditional image synthesis, prevalent input conditions such as semantics and edges are not clear enough to express `Linear (Ridges)' and `Planar (Scale)' representations. To address this problem, we propose a novel framework StyLandGAN, which synthesizes desired landscape images using a depth map which has higher expressive power. Our StyleLandGAN is extended from the unconditional generation model to accept input conditions. We also propose a '2-phase inference' pipeline which generates diverse depth maps and shifts local parts so that it can easily reflect user's intend. As a comparison, we modified the existing semantic image synthesis models to accept a depth map as well. Experimental results show that our method is superior to existing methods in quality, diversity, and depth-accuracy.