 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoE3D: A Mixture-of-Experts Module for 3D Reconstruction
Jan 08, 2026MoE3D is a mixture-of-experts module designed to sharpen depth boundaries and mitigate flying-point artifacts (highlighted in red) of existing feed-forward 3D reconstruction models (left side). MoE3D predicts multiple candidate depth maps and fuses them via dynamic weighting (visualized by MoE weights on the right side). When integrated with a pre-trained 3D reconstruction backbone such as VGGT, it substantially enhances reconstruction quality with minimal additional computational overhead. Best viewed digitally.
Locate 3D: Real-World Object Localization via Self-Supervised Learning in 3D
Apr 19, 2025We present LOCATE 3D, a model for localizing objects in 3D scenes from referring expressions like "the small coffee table between the sofa and the lamp." LOCATE 3D sets a new state-of-the-art on standard referential grounding benchmarks and showcases robust generalization capabilities. Notably, LOCATE 3D operates directly on sensor observation streams (posed RGB-D frames), enabling real-world deployment on robots and AR devices. Key to our approach is 3D-JEPA, a novel self-supervised learning (SSL) algorithm applicable to sensor point clouds. It takes as input a 3D pointcloud featurized using 2D foundation models (CLIP, DINO). Subsequently, masked prediction in latent space is employed as a pretext task to aid the self-supervised learning of contextualized pointcloud features. Once trained, the 3D-JEPA encoder is finetuned alongside a language-conditioned decoder to jointly predict 3D masks and bounding boxes. Additionally, we introduce LOCATE 3D DATASET, a new dataset for 3D referential grounding, spanning multiple capture setups with over 130K annotations. This enables a systematic study of generalization capabilities as well as a stronger model.
LIFT-GS: Cross-Scene Render-Supervised Distillation for 3D Language Grounding
Feb 27, 2025Our approach to training 3D vision-language understanding models is to train a feedforward model that makes predictions in 3D, but never requires 3D labels and is supervised only in 2D, using 2D losses and differentiable rendering. The approach is new for vision-language understanding. By treating the reconstruction as a ``latent variable'', we can render the outputs without placing unnecessary constraints on the network architecture (e.g. can be used with decoder-only models). For training, only need images and camera pose, and 2D labels. We show that we can even remove the need for 2D labels by using pseudo-labels from pretrained 2D models. We demonstrate this to pretrain a network, and we finetune it for 3D vision-language understanding tasks. We show this approach outperforms baselines/sota for 3D vision-language grounding, and also outperforms other 3D pretraining techniques. Project page: https://liftgs.github.io.
Fast3R: Towards 3D Reconstruction of 1000+ Images in One Forward Pass
Jan 23, 2025Multi-view 3D reconstruction remains a core challenge in computer vision, particularly in applications requiring accurate and scalable representations across diverse perspectives. Current leading methods such as DUSt3R employ a fundamentally pairwise approach, processing images in pairs and necessitating costly global alignment procedures to reconstruct from multiple views. In this work, we propose Fast 3D Reconstruction (Fast3R), a novel multi-view generalization to DUSt3R that achieves efficient and scalable 3D reconstruction by processing many views in parallel. Fast3R's Transformer-based architecture forwards N images in a single forward pass, bypassing the need for iterative alignment. Through extensive experiments on camera pose estimation and 3D reconstruction, Fast3R demonstrates state-of-the-art performance, with significant improvements in inference speed and reduced error accumulation. These results establish Fast3R as a robust alternative for multi-view applications, offering enhanced scalability without compromising reconstruction accuracy.
Probing Visual Language Priors in VLMs
Dec 31, 2024



Despite recent advances in Vision-Language Models (VLMs), many still over-rely on visual language priors present in their training data rather than true visual reasoning. To examine the situation, we introduce ViLP, a visual question answering (VQA) benchmark that pairs each question with three potential answers and three corresponding images: one image whose answer can be inferred from text alone, and two images that demand visual reasoning. By leveraging image generative models, we ensure significant variation in texture, shape, conceptual combinations, hallucinated elements, and proverb-based contexts, making our benchmark images distinctly out-of-distribution. While humans achieve near-perfect accuracy, modern VLMs falter; for instance, GPT-4 achieves only 66.17% on ViLP. To alleviate this, we propose a self-improving framework in which models generate new VQA pairs and images, then apply pixel-level and semantic corruptions to form "good-bad" image pairs for self-training. Our training objectives compel VLMs to focus more on actual visual inputs and have demonstrated their effectiveness in enhancing the performance of open-source VLMs, including LLaVA-v1.5 and Cambrian.
Meta 3D Gen
Jul 02, 2024


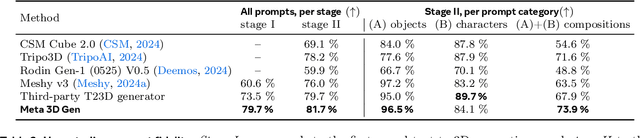
We introduce Meta 3D Gen (3DGen), a new state-of-the-art, fast pipeline for text-to-3D asset generation. 3DGen offers 3D asset creation with high prompt fidelity and high-quality 3D shapes and textures in under a minute. It supports physically-based rendering (PBR), necessary for 3D asset relighting in real-world applications. Additionally, 3DGen supports generative retexturing of previously generated (or artist-created) 3D shapes using additional textual inputs provided by the user. 3DGen integrates key technical components, Meta 3D AssetGen and Meta 3D TextureGen, that we developed for text-to-3D and text-to-texture generation, respectively. By combining their strengths, 3DGen represents 3D objects simultaneously in three ways: in view space, in volumetric space, and in UV (or texture) space. The integration of these two techniques achieves a win rate of 68% with respect to the single-stage model. We compare 3DGen to numerous industry baselines, and show that it outperforms them in terms of prompt fidelity and visual quality for complex textual prompts, while being significantly faster.
Lightplane: Highly-Scalable Components for Neural 3D Fields
Apr 30, 2024



Contemporary 3D research, particularly in reconstruction and generation, heavily relies on 2D images for inputs or supervision. However, current designs for these 2D-3D mapping are memory-intensive, posing a significant bottleneck for existing methods and hindering new applications. In response, we propose a pair of highly scalable components for 3D neural fields: Lightplane Render and Splatter, which significantly reduce memory usage in 2D-3D mapping. These innovations enable the processing of vastly more and higher resolution images with small memory and computational costs. We demonstrate their utility in various applications, from benefiting single-scene optimization with image-level losses to realizing a versatile pipeline for dramatically scaling 3D reconstruction and generation. Code: \url{https://github.com/facebookresearch/lightplane}.
DreamGaussian4D: Generative 4D Gaussian Splatting
Dec 29, 2023Remarkable progress has been made in 4D content generation recently. However, existing methods suffer from long optimization time, lack of motion controllability, and a low level of detail. In this paper, we introduce DreamGaussian4D, an efficient 4D generation framework that builds on 4D Gaussian Splatting representation. Our key insight is that the explicit modeling of spatial transformations in Gaussian Splatting makes it more suitable for the 4D generation setting compared with implicit representations. DreamGaussian4D reduces the optimization time from several hours to just a few minutes, allows flexible control of the generated 3D motion, and produces animated meshes that can be efficiently rendered in 3D engines.
EucliDreamer: Fast and High-Quality Texturing for 3D Models with Stable Diffusion Depth
Nov 27, 2023



This paper presents a novel method to generate textures for 3D models given text prompts and 3D meshes. Additional depth information is taken into account to perform the Score Distillation Sampling (SDS) process [28] with depth conditional Stable Diffusion [34]. We ran our model over the open-source dataset Objaverse [7] and conducted a user study to compare the results with those of various 3D texturing methods. We have shown that our model can generate more satisfactory results and produce various art styles for the same object. In addition, we achieved faster time when generating textures of comparable quality. We also conduct thorough ablation studies of how different factors may affect generation quality, including sampling steps, guidance scale, negative prompts, data augmentation, elevation range, and alternatives to SDS.
Text2Room: Extracting Textured 3D Meshes from 2D Text-to-Image Models
Mar 21, 2023We present Text2Room, a method for generating room-scale textured 3D meshes from a given text prompt as input. To this end, we leverage pre-trained 2D text-to-image models to synthesize a sequence of images from different poses. In order to lift these outputs into a consistent 3D scene representation, we combine monocular depth estimation with a text-conditioned inpainting model. The core idea of our approach is a tailored viewpoint selection such that the content of each image can be fused into a seamless, textured 3D mesh. More specifically, we propose a continuous alignment strategy that iteratively fuses scene frames with the existing geometry to create a seamless mesh. Unlike existing works that focus on generating single objects or zoom-out trajectories from text, our method generates complete 3D scenes with multiple objects and explicit 3D geometry. We evaluate our approach using qualitative and quantitative metrics, demonstrating it as the first method to generate room-scale 3D geometry with compelling textures from only text as input.