 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegment Anything Model for Road Network Graph Extraction
Mar 31, 2024



We propose SAM-Road, an adaptation of the Segment Anything Model (SAM) for extracting large-scale, vectorized road network graphs from satellite imagery. To predict graph geometry, we formulate it as a dense semantic segmentation task, leveraging the inherent strengths of SAM. The image encoder of SAM is fine-tuned to produce probability masks for roads and intersections, from which the graph vertices are extracted via simple non-maximum suppression. To predict graph topology, we designed a lightweight transformer-based graph neural network, which leverages the SAM image embeddings to estimate the edge existence probabilities between vertices. Our approach directly predicts the graph vertices and edges for large regions without expensive and complex post-processing heuristics, and is capable of building complete road network graphs spanning multiple square kilometers in a matter of seconds. With its simple, straightforward, and minimalist design, SAM-Road achieves comparable accuracy with the state-of-the-art method RNGDet++, while being 40 times faster on the City-scale dataset. We thus demonstrate the power of a foundational vision model when applied to a graph learning task. The code is available at https://github.com/htcr/sam_road.
EucliDreamer: Fast and High-Quality Texturing for 3D Models with Stable Diffusion Depth
Nov 27, 2023



This paper presents a novel method to generate textures for 3D models given text prompts and 3D meshes. Additional depth information is taken into account to perform the Score Distillation Sampling (SDS) process [28] with depth conditional Stable Diffusion [34]. We ran our model over the open-source dataset Objaverse [7] and conducted a user study to compare the results with those of various 3D texturing methods. We have shown that our model can generate more satisfactory results and produce various art styles for the same object. In addition, we achieved faster time when generating textures of comparable quality. We also conduct thorough ablation studies of how different factors may affect generation quality, including sampling steps, guidance scale, negative prompts, data augmentation, elevation range, and alternatives to SDS.
Novel View Synthesis from a Single RGBD Image for Indoor Scenes
Nov 02, 2023In this paper, we propose an approach for synthesizing novel view images from a single RGBD (Red Green Blue-Depth) input. Novel view synthesis (NVS) is an interesting computer vision task with extensive applications. Methods using multiple images has been well-studied, exemplary ones include training scene-specific Neural Radiance Fields (NeRF), or leveraging multi-view stereo (MVS) and 3D rendering pipelines. However, both are either computationally intensive or non-generalizable across different scenes, limiting their practical value. Conversely, the depth information embedded in RGBD images unlocks 3D potential from a singular view, simplifying NVS. The widespread availability of compact, affordable stereo cameras, and even LiDARs in contemporary devices like smartphones, makes capturing RGBD images more accessible than ever. In our method, we convert an RGBD image into a point cloud and render it from a different viewpoint, then formulate the NVS task into an image translation problem. We leveraged generative adversarial networks to style-transfer the rendered image, achieving a result similar to a photograph taken from the new perspective. We explore both unsupervised learning using CycleGAN and supervised learning with Pix2Pix, and demonstrate the qualitative results. Our method circumvents the limitations of traditional multi-image techniques, holding significant promise for practical, real-time applications in NVS.
Region-based Quality Estimation Network for Large-scale Person Re-identification
Dec 21, 2017
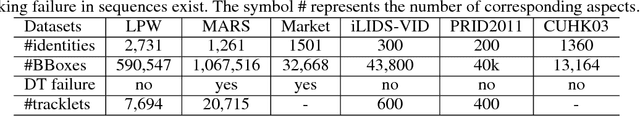
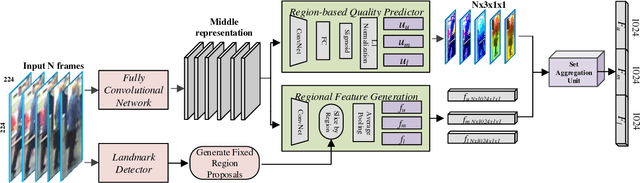
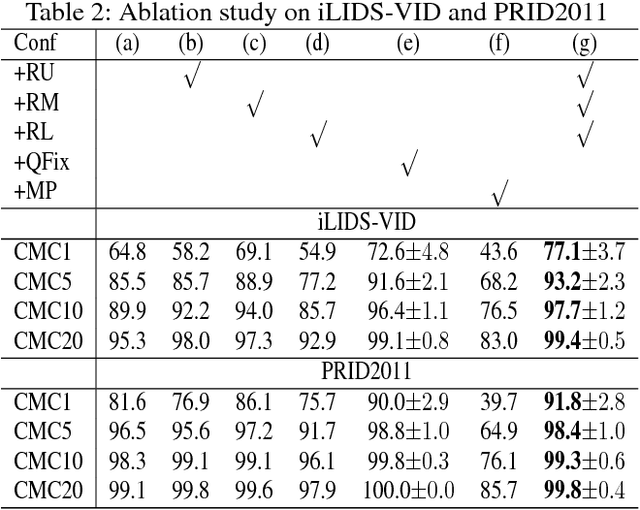
One of the major restrictions on the performance of video-based person re-id is partial noise caused by occlusion, blur and illumination. Since different spatial regions of a single frame have various quality, and the quality of the same region also varies across frames in a tracklet, a good way to address the problem is to effectively aggregate complementary information from all frames in a sequence, using better regions from other frames to compensate the influence of an image region with poor quality. To achieve this, we propose a novel Region-based Quality Estimation Network (RQEN), in which an ingenious training mechanism enables the effective learning to extract the complementary region-based information between different frames. Compared with other feature extraction methods, we achieved comparable results of 92.4%, 76.1% and 77.83% on the PRID 2011, iLIDS-VID and MARS, respectively. In addition, to alleviate the lack of clean large-scale person re-id datasets for the community, this paper also contributes a new high-quality dataset, named "Labeled Pedestrian in the Wild (LPW)" which contains 7,694 tracklets with over 590,000 images. Despite its relatively large scale, the annotations also possess high cleanliness. Moreover, it's more challenging in the following aspects: the age of characters varies from childhood to elderhood; the postures of people are diverse, including running and cycling in addition to the normal walking state.
Impression Network for Video Object Detection
Dec 16, 2017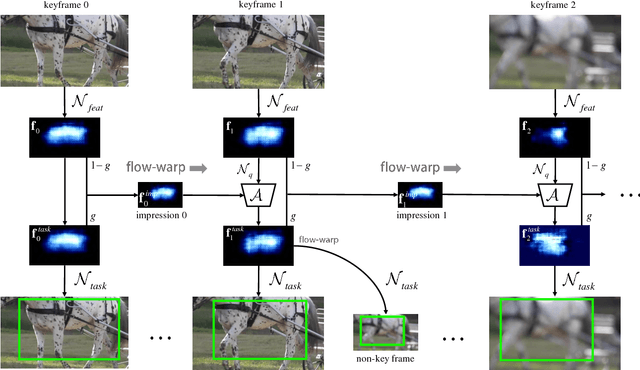
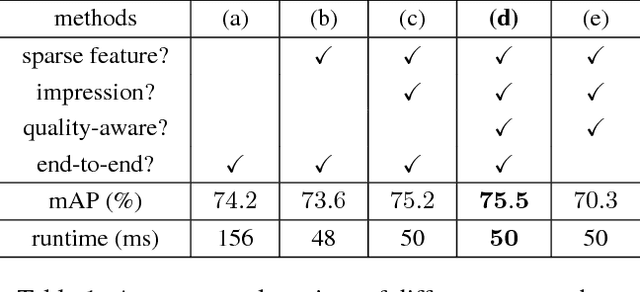

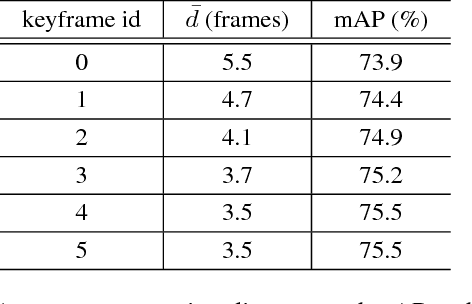
Video object detection is more challenging compared to image object detection. Previous works proved that applying object detector frame by frame is not only slow but also inaccurate. Visual clues get weakened by defocus and motion blur, causing failure on corresponding frames. Multi-frame feature fusion methods proved effective in improving the accuracy, but they dramatically sacrifice the speed. Feature propagation based methods proved effective in improving the speed, but they sacrifice the accuracy. So is it possible to improve speed and performance simultaneously? Inspired by how human utilize impression to recognize objects from blurry frames, we propose Impression Network that embodies a natural and efficient feature aggregation mechanism. In our framework, an impression feature is established by iteratively absorbing sparsely extracted frame features. The impression feature is propagated all the way down the video, helping enhance features of low-quality frames. This impression mechanism makes it possible to perform long-range multi-frame feature fusion among sparse keyframes with minimal overhead. It significantly improves per-frame detection baseline on ImageNet VID while being 3 times faster (20 fps). We hope Impression Network can provide a new perspective on video feature enhancement. Code will be made available.