 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegion-based Quality Estimation Network for Large-scale Person Re-identification
Paper and Code
Dec 21, 2017
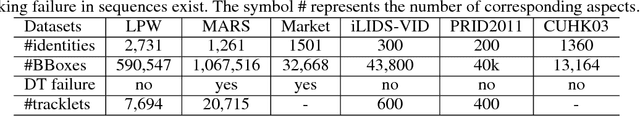
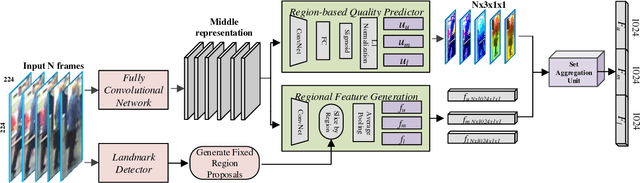
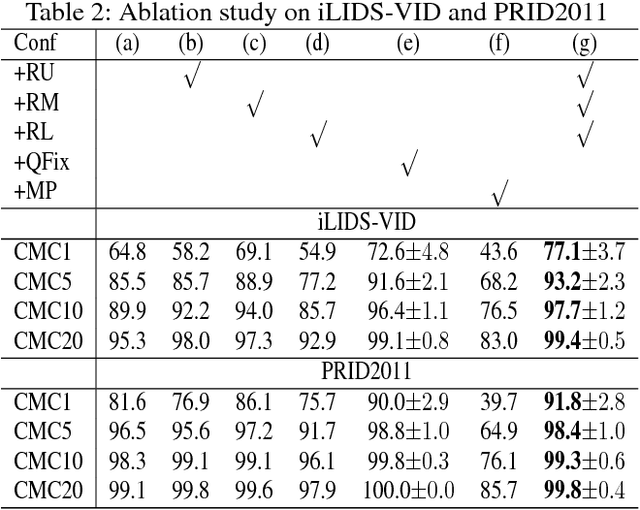
One of the major restrictions on the performance of video-based person re-id is partial noise caused by occlusion, blur and illumination. Since different spatial regions of a single frame have various quality, and the quality of the same region also varies across frames in a tracklet, a good way to address the problem is to effectively aggregate complementary information from all frames in a sequence, using better regions from other frames to compensate the influence of an image region with poor quality. To achieve this, we propose a novel Region-based Quality Estimation Network (RQEN), in which an ingenious training mechanism enables the effective learning to extract the complementary region-based information between different frames. Compared with other feature extraction methods, we achieved comparable results of 92.4%, 76.1% and 77.83% on the PRID 2011, iLIDS-VID and MARS, respectively. In addition, to alleviate the lack of clean large-scale person re-id datasets for the community, this paper also contributes a new high-quality dataset, named "Labeled Pedestrian in the Wild (LPW)" which contains 7,694 tracklets with over 590,000 images. Despite its relatively large scale, the annotations also possess high cleanliness. Moreover, it's more challenging in the following aspects: the age of characters varies from childhood to elderhood; the postures of people are diverse, including running and cycling in addition to the normal walking state.