 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFence off Anomaly Interference: Cross-Domain Distillation for Fully Unsupervised Anomaly Detection
Aug 25, 2025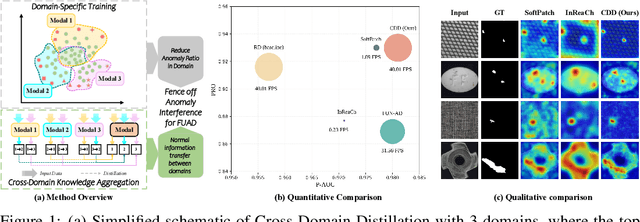

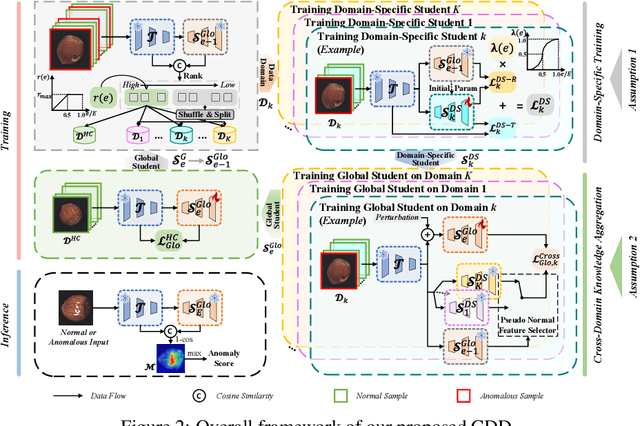
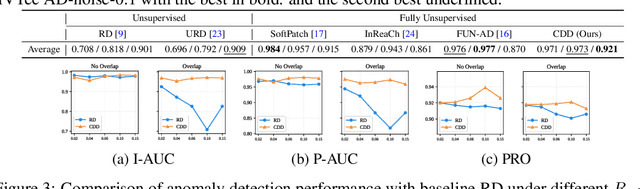
Fully Unsupervised Anomaly Detection (FUAD) is a practical extension of Unsupervised Anomaly Detection (UAD), aiming to detect anomalies without any labels even when the training set may contain anomalous samples. To achieve FUAD, we pioneer the introduction of Knowledge Distillation (KD) paradigm based on teacher-student framework into the FUAD setting. However, due to the presence of anomalies in the training data, traditional KD methods risk enabling the student to learn the teacher's representation of anomalies under FUAD setting, thereby resulting in poor anomaly detection performance. To address this issue, we propose a novel Cross-Domain Distillation (CDD) framework based on the widely studied reverse distillation (RD) paradigm. Specifically, we design a Domain-Specific Training, which divides the training set into multiple domains with lower anomaly ratios and train a domain-specific student for each. Cross-Domain Knowledge Aggregation is then performed, where pseudo-normal features generated by domain-specific students collaboratively guide a global student to learn generalized normal representations across all samples. Experimental results on noisy versions of the MVTec AD and VisA datasets demonstrate that our method achieves significant performance improvements over the baseline, validating its effectiveness under FUAD setting.
HGFormer: Topology-Aware Vision Transformer with HyperGraph Learning
Apr 03, 2025



The computer vision community has witnessed an extensive exploration of vision transformers in the past two years. Drawing inspiration from traditional schemes, numerous works focus on introducing vision-specific inductive biases. However, the implicit modeling of permutation invariance and fully-connected interaction with individual tokens disrupts the regional context and spatial topology, further hindering higher-order modeling. This deviates from the principle of perceptual organization that emphasizes the local groups and overall topology of visual elements. Thus, we introduce the concept of hypergraph for perceptual exploration. Specifically, we propose a topology-aware vision transformer called HyperGraph Transformer (HGFormer). Firstly, we present a Center Sampling K-Nearest Neighbors (CS-KNN) algorithm for semantic guidance during hypergraph construction. Secondly, we present a topology-aware HyperGraph Attention (HGA) mechanism that integrates hypergraph topology as perceptual indications to guide the aggregation of global and unbiased information during hypergraph messaging. Using HGFormer as visual backbone, we develop an effective and unitive representation, achieving distinct and detailed scene depictions. Empirical experiments show that the proposed HGFormer achieves competitive performance compared to the recent SoTA counterparts on various visual benchmarks. Extensive ablation and visualization studies provide comprehensive explanations of our ideas and contributions.
Unlocking the Potential of Reverse Distillation for Anomaly Detection
Dec 10, 2024Knowledge Distillation (KD) is a promising approach for unsupervised Anomaly Detection (AD). However, the student network's over-generalization often diminishes the crucial representation differences between teacher and student in anomalous regions, leading to detection failures. To addresses this problem, the widely accepted Reverse Distillation (RD) paradigm designs the asymmetry teacher and student, using an encoder as teacher and a decoder as student. Yet, the design of RD does not ensure that the teacher encoder effectively distinguishes between normal and abnormal features or that the student decoder generates anomaly-free features. Additionally, the absence of skip connections results in a loss of fine details during feature reconstruction. To address these issues, we propose RD with Expert, which introduces a novel Expert-Teacher-Student network for simultaneous distillation of both the teacher encoder and student decoder. The added expert network enhances the student's ability to generate normal features and optimizes the teacher's differentiation between normal and abnormal features, reducing missed detections. Additionally, Guided Information Injection is designed to filter and transfer features from teacher to student, improving detail reconstruction and minimizing false positives. Experiments on several benchmarks prove that our method outperforms existing unsupervised AD methods under RD paradigm, fully unlocking RD's potential.
Dual-Modeling Decouple Distillation for Unsupervised Anomaly Detection
Aug 07, 2024


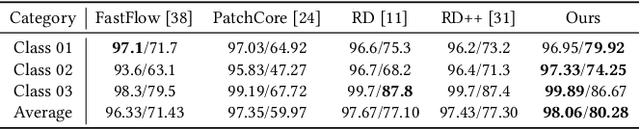
Knowledge distillation based on student-teacher network is one of the mainstream solution paradigms for the challenging unsupervised Anomaly Detection task, utilizing the difference in representation capabilities of the teacher and student networks to implement anomaly localization. However, over-generalization of the student network to the teacher network may lead to negligible differences in representation capabilities of anomaly, thus affecting the detection effectiveness. Existing methods address the possible over-generalization by using differentiated students and teachers from the structural perspective or explicitly expanding distilled information from the content perspective, which inevitably result in an increased likelihood of underfitting of the student network and poor anomaly detection capabilities in anomaly center or edge. In this paper, we propose Dual-Modeling Decouple Distillation (DMDD) for the unsupervised anomaly detection. In DMDD, a Decouple Student-Teacher Network is proposed to decouple the initial student features into normality and abnormality features. We further introduce Dual-Modeling Distillation based on normal-anomaly image pairs, fitting normality features of anomalous image and the teacher features of the corresponding normal image, widening the distance between abnormality features and the teacher features in anomalous regions. Synthesizing these two distillation ideas, we achieve anomaly detection which focuses on both edge and center of anomaly. Finally, a Multi-perception Segmentation Network is proposed to achieve focused anomaly map fusion based on multiple attention. Experimental results on MVTec AD show that DMDD surpasses SOTA localization performance of previous knowledge distillation-based methods, reaching 98.85% on pixel-level AUC and 96.13% on PRO.
Unifying Visual Perception by Dispersible Points Learning
Aug 18, 2022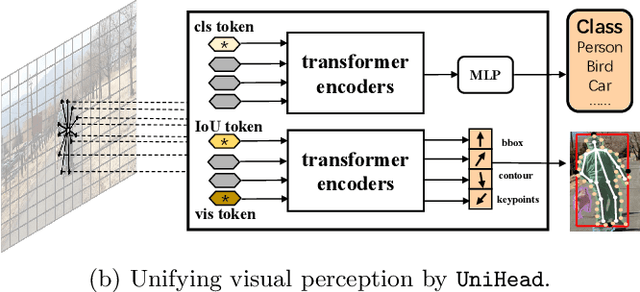
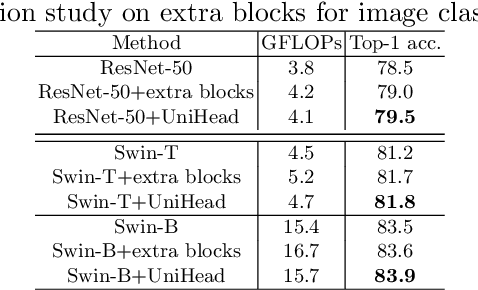
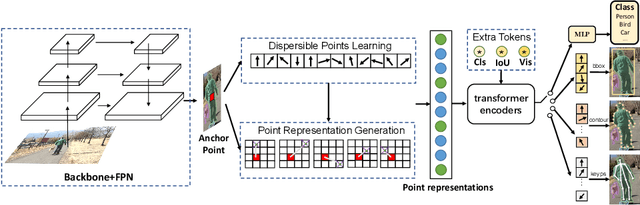
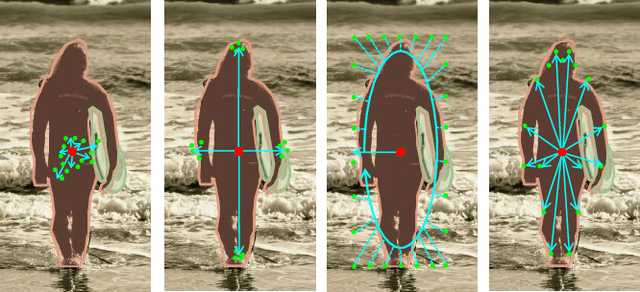
We present a conceptually simple, flexible, and universal visual perception head for variant visual tasks, e.g., classification, object detection, instance segmentation and pose estimation, and different frameworks, such as one-stage or two-stage pipelines. Our approach effectively identifies an object in an image while simultaneously generating a high-quality bounding box or contour-based segmentation mask or set of keypoints. The method, called UniHead, views different visual perception tasks as the dispersible points learning via the transformer encoder architecture. Given a fixed spatial coordinate, UniHead adaptively scatters it to different spatial points and reasons about their relations by transformer encoder. It directly outputs the final set of predictions in the form of multiple points, allowing us to perform different visual tasks in different frameworks with the same head design. We show extensive evaluations on ImageNet classification and all three tracks of the COCO suite of challenges, including object detection, instance segmentation and pose estimation. Without bells and whistles, UniHead can unify these visual tasks via a single visual head design and achieve comparable performance compared to expert models developed for each task.We hope our simple and universal UniHead will serve as a solid baseline and help promote universal visual perception research. Code and models are available at https://github.com/Sense-X/UniHead.
Self-slimmed Vision Transformer
Nov 24, 2021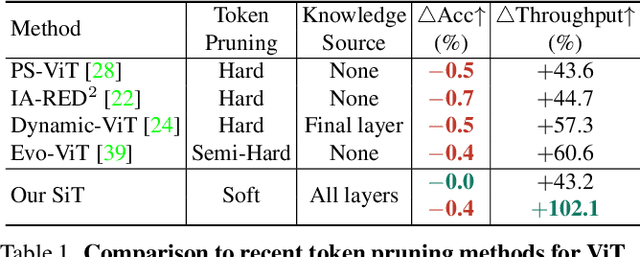
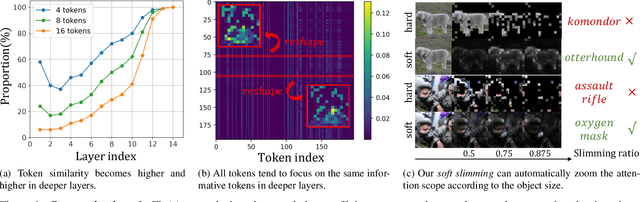
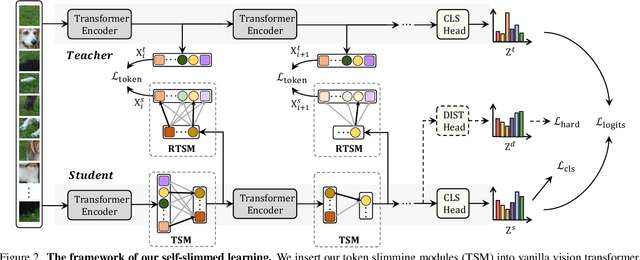
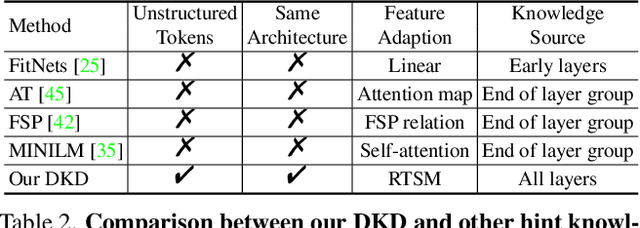
Vision transformers (ViTs) have become the popular structures and outperformed convolutional neural networks (CNNs) on various vision tasks. However, such powerful transformers bring a huge computation burden. And the essential barrier behind this is the exhausting token-to-token comparison. To alleviate this, we delve deeply into the model properties of ViT and observe that ViTs exhibit sparse attention with high token similarity. This intuitively introduces us a feasible structure-agnostic dimension, token number, to reduce the computational cost. Based on this exploration, we propose a generic self-slimmed learning approach for vanilla ViTs, namely SiT. Specifically, we first design a novel Token Slimming Module (TSM), which can boost the inference efficiency of ViTs by dynamic token aggregation. Different from the token hard dropping, our TSM softly integrates redundant tokens into fewer informative ones, which can dynamically zoom visual attention without cutting off discriminative token relations in the images. Furthermore, we introduce a concise Dense Knowledge Distillation (DKD) framework, which densely transfers unorganized token information in a flexible auto-encoder manner. Due to the similar structure between teacher and student, our framework can effectively leverage structure knowledge for better convergence. Finally, we conduct extensive experiments to evaluate our SiT. It demonstrates that our method can speed up ViTs by 1.7x with negligible accuracy drop, and even speed up ViTs by 3.6x while maintaining 97% of their performance. Surprisingly, by simply arming LV-ViT with our SiT, we achieve new state-of-the-art performance on ImageNet, surpassing all the CNNs and ViTs in the recent literature.
RCNet: Reverse Feature Pyramid and Cross-scale Shift Network for Object Detection
Oct 23, 2021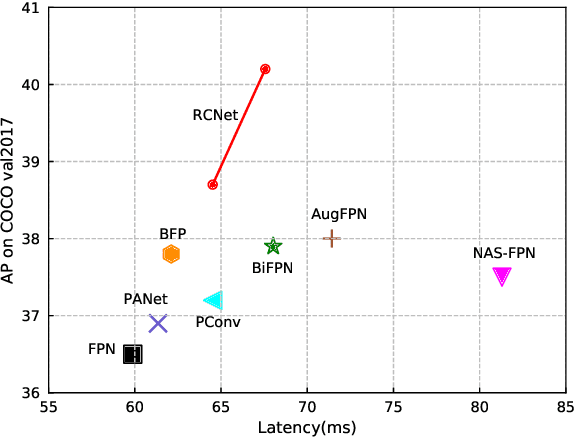
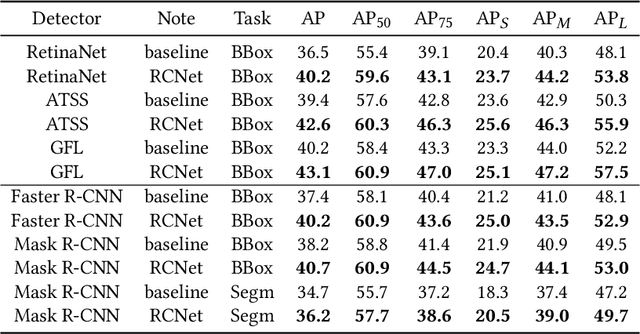
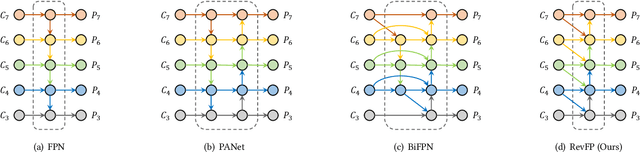
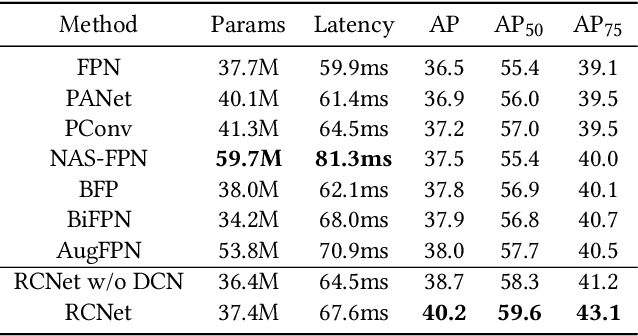
Feature pyramid networks (FPN) are widely exploited for multi-scale feature fusion in existing advanced object detection frameworks. Numerous previous works have developed various structures for bidirectional feature fusion, all of which are shown to improve the detection performance effectively. We observe that these complicated network structures require feature pyramids to be stacked in a fixed order, which introduces longer pipelines and reduces the inference speed. Moreover, semantics from non-adjacent levels are diluted in the feature pyramid since only features at adjacent pyramid levels are merged by the local fusion operation in a sequence manner. To address these issues, we propose a novel architecture named RCNet, which consists of Reverse Feature Pyramid (RevFP) and Cross-scale Shift Network (CSN). RevFP utilizes local bidirectional feature fusion to simplify the bidirectional pyramid inference pipeline. CSN directly propagates representations to both adjacent and non-adjacent levels to enable multi-scale features more correlative. Extensive experiments on the MS COCO dataset demonstrate RCNet can consistently bring significant improvements over both one-stage and two-stage detectors with subtle extra computational overhead. In particular, RetinaNet is boosted to 40.2 AP, which is 3.7 points higher than baseline, by replacing FPN with our proposed model. On COCO test-dev, RCNet can achieve very competitive performance with a single-model single-scale 50.5 AP. Codes will be made available.
RaidaR: A Rich Annotated Image Dataset of Rainy Street Scenes
Apr 09, 2021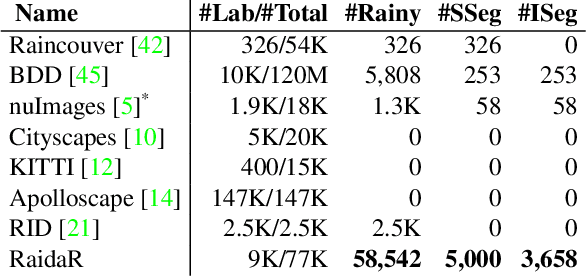

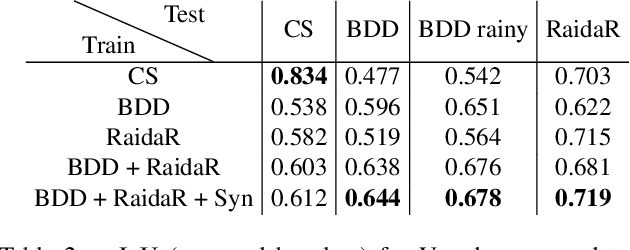

We introduce RaidaR, a rich annotated image dataset of rainy street scenes, to support autonomous driving research. The new dataset contains the largest number of rainy images (58,542) to date, 5,000 of which provide semantic segmentations and 3,658 provide object instance segmentations. The RaidaR images cover a wide range of realistic rain-induced artifacts, including fog, droplets, and road reflections, which can effectively augment existing street scene datasets to improve data-driven machine perception during rainy weather. To facilitate efficient annotation of a large volume of images, we develop a semi-automatic scheme combining manual segmentation and an automated processing akin to cross validation, resulting in 10-20 fold reduction on annotation time. We demonstrate the utility of our new dataset by showing how data augmentation with RaidaR can elevate the accuracy of existing segmentation algorithms. We also present a novel unpaired image-to-image translation algorithm for adding/removing rain artifacts, which directly benefits from RaidaR.
KPNet: Towards Minimal Face Detector
Mar 17, 2020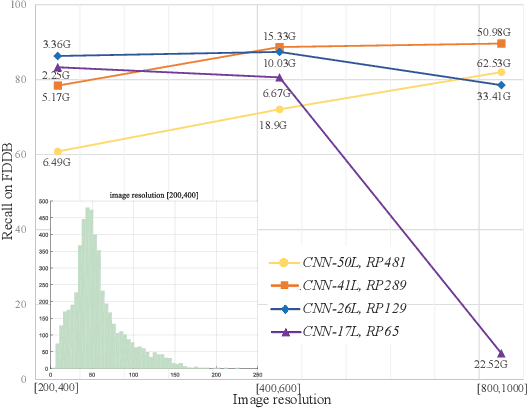

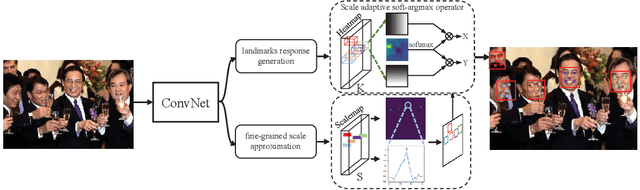
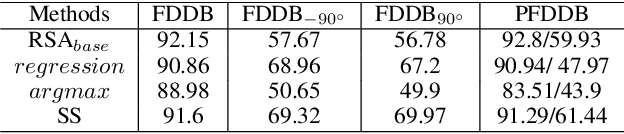
The small receptive field and capacity of minimal neural networks limit their performance when using them to be the backbone of detectors. In this work, we find that the appearance feature of a generic face is discriminative enough for a tiny and shallow neural network to verify from the background. And the essential barriers behind us are 1) the vague definition of the face bounding box and 2) tricky design of anchor-boxes or receptive field. Unlike most top-down methods for joint face detection and alignment, the proposed KPNet detects small facial keypoints instead of the whole face by in a bottom-up manner. It first predicts the facial landmarks from a low-resolution image via the well-designed fine-grained scale approximation and scale adaptive soft-argmax operator. Finally, the precise face bounding boxes, no matter how we define it, can be inferred from the keypoints. Without any complex head architecture or meticulous network designing, the KPNet achieves state-of-the-art accuracy on generic face detection and alignment benchmarks with only $\sim1M$ parameters, which runs at 1000fps on GPU and is easy to perform real-time on most modern front-end chips.
Rethinking Loss Design for Large-scale 3D Shape Retrieval
Jun 03, 2019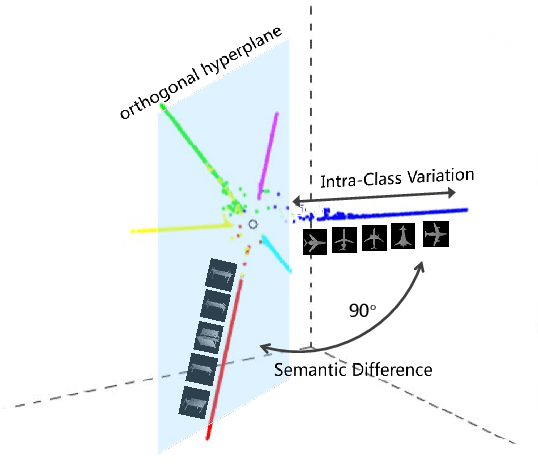
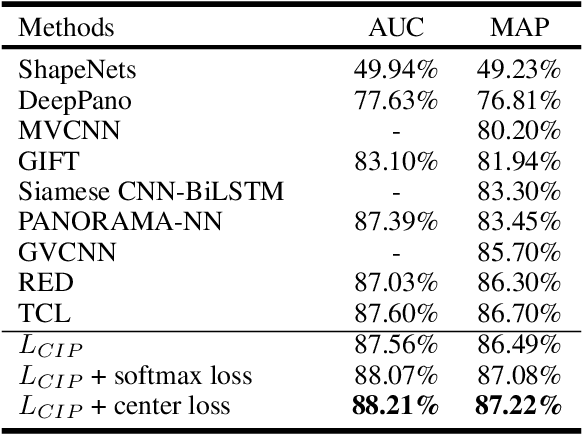
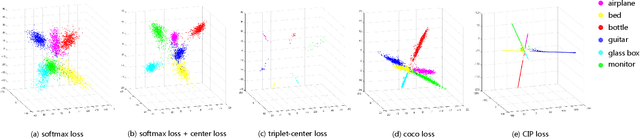
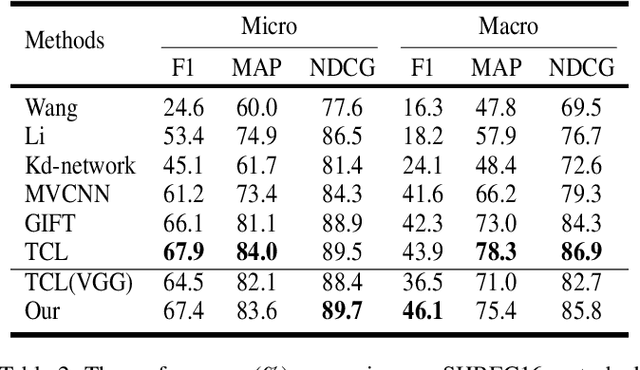
Learning discriminative shape representations is a crucial issue for large-scale 3D shape retrieval. In this paper, we propose the Collaborative Inner Product Loss (CIP Loss) to obtain ideal shape embedding that discriminative among different categories and clustered within the same class. Utilizing simple inner product operation, CIP loss explicitly enforces the features of the same class to be clustered in a linear subspace, while inter-class subspaces are constrained to be at least orthogonal. Compared to previous metric loss functions, CIP loss could provide more clear geometric interpretation for the embedding than Euclidean margin, and is easy to implement without normalization operation referring to cosine margin. Moreover, our proposed loss term can combine with other commonly used loss functions and can be easily plugged into existing off-the-shelf architectures. Extensive experiments conducted on the two public 3D object retrieval datasets, ModelNet and ShapeNetCore 55, demonstrate the effectiveness of our proposal, and our method has achieved state-of-the-art results on both datasets.