 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSlice3D: Multi-Slice, Occlusion-Revealing, Single View 3D Reconstruction
Dec 03, 2023We introduce multi-slice reasoning, a new notion for single-view 3D reconstruction which challenges the current and prevailing belief that multi-view synthesis is the most natural conduit between single-view and 3D. Our key observation is that object slicing is more advantageous than altering views to reveal occluded structures. Specifically, slicing is more occlusion-revealing since it can peel through any occluders without obstruction. In the limit, i.e., with infinitely many slices, it is guaranteed to unveil all hidden object parts. We realize our idea by developing Slice3D, a novel method for single-view 3D reconstruction which first predicts multi-slice images from a single RGB image and then integrates the slices into a 3D model using a coordinate-based transformer network for signed distance prediction. The slice images can be regressed or generated, both through a U-Net based network. For the former, we inject a learnable slice indicator code to designate each decoded image into a spatial slice location, while the slice generator is a denoising diffusion model operating on the entirety of slice images stacked on the input channels. We conduct extensive evaluation against state-of-the-art alternatives to demonstrate superiority of our method, especially in recovering complex and severely occluded shape structures, amid ambiguities. All Slice3D results were produced by networks trained on a single Nvidia A40 GPU, with an inference time less than 20 seconds.
RaidaR: A Rich Annotated Image Dataset of Rainy Street Scenes
Apr 09, 2021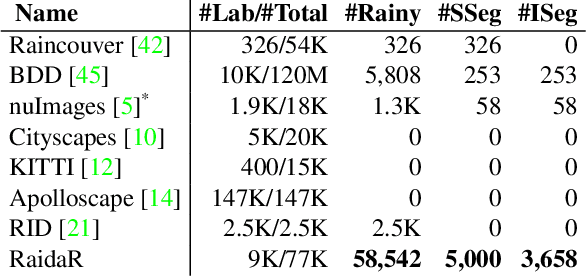

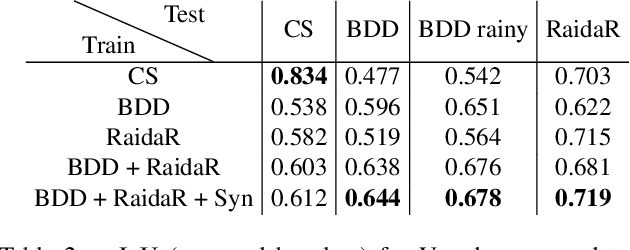

We introduce RaidaR, a rich annotated image dataset of rainy street scenes, to support autonomous driving research. The new dataset contains the largest number of rainy images (58,542) to date, 5,000 of which provide semantic segmentations and 3,658 provide object instance segmentations. The RaidaR images cover a wide range of realistic rain-induced artifacts, including fog, droplets, and road reflections, which can effectively augment existing street scene datasets to improve data-driven machine perception during rainy weather. To facilitate efficient annotation of a large volume of images, we develop a semi-automatic scheme combining manual segmentation and an automated processing akin to cross validation, resulting in 10-20 fold reduction on annotation time. We demonstrate the utility of our new dataset by showing how data augmentation with RaidaR can elevate the accuracy of existing segmentation algorithms. We also present a novel unpaired image-to-image translation algorithm for adding/removing rain artifacts, which directly benefits from RaidaR.
GANHopper: Multi-Hop GAN for Unsupervised Image-to-Image Translation
Feb 29, 2020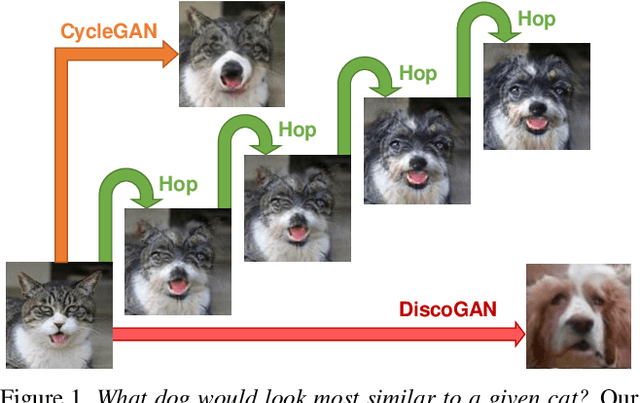
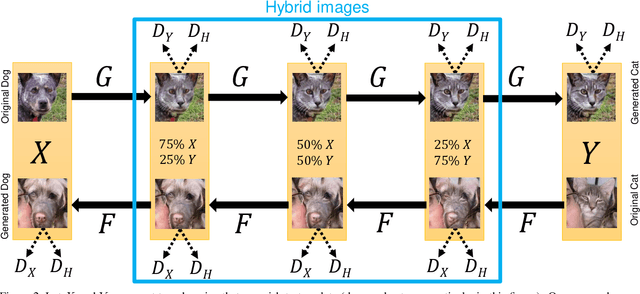
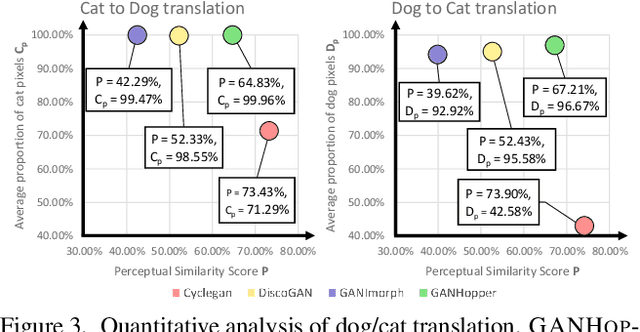
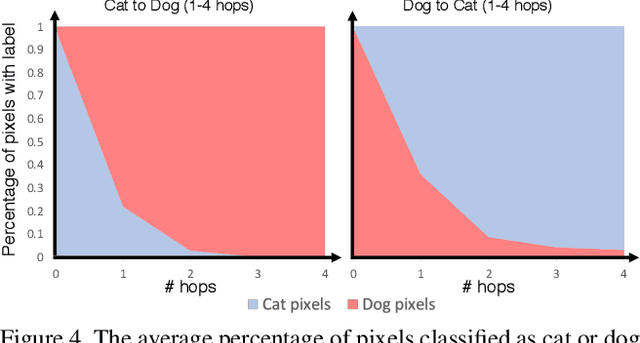
We introduce GANHopper, an unsupervised image-to-image translation network that transforms images gradually between two domains, through multiple hops. Instead of executing translation directly, we steer the translation by requiring the network to produce in-between images which resemble weighted hybrids between images from the two in-put domains. Our network is trained on unpaired images from the two domains only, without any in-between images.All hops are produced using a single generator along each direction. In addition to the standard cycle-consistency and adversarial losses, we introduce a new hybrid discrimina-tor, which is trained to classify the intermediate images produced by the generator as weighted hybrids, with weights based on a predetermined hop count. We also introduce a smoothness term to constrain the magnitude of each hop,further regularizing the translation. Compared to previous methods, GANHopper excels at image translations involving domain-specific image features and geometric variations while also preserving non-domain-specific features such as backgrounds and general color schemes.