 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBabyVLM-V2: Toward Developmentally Grounded Pretraining and Benchmarking of Vision Foundation Models
Dec 11, 2025Early children's developmental trajectories set up a natural goal for sample-efficient pretraining of vision foundation models. We introduce BabyVLM-V2, a developmentally grounded framework for infant-inspired vision-language modeling that extensively improves upon BabyVLM-V1 through a longitudinal, multifaceted pretraining set, a versatile model, and, most importantly, DevCV Toolbox for cognitive evaluation. The pretraining set maximizes coverage while minimizing curation of a longitudinal, infant-centric audiovisual corpus, yielding video-utterance, image-utterance, and multi-turn conversational data that mirror infant experiences. DevCV Toolbox adapts all vision-related measures of the recently released NIH Baby Toolbox into a benchmark suite of ten multimodal tasks, covering spatial reasoning, memory, and vocabulary understanding aligned with early children's capabilities. Experimental results show that a compact model pretrained from scratch can achieve competitive performance on DevCV Toolbox, outperforming GPT-4o on some tasks. We hope the principled, unified BabyVLM-V2 framework will accelerate research in developmentally plausible pretraining of vision foundation models.
AdaCoT: Pareto-Optimal Adaptive Chain-of-Thought Triggering via Reinforcement Learning
May 17, 2025Large Language Models (LLMs) have demonstrated remarkable capabilities but often face challenges with tasks requiring sophisticated reasoning. While Chain-of-Thought (CoT) prompting significantly enhances reasoning, it indiscriminately generates lengthy reasoning steps for all queries, leading to substantial computational costs and inefficiency, especially for simpler inputs. To address this critical issue, we introduce AdaCoT (Adaptive Chain-of-Thought), a novel framework enabling LLMs to adaptively decide when to invoke CoT. AdaCoT framed adaptive reasoning as a Pareto optimization problem that seeks to balance model performance with the costs associated with CoT invocation (both frequency and computational overhead). We propose a reinforcement learning (RL) based method, specifically utilizing Proximal Policy Optimization (PPO), to dynamically control the CoT triggering decision boundary by adjusting penalty coefficients, thereby allowing the model to determine CoT necessity based on implicit query complexity. A key technical contribution is Selective Loss Masking (SLM), designed to counteract decision boundary collapse during multi-stage RL training, ensuring robust and stable adaptive triggering. Experimental results demonstrate that AdaCoT successfully navigates the Pareto frontier, achieving substantial reductions in CoT usage for queries not requiring elaborate reasoning. For instance, on our production traffic testset, AdaCoT reduced CoT triggering rates to as low as 3.18\% and decreased average response tokens by 69.06%, while maintaining high performance on complex tasks.
SITE: towards Spatial Intelligence Thorough Evaluation
May 08, 2025Spatial intelligence (SI) represents a cognitive ability encompassing the visualization, manipulation, and reasoning about spatial relationships, underpinning disciplines from neuroscience to robotics. We introduce SITE, a benchmark dataset towards SI Thorough Evaluation in a standardized format of multi-choice visual question-answering, designed to assess large vision-language models' spatial intelligence across diverse visual modalities (single-image, multi-image, and video) and SI factors (figural to environmental scales, spatial visualization and orientation, intrinsic and extrinsic, static and dynamic). Our approach to curating the benchmark combines a bottom-up survey about 31 existing datasets and a top-down strategy drawing upon three classification systems in cognitive science, which prompt us to design two novel types of tasks about view-taking and dynamic scenes. Extensive experiments reveal that leading models fall behind human experts especially in spatial orientation, a fundamental SI factor. Moreover, we demonstrate a positive correlation between a model's spatial reasoning proficiency and its performance on an embodied AI task.
Wearable Device-Based Physiological Signal Monitoring: An Assessment Study of Cognitive Load Across Tasks
Jun 11, 2024


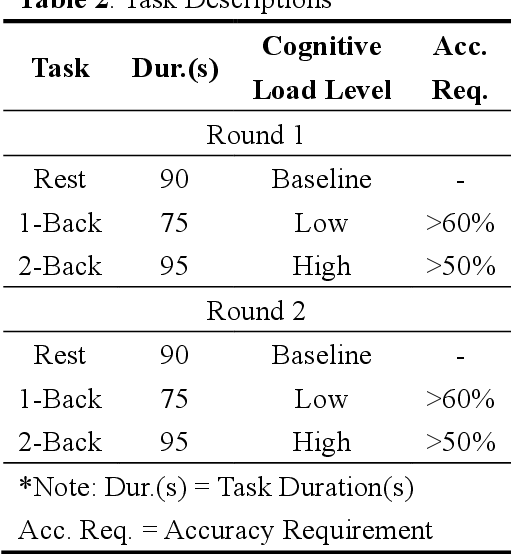
This study employs cutting-edge wearable monitoring technology to conduct high-precision, high-temporal-resolution cognitive load assessment on EEG data from the FP1 channel and heart rate variability (HRV) data of secondary vocational students(SVS). By jointly analyzing these two critical physiological indicators, the research delves into their application value in assessing cognitive load among SVS students and their utility across various tasks. The study designed two experiments to validate the efficacy of the proposed approach: Initially, a random forest classification model, developed using the N-BACK task, enabled the precise decoding of physiological signal characteristics in SVS students under different levels of cognitive load, achieving a classification accuracy of 97%. Subsequently, this classification model was applied in a cross-task experiment involving the National Computer Rank Examination, demonstrating the method's significant applicability and cross-task transferability in diverse learning contexts. Conducted with high portability, this research holds substantial theoretical and practical significance for optimizing teaching resource allocation in secondary vocational education, as well as for cognitive load assessment methods and monitoring. Currently, the research findings are undergoing trial implementation in the school.
Data Assimilation using ERA5, ASOS, and the U-STN model for Weather Forecasting over the UK
Jan 15, 2024In recent years, the convergence of data-driven machine learning models with Data Assimilation (DA) offers a promising avenue for enhancing weather forecasting. This study delves into this emerging trend, presenting our methodologies and outcomes. We harnessed the UK's local ERA5 850 hPa temperature data and refined the U-STN12 global weather forecasting model, tailoring its predictions to the UK's climate nuances. From the ASOS network, we sourced T2m data, representing ground observations across the UK. We employed the advanced kriging method with a polynomial drift term for consistent spatial resolution. Furthermore, Gaussian noise was superimposed on the ERA5 T850 data, setting the stage for ensuing multi-time step synthetic observations. Probing into the assimilation impacts, the ASOS T2m data was integrated with the ERA5 T850 dataset. Our insights reveal that while global forecast models can adapt to specific regions, incorporating atmospheric data in DA significantly bolsters model accuracy. Conversely, the direct assimilation of surface temperature data tends to mitigate this enhancement, tempering the model's predictive prowess.
Slice3D: Multi-Slice, Occlusion-Revealing, Single View 3D Reconstruction
Dec 03, 2023We introduce multi-slice reasoning, a new notion for single-view 3D reconstruction which challenges the current and prevailing belief that multi-view synthesis is the most natural conduit between single-view and 3D. Our key observation is that object slicing is more advantageous than altering views to reveal occluded structures. Specifically, slicing is more occlusion-revealing since it can peel through any occluders without obstruction. In the limit, i.e., with infinitely many slices, it is guaranteed to unveil all hidden object parts. We realize our idea by developing Slice3D, a novel method for single-view 3D reconstruction which first predicts multi-slice images from a single RGB image and then integrates the slices into a 3D model using a coordinate-based transformer network for signed distance prediction. The slice images can be regressed or generated, both through a U-Net based network. For the former, we inject a learnable slice indicator code to designate each decoded image into a spatial slice location, while the slice generator is a denoising diffusion model operating on the entirety of slice images stacked on the input channels. We conduct extensive evaluation against state-of-the-art alternatives to demonstrate superiority of our method, especially in recovering complex and severely occluded shape structures, amid ambiguities. All Slice3D results were produced by networks trained on a single Nvidia A40 GPU, with an inference time less than 20 seconds.
NTIRE 2023 Quality Assessment of Video Enhancement Challenge
Jul 19, 2023



This paper reports on the NTIRE 2023 Quality Assessment of Video Enhancement Challenge, which will be held in conjunction with the New Trends in Image Restoration and Enhancement Workshop (NTIRE) at CVPR 2023. This challenge is to address a major challenge in the field of video processing, namely, video quality assessment (VQA) for enhanced videos. The challenge uses the VQA Dataset for Perceptual Video Enhancement (VDPVE), which has a total of 1211 enhanced videos, including 600 videos with color, brightness, and contrast enhancements, 310 videos with deblurring, and 301 deshaked videos. The challenge has a total of 167 registered participants. 61 participating teams submitted their prediction results during the development phase, with a total of 3168 submissions. A total of 176 submissions were submitted by 37 participating teams during the final testing phase. Finally, 19 participating teams submitted their models and fact sheets, and detailed the methods they used. Some methods have achieved better results than baseline methods, and the winning methods have demonstrated superior prediction performance.
Both Spatial and Frequency Cues Contribute to High-Fidelity Image Inpainting
Jul 15, 2023Deep generative approaches have obtained great success in image inpainting recently. However, most generative inpainting networks suffer from either over-smooth results or aliasing artifacts. The former lacks high-frequency details, while the latter lacks semantic structure. To address this issue, we propose an effective Frequency-Spatial Complementary Network (FSCN) by exploiting rich semantic information in both spatial and frequency domains. Specifically, we introduce an extra Frequency Branch and Frequency Loss on the spatial-based network to impose direct supervision on the frequency information, and propose a Frequency-Spatial Cross-Attention Block (FSCAB) to fuse multi-domain features and combine the corresponding characteristics. With our FSCAB, the inpainting network is capable of capturing frequency information and preserving visual consistency simultaneously. Extensive quantitative and qualitative experiments demonstrate that our inpainting network can effectively achieve superior results, outperforming previous state-of-the-art approaches with significantly fewer parameters and less computation cost. The code will be released soon.
Graph-Driven Generative Models for Heterogeneous Multi-Task Learning
Nov 20, 2019


We propose a novel graph-driven generative model, that unifies multiple heterogeneous learning tasks into the same framework. The proposed model is based on the fact that heterogeneous learning tasks, which correspond to different generative processes, often rely on data with a shared graph structure. Accordingly, our model combines a graph convolutional network (GCN) with multiple variational autoencoders, thus embedding the nodes of the graph i.e., samples for the tasks) in a uniform manner while specializing their organization and usage to different tasks. With a focus on healthcare applications (tasks), including clinical topic modeling, procedure recommendation and admission-type prediction, we demonstrate that our method successfully leverages information across different tasks, boosting performance in all tasks and outperforming existing state-of-the-art approaches.
Collaborative Filtering with A Synthetic Feedback Loop
Oct 21, 2019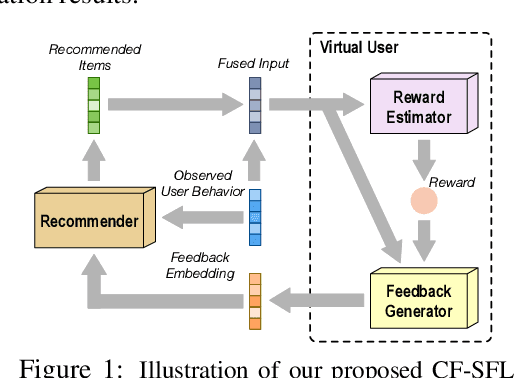
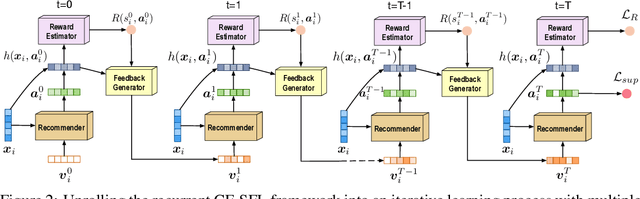

We propose a novel learning framework for recommendation systems, assisting collaborative filtering with a synthetic feedback loop. The proposed framework consists of a "recommender" and a "virtual user." The recommender is formulizd as a collaborative-filtering method, recommending items according to observed user behavior. The virtual user estimates rewards from the recommended items and generates the influence of the rewards on observed user behavior. The recommender connected with the virtual user constructs a closed loop, that recommends users with items and imitates the unobserved feedback of the users to the recommended items. The synthetic feedback is used to augment observed user behavior and improve recommendation results. Such a model can be interpreted as the inverse reinforcement learning, which can be learned effectively via rollout (simulation). Experimental results show that the proposed framework is able to boost the performance of existing collaborative filtering methods on multiple datasets.