 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOffload or Overload: A Platform Measurement Study of Mobile Robotic Manipulation Workloads
Mar 18, 2026Mobile robotic manipulation--the ability of robots to navigate spaces and interact with objects--is a core capability of physical AI. Foundation models have led to breakthroughs in their performance, but at a significant computational cost. We present the first measurement study of mobile robotic manipulation workloads across onboard, edge, and cloud GPU platforms. We find that the full workload stack is infeasible to run on smaller onboard GPUs, while larger onboard GPUs drain robot batteries several hours faster. Offloading alleviates these constraints but introduces its own challenges, as additional network latency degrades task accuracy, and the bandwidth requirement makes naive cloud offloading impractical. Finally, we quantify opportunities and pitfalls of sharing compute across robot fleets. We believe our measurement study will be crucial to designing inference systems for mobile robots.
Emergent Dexterity via Diverse Resets and Large-Scale Reinforcement Learning
Mar 16, 2026Reinforcement learning in massively parallel physics simulations has driven major progress in sim-to-real robot learning. However, current approaches remain brittle and task-specific, relying on extensive per-task engineering to design rewards, curricula, and demonstrations. Even with this engineering, they often fail on long-horizon, contact-rich manipulation tasks and do not meaningfully scale with compute, as performance quickly saturates when training revisits the same narrow regions of state space. We introduce \Method, a simple and scalable framework that enables on-policy reinforcement learning to robustly solve a broad class of dexterous manipulation tasks using a single reward function, fixed algorithm hyperparameters, no curricula, and no human demonstrations. Our key insight is that long-horizon exploration can be dramatically simplified by using simulator resets to systematically expose the RL algorithm to the diverse set of robot-object interactions which underlie dexterous manipulation. \Method\ programmatically generates such resets with minimal human input, converting additional compute directly into broader behavioral coverage and continued performance gains. We show that \Method\ gracefully scales to long-horizon dexterous manipulation tasks beyond the capabilities of existing approaches and is able to learn robust policies over significantly wider ranges of initial conditions than baselines. Finally, we distill \Method \ into visuomotor policies which display robust retrying behavior and substantially higher success rates than baselines when transferred to the real world zero-shot. Project webpage: https://omnireset.github.io
Latent Policy Steering through One-Step Flow Policies
Mar 05, 2026Offline reinforcement learning (RL) allows robots to learn from offline datasets without risky exploration. Yet, offline RL's performance often hinges on a brittle trade-off between (1) return maximization, which can push policies outside the dataset support, and (2) behavioral constraints, which typically require sensitive hyperparameter tuning. Latent steering offers a structural way to stay within the dataset support during RL, but existing offline adaptations commonly approximate action values using latent-space critics learned via indirect distillation, which can lose information and hinder convergence. We propose Latent Policy Steering (LPS), which enables high-fidelity latent policy improvement by backpropagating original-action-space Q-gradients through a differentiable one-step MeanFlow policy to update a latent-action-space actor. By eliminating proxy latent critics, LPS allows an original-action-space critic to guide end-to-end latent-space optimization, while the one-step MeanFlow policy serves as a behavior-constrained generative prior. This decoupling yields a robust method that works out-of-the-box with minimal tuning. Across OGBench and real-world robotic tasks, LPS achieves state-of-the-art performance and consistently outperforms behavioral cloning and strong latent steering baselines.
Benchmarking Affordance Generalization with BusyBox
Feb 05, 2026Vision-Language-Action (VLA) models have been attracting the attention of researchers and practitioners thanks to their promise of generalization. Although single-task policies still offer competitive performance, VLAs are increasingly able to handle commands and environments unseen in their training set. While generalization in vision and language space is undoubtedly important for robust versatile behaviors, a key meta-skill VLAs need to possess is affordance generalization -- the ability to manipulate new objects with familiar physical features. In this work, we present BusyBox, a physical benchmark for systematic semi-automatic evaluation of VLAs' affordance generalization. BusyBox consists of 6 modules with switches, sliders, wires, buttons, a display, and a dial. The modules can be swapped and rotated to create a multitude of BusyBox variations with different visual appearances but the same set of affordances. We empirically demonstrate that generalization across BusyBox variants is highly challenging even for strong open-weights VLAs such as $π_{0.5}$ and GR00T-N1.6. To encourage the research community to evaluate their own VLAs on BusyBox and to propose new affordance generalization experiments, we have designed BusyBox to be easy to build in most robotics labs. We release the full set of CAD files for 3D-printing its parts as well as a bill of materials for (optionally) assembling its electronics. We also publish a dataset of language-annotated demonstrations that we collected using the common bimanual Mobile Aloha robot on the canonical BusyBox configuration. All of the released materials are available at https://microsoft.github.io/BusyBox.
LoLA: Long Horizon Latent Action Learning for General Robot Manipulation
Dec 23, 2025The capability of performing long-horizon, language-guided robotic manipulation tasks critically relies on leveraging historical information and generating coherent action sequences. However, such capabilities are often overlooked by existing Vision-Language-Action (VLA) models. To solve this challenge, we propose LoLA (Long Horizon Latent Action Learning), a framework designed for robot manipulation that integrates long-term multi-view observations and robot proprioception to enable multi-step reasoning and action generation. We first employ Vision-Language Models to encode rich contextual features from historical sequences and multi-view observations. We further introduces a key module, State-Aware Latent Re-representation, which transforms visual inputs and language commands into actionable robot motion space. Unlike existing VLA approaches that merely concatenate robot proprioception (e.g., joint angles) with VL embeddings, this module leverages such robot states to explicitly ground VL representations in physical scale through a learnable "embodiment-anchored" latent space. We trained LoLA on diverse robotic pre-training datasets and conducted extensive evaluations on simulation benchmarks (SIMPLER and LIBERO), as well as two real-world tasks on Franka and Bi-Manual Aloha robots. Results show that LoLA significantly outperforms prior state-of-the-art methods (e.g., pi0), particularly in long-horizon manipulation tasks.
TwinVLA: Data-Efficient Bimanual Manipulation with Twin Single-Arm Vision-Language-Action Models
Nov 07, 2025Vision-language-action models (VLAs) trained on large-scale robotic datasets have demonstrated strong performance on manipulation tasks, including bimanual tasks. However, because most public datasets focus on single-arm demonstrations, adapting VLAs for bimanual tasks typically requires substantial additional bimanual data and fine-tuning. To address this challenge, we introduce TwinVLA, a modular framework that composes two copies of a pretrained single-arm VLA into a coordinated bimanual VLA. Unlike monolithic cross-embodiment models trained on mixtures of single-arm and bimanual data, TwinVLA improves both data efficiency and performance by composing pretrained single-arm policies. Across diverse bimanual tasks in real-world and simulation settings, TwinVLA outperforms a comparably-sized monolithic RDT-1B model without requiring any bimanual pretraining. Furthermore, it narrows the gap to state-of-the-art model, $π_0$ which rely on extensive proprietary bimanual data and compute cost. These results establish our modular composition approach as a data-efficient and scalable path toward high-performance bimanual manipulation, leveraging public single-arm data.
SITE: towards Spatial Intelligence Thorough Evaluation
May 08, 2025Spatial intelligence (SI) represents a cognitive ability encompassing the visualization, manipulation, and reasoning about spatial relationships, underpinning disciplines from neuroscience to robotics. We introduce SITE, a benchmark dataset towards SI Thorough Evaluation in a standardized format of multi-choice visual question-answering, designed to assess large vision-language models' spatial intelligence across diverse visual modalities (single-image, multi-image, and video) and SI factors (figural to environmental scales, spatial visualization and orientation, intrinsic and extrinsic, static and dynamic). Our approach to curating the benchmark combines a bottom-up survey about 31 existing datasets and a top-down strategy drawing upon three classification systems in cognitive science, which prompt us to design two novel types of tasks about view-taking and dynamic scenes. Extensive experiments reveal that leading models fall behind human experts especially in spatial orientation, a fundamental SI factor. Moreover, we demonstrate a positive correlation between a model's spatial reasoning proficiency and its performance on an embodied AI task.
TraceVLA: Visual Trace Prompting Enhances Spatial-Temporal Awareness for Generalist Robotic Policies
Dec 13, 2024Although large vision-language-action (VLA) models pretrained on extensive robot datasets offer promising generalist policies for robotic learning, they still struggle with spatial-temporal dynamics in interactive robotics, making them less effective in handling complex tasks, such as manipulation. In this work, we introduce visual trace prompting, a simple yet effective approach to facilitate VLA models' spatial-temporal awareness for action prediction by encoding state-action trajectories visually. We develop a new TraceVLA model by finetuning OpenVLA on our own collected dataset of 150K robot manipulation trajectories using visual trace prompting. Evaluations of TraceVLA across 137 configurations in SimplerEnv and 4 tasks on a physical WidowX robot demonstrate state-of-the-art performance, outperforming OpenVLA by 10% on SimplerEnv and 3.5x on real-robot tasks and exhibiting robust generalization across diverse embodiments and scenarios. To further validate the effectiveness and generality of our method, we present a compact VLA model based on 4B Phi-3-Vision, pretrained on the Open-X-Embodiment and finetuned on our dataset, rivals the 7B OpenVLA baseline while significantly improving inference efficiency.
The Importance of Directional Feedback for LLM-based Optimizers
May 26, 2024



We study the potential of using large language models (LLMs) as an interactive optimizer for solving maximization problems in a text space using natural language and numerical feedback. Inspired by the classical optimization literature, we classify the natural language feedback into directional and non-directional, where the former is a generalization of the first-order feedback to the natural language space. We find that LLMs are especially capable of optimization when they are provided with {directional feedback}. Based on this insight, we design a new LLM-based optimizer that synthesizes directional feedback from the historical optimization trace to achieve reliable improvement over iterations. Empirically, we show our LLM-based optimizer is more stable and efficient in solving optimization problems, from maximizing mathematical functions to optimizing prompts for writing poems, compared with existing techniques.
PRISE: Learning Temporal Action Abstractions as a Sequence Compression Problem
Feb 16, 2024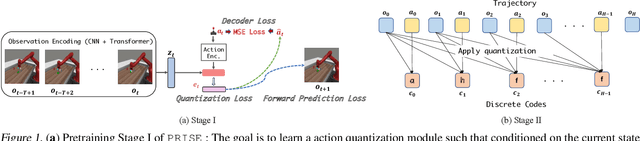



Temporal action abstractions, along with belief state representations, are a powerful knowledge sharing mechanism for sequential decision making. In this work, we propose a novel view that treats inducing temporal action abstractions as a sequence compression problem. To do so, we bring a subtle but critical component of LLM training pipelines -- input tokenization via byte pair encoding (BPE) -- to the seemingly distant task of learning skills of variable time span in continuous control domains. We introduce an approach called Primitive Sequence Encoding (PRISE) that combines continuous action quantization with BPE to learn powerful action abstractions. We empirically show that high-level skills discovered by PRISE from a multitask set of robotic manipulation demonstrations significantly boost the performance of both multitask imitation learning as well as few-shot imitation learning on unseen tasks. Our code will be released at https://github.com/FrankZheng2022/PRISE.