 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning with Latent Tokens in Diffusion Language Models
Feb 03, 2026Discrete diffusion models have recently become competitive with autoregressive models for language modeling, even outperforming them on reasoning tasks requiring planning and global coherence, but they require more computation at inference time. We trace this trade-off to a key mechanism: diffusion models are trained to jointly predict a distribution over all unknown tokens, including those that will not actually be decoded in the current step. Ablating this joint prediction yields faster inference but degrades performance, revealing that accurate prediction at the decoded position relies on joint reasoning about the distribution of undecoded tokens. We interpret these as latent tokens and introduce a method for modulating their number, demonstrating empirically that this enables a smooth tradeoff between inference speed and sample quality. Furthermore, we demonstrate that latent tokens can be introduced into autoregressive models through an auxiliary multi-token prediction objective, yielding substantial improvements on the same reasoning tasks where they have traditionally struggled. Our results suggest that latent tokens, while arising naturally in diffusion, represent a general mechanism for improving performance on tasks requiring global coherence or lookahead.
BridgeData V2: A Dataset for Robot Learning at Scale
Aug 24, 2023We introduce BridgeData V2, a large and diverse dataset of robotic manipulation behaviors designed to facilitate research on scalable robot learning. BridgeData V2 contains 60,096 trajectories collected across 24 environments on a publicly available low-cost robot. BridgeData V2 provides extensive task and environment variability, leading to skills that can generalize across environments, domains, and institutions, making the dataset a useful resource for a broad range of researchers. Additionally, the dataset is compatible with a wide variety of open-vocabulary, multi-task learning methods conditioned on goal images or natural language instructions. In our experiments, we train 6 state-of-the-art imitation learning and offline reinforcement learning methods on our dataset, and find that they succeed on a suite of tasks requiring varying amounts of generalization. We also demonstrate that the performance of these methods improves with more data and higher capacity models, and that training on a greater variety of skills leads to improved generalization. By publicly sharing BridgeData V2 and our pre-trained models, we aim to accelerate research in scalable robot learning methods. Project page at https://rail-berkeley.github.io/bridgedata
Goal Representations for Instruction Following: A Semi-Supervised Language Interface to Control
Jun 30, 2023



Our goal is for robots to follow natural language instructions like "put the towel next to the microwave." But getting large amounts of labeled data, i.e. data that contains demonstrations of tasks labeled with the language instruction, is prohibitive. In contrast, obtaining policies that respond to image goals is much easier, because any autonomous trial or demonstration can be labeled in hindsight with its final state as the goal. In this work, we contribute a method that taps into joint image- and goal- conditioned policies with language using only a small amount of language data. Prior work has made progress on this using vision-language models or by jointly training language-goal-conditioned policies, but so far neither method has scaled effectively to real-world robot tasks without significant human annotation. Our method achieves robust performance in the real world by learning an embedding from the labeled data that aligns language not to the goal image, but rather to the desired change between the start and goal images that the instruction corresponds to. We then train a policy on this embedding: the policy benefits from all the unlabeled data, but the aligned embedding provides an interface for language to steer the policy. We show instruction following across a variety of manipulation tasks in different scenes, with generalization to language instructions outside of the labeled data. Videos and code for our approach can be found on our website: http://tiny.cc/grif .
Neural Unsupervised Reconstruction of Protolanguage Word Forms
Nov 16, 2022



We present a state-of-the-art neural approach to the unsupervised reconstruction of ancient word forms. Previous work in this domain used expectation-maximization to predict simple phonological changes between ancient word forms and their cognates in modern languages. We extend this work with neural models that can capture more complicated phonological and morphological changes. At the same time, we preserve the inductive biases from classical methods by building monotonic alignment constraints into the model and deliberately underfitting during the maximization step. We evaluate our performance on the task of reconstructing Latin from a dataset of cognates across five Romance languages, achieving a notable reduction in edit distance from the target word forms compared to previous methods.
Understanding Game-Playing Agents with Natural Language Annotations
Apr 15, 2022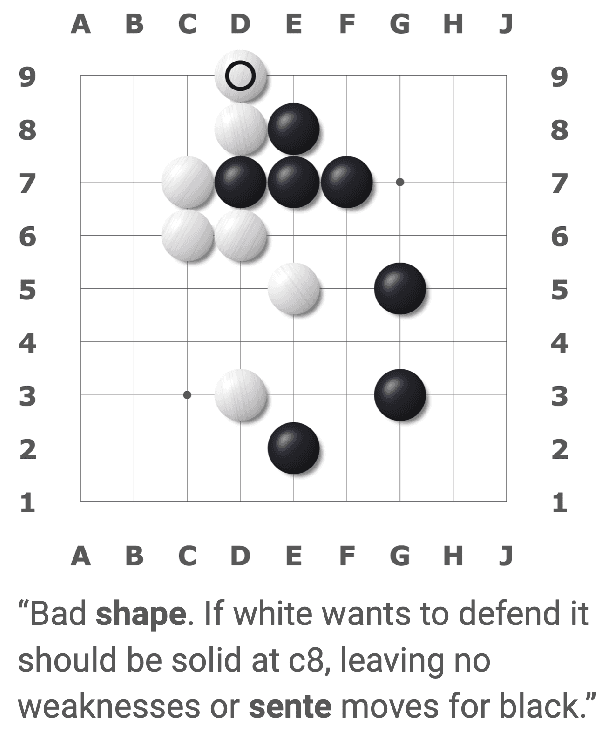
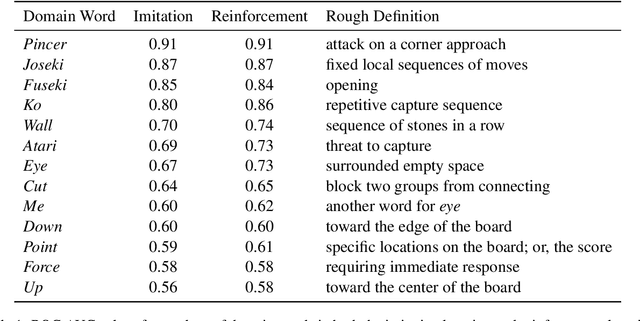
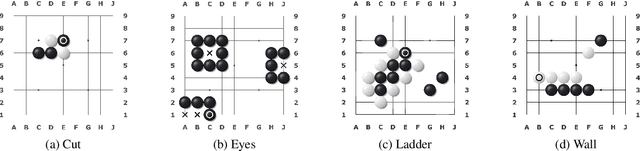
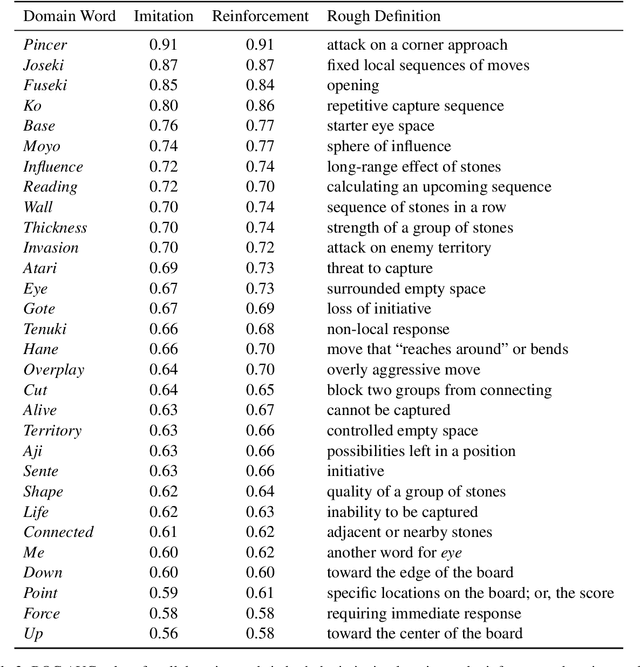
We present a new dataset containing 10K human-annotated games of Go and show how these natural language annotations can be used as a tool for model interpretability. Given a board state and its associated comment, our approach uses linear probing to predict mentions of domain-specific terms (e.g., ko, atari) from the intermediate state representations of game-playing agents like AlphaGo Zero. We find these game concepts are nontrivially encoded in two distinct policy networks, one trained via imitation learning and another trained via reinforcement learning. Furthermore, mentions of domain-specific terms are most easily predicted from the later layers of both models, suggesting that these policy networks encode high-level abstractions similar to those used in the natural language annotations.