 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimulating Human Memory with Language Models
May 25, 2026Language models are increasingly being deployed as user simulators, but their memory is far more reliable than that of real users. To measure this gap, we run a series of classic memory experiments from psychology on both humans and language models. Across tasks, we find that out-of-the-box language models exhibit better memory than humans, even when prompted to imitate human behavior. We then show that better prompting strategies and the use of a compactor can cause language models to forget content in a more human-like way. Using these methods, we show preliminary evidence that language models with human-like memory constraints can function as more effective user simulators in a downstream education task. Finally, we release human reference data and benchmarks to support future work on simulating human memory with language models.
Calibrate-Then-Act: Cost-Aware Exploration in LLM Agents
Feb 19, 2026LLMs are increasingly being used for complex problems which are not necessarily resolved in a single response, but require interacting with an environment to acquire information. In these scenarios, LLMs must reason about inherent cost-uncertainty tradeoffs in when to stop exploring and commit to an answer. For instance, on a programming task, an LLM should test a generated code snippet if it is uncertain about the correctness of that code; the cost of writing a test is nonzero, but typically lower than the cost of making a mistake. In this work, we show that we can induce LLMs to explicitly reason about balancing these cost-uncertainty tradeoffs, then perform more optimal environment exploration. We formalize multiple tasks, including information retrieval and coding, as sequential decision-making problems under uncertainty. Each problem has latent environment state that can be reasoned about via a prior which is passed to the LLM agent. We introduce a framework called Calibrate-Then-Act (CTA), where we feed the LLM this additional context to enable it to act more optimally. This improvement is preserved even under RL training of both the baseline and CTA. Our results on information-seeking QA and on a simplified coding task show that making cost-benefit tradeoffs explicit with CTA can help agents discover more optimal decision-making strategies.
Measuring General Intelligence with Generated Games
May 12, 2025We present gg-bench, a collection of game environments designed to evaluate general reasoning capabilities in language models. Unlike most static benchmarks, gg-bench is a data generating process where new evaluation instances can be generated at will. In particular, gg-bench is synthetically generated by (1) using a large language model (LLM) to generate natural language descriptions of novel games, (2) using the LLM to implement each game in code as a Gym environment, and (3) training reinforcement learning (RL) agents via self-play on the generated games. We evaluate language models by their winrate against these RL agents by prompting models with the game description, current board state, and a list of valid moves, after which models output the moves they wish to take. gg-bench is challenging: state-of-the-art LLMs such as GPT-4o and Claude 3.7 Sonnet achieve winrates of 7-9% on gg-bench using in-context learning, while reasoning models such as o1, o3-mini and DeepSeek-R1 achieve average winrates of 31-36%. We release the generated games, data generation process, and evaluation code in order to support future modeling work and expansion of our benchmark.
Efficacy of Language Model Self-Play in Non-Zero-Sum Games
Jun 27, 2024Game-playing agents like AlphaGo have achieved superhuman performance through self-play, which is theoretically guaranteed to yield optimal policies in competitive games. However, most language tasks are partially or fully cooperative, so it is an open question whether techniques like self-play can effectively be used to improve language models. We empirically investigate this question in a negotiation game setting known as Deal or No Deal (DoND). Crucially, the objective in DoND can be modified to produce a fully cooperative game, a strictly competitive one, or anything in between. We finetune language models in self-play over multiple rounds of filtered behavior cloning in DoND for each of these objectives. Contrary to expectations, we find that language model self-play leads to significant performance gains in both cooperation and competition with humans, suggesting that self-play and related techniques have promise despite a lack of theoretical guarantees.
Autonomous Evaluation and Refinement of Digital Agents
Apr 10, 2024We show that domain-general automatic evaluators can significantly improve the performance of agents for web navigation and device control. We experiment with multiple evaluation models that trade off between inference cost, modularity of design, and accuracy. We validate the performance of these models in several popular benchmarks for digital agents, finding between 74.4 and 92.9% agreement with oracle evaluation metrics. Finally, we use these evaluators to improve the performance of existing agents via fine-tuning and inference-time guidance. Without any additional supervision, we improve state-of-the-art performance by 29% on the popular benchmark WebArena, and achieve a 75% relative improvement in a challenging domain transfer scenario.
Decision-Oriented Dialogue for Human-AI Collaboration
Jun 01, 2023We describe a class of tasks called decision-oriented dialogues, in which AI assistants must collaborate with one or more humans via natural language to help them make complex decisions. We formalize three domains in which users face everyday decisions: (1) choosing an assignment of reviewers to conference papers, (2) planning a multi-step itinerary in a city, and (3) negotiating travel plans for a group of friends. In each of these settings, AI assistants and users have disparate abilities that they must combine to arrive at the best decision: assistants can access and process large amounts of information, while users have preferences and constraints external to the system. For each task, we build a dialogue environment where agents receive a reward based on the quality of the final decision they reach. Using these environments, we collect human-human dialogues with humans playing the role of assistant. To compare how current AI assistants communicate in these settings, we present baselines using large language models in self-play. Finally, we highlight a number of challenges models face in decision-oriented dialogues, ranging from efficient communication to reasoning and optimization, and release our environments as a testbed for future modeling work.
Ghostbuster: Detecting Text Ghostwritten by Large Language Models
May 24, 2023


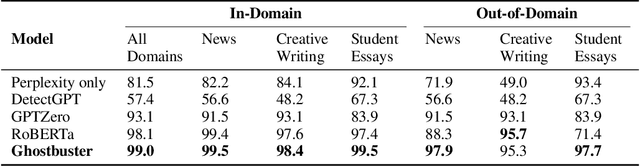
We introduce Ghostbuster, a state-of-the-art system for detecting AI-generated text. Our method works by passing documents through a series of weaker language models and running a structured search over possible combinations of their features, then training a classifier on the selected features to determine if the target document was AI-generated. Crucially, Ghostbuster does not require access to token probabilities from the target model, making it useful for detecting text generated by black-box models or unknown model versions. In conjunction with our model, we release three new datasets of human and AI-generated text as detection benchmarks that cover multiple domains (student essays, creative fiction, and news) and task setups: document-level detection, author identification, and a challenge task of paragraph-level detection. Ghostbuster averages 99.1 F1 across all three datasets on document-level detection, outperforming previous approaches such as GPTZero and DetectGPT by up to 32.7 F1.
Revisiting Entropy Rate Constancy in Text
May 20, 2023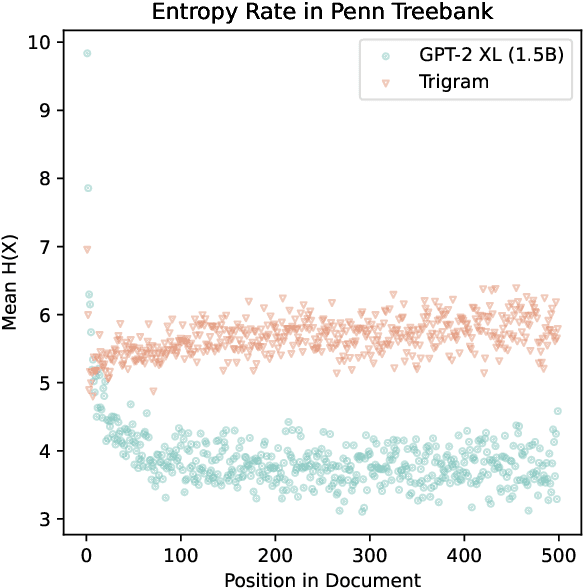



The uniform information density (UID) hypothesis states that humans tend to distribute information roughly evenly across an utterance or discourse. Early evidence in support of the UID hypothesis came from Genzel & Charniak (2002), which proposed an entropy rate constancy principle based on the probability of English text under n-gram language models. We re-evaluate the claims of Genzel & Charniak (2002) with neural language models, failing to find clear evidence in support of entropy rate constancy. We conduct a range of experiments across datasets, model sizes, and languages and discuss implications for the uniform information density hypothesis and linguistic theories of efficient communication more broadly.
Neural Unsupervised Reconstruction of Protolanguage Word Forms
Nov 16, 2022



We present a state-of-the-art neural approach to the unsupervised reconstruction of ancient word forms. Previous work in this domain used expectation-maximization to predict simple phonological changes between ancient word forms and their cognates in modern languages. We extend this work with neural models that can capture more complicated phonological and morphological changes. At the same time, we preserve the inductive biases from classical methods by building monotonic alignment constraints into the model and deliberately underfitting during the maximization step. We evaluate our performance on the task of reconstructing Latin from a dataset of cognates across five Romance languages, achieving a notable reduction in edit distance from the target word forms compared to previous methods.
Pragmatics in Grounded Language Learning: Phenomena, Tasks, and Modeling Approaches
Nov 15, 2022People rely heavily on context to enrich meaning beyond what is literally said, enabling concise but effective communication. To interact successfully and naturally with people, user-facing artificial intelligence systems will require similar skills in pragmatics: relying on various types of context -- from shared linguistic goals and conventions, to the visual and embodied world -- to use language effectively. We survey existing grounded settings and pragmatic modeling approaches and analyze how the task goals, environmental contexts, and communicative affordances in each work enrich linguistic meaning. We present recommendations for future grounded task design to naturally elicit pragmatic phenomena, and suggest directions that focus on a broader range of communicative contexts and affordances.