 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeErgodic Exploration over Meshable Surfaces
Mar 06, 2025



Robotic search and rescue, exploration, and inspection require trajectory planning across a variety of domains. A popular approach to trajectory planning for these types of missions is ergodic search, which biases a trajectory to spend time in parts of the exploration domain that are believed to contain more information. Most prior work on ergodic search has been limited to searching simple surfaces, like a 2D Euclidean plane or a sphere, as they rely on projecting functions defined on the exploration domain onto analytically obtained Fourier basis functions. In this paper, we extend ergodic search to any surface that can be approximated by a triangle mesh. The basis functions are approximated through finite element methods on a triangle mesh of the domain. We formally prove that this approximation converges to the continuous case as the mesh approximation converges to the true domain. We demonstrate that on domains where analytical basis functions are available (plane, sphere), the proposed method obtains equivalent results, and while on other domains (torus, bunny, wind turbine), the approach is versatile enough to still search effectively. Lastly, we also compare with an existing ergodic search technique that can handle complex domains and show that our method results in a higher quality exploration.
Measure Preserving Flows for Ergodic Search in Convoluted Environments
Sep 13, 2024



Autonomous robotic search has important applications in robotics, such as the search for signs of life after a disaster. When \emph{a priori} information is available, for example in the form of a distribution, a planner can use that distribution to guide the search. Ergodic search is one method that uses the information distribution to generate a trajectory that minimizes the ergodic metric, in that it encourages the robot to spend more time in regions with high information and proportionally less time in the remaining regions. Unfortunately, prior works in ergodic search do not perform well in complex environments with obstacles such as a building's interior or a maze. To address this, our work presents a modified ergodic metric using the Laplace-Beltrami eigenfunctions to capture map geometry and obstacle locations within the ergodic metric. Further, we introduce an approach to generate trajectories that minimize the ergodic metric while guaranteeing obstacle avoidance using measure-preserving vector fields. Finally, we leverage the divergence-free nature of these vector fields to generate collision-free trajectories for multiple agents. We demonstrate our approach via simulations with single and multi-agent systems on maps representing interior hallways and long corridors with non-uniform information distribution. In particular, we illustrate the generation of feasible trajectories in complex environments where prior methods fail.
Estimating Large Language Model Capabilities without Labeled Test Data
May 24, 2023
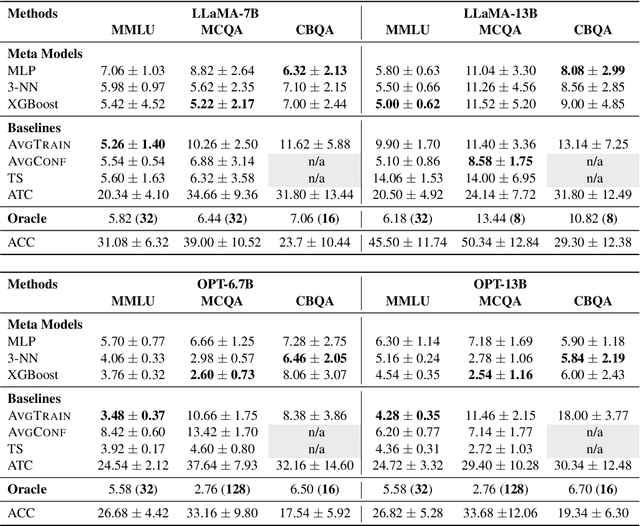
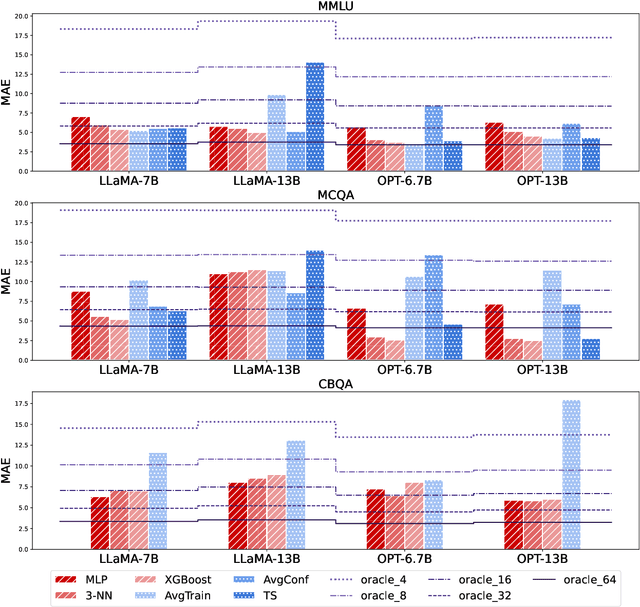
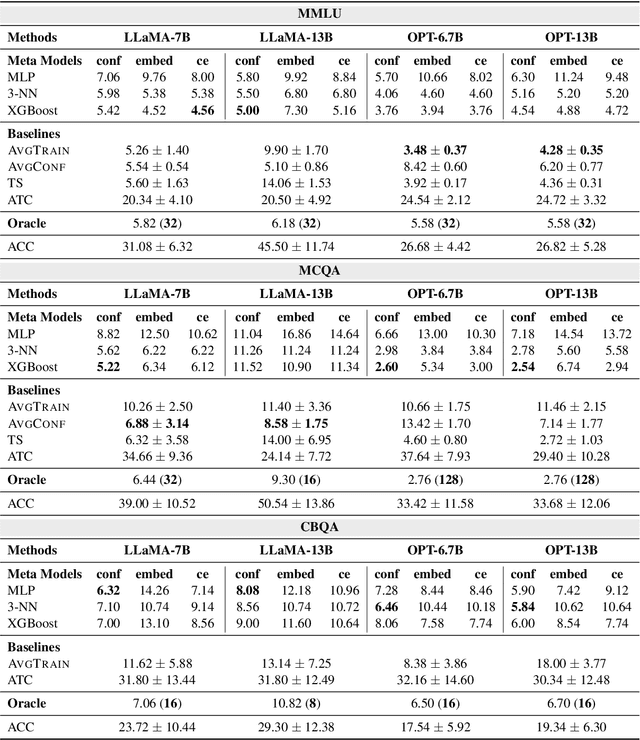
Large Language Models (LLMs) have exhibited an impressive ability to perform in-context learning (ICL) from only a few examples, but the success of ICL varies widely from task to task. Thus, it is important to quickly determine whether ICL is applicable to a new task, but directly evaluating ICL accuracy can be expensive in situations where test data is expensive to annotate -- the exact situations where ICL is most appealing. In this paper, we propose the task of ICL accuracy estimation, in which we predict the accuracy of an LLM when doing in-context learning on a new task given only unlabeled data for that task. To perform ICL accuracy estimation, we propose a method that trains a meta-model using LLM confidence scores as features. We compare our method to several strong accuracy estimation baselines on a new benchmark that covers 4 LLMs and 3 task collections. On average, the meta-model improves over all baselines and achieves the same estimation performance as directly evaluating on 40 labeled test examples per task, across the total 12 settings. We encourage future work to improve on our methods and evaluate on our ICL accuracy estimation benchmark to deepen our understanding of when ICL works.
CoNAL: Anticipating Outliers with Large Language Models
Nov 28, 2022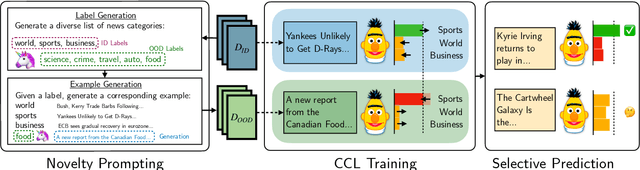
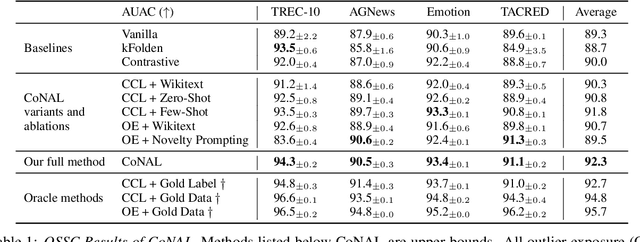

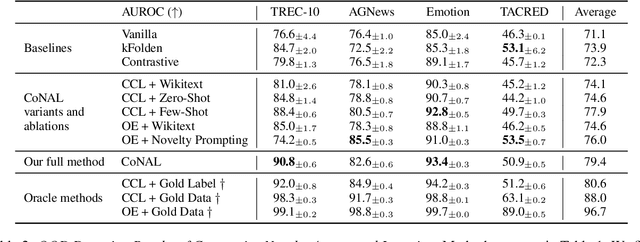
In many task settings, text classification models are likely to encounter examples from novel classes on which they cannot predict correctly. Selective prediction, in which models abstain on low-confidence examples, provides a possible solution, but existing models are often overly confident on OOD examples. To remedy this overconfidence, we introduce Contrastive Novelty-Augmented Learning (CoNAL), a two-step method that generates OOD examples representative of novel classes, then trains to decrease confidence on them. First, we generate OOD examples by prompting a large language model twice: we prompt it to enumerate relevant novel labels, then generate examples from each novel class matching the task format. Second, we train our classifier with a novel contrastive objective that encourages lower confidence on generated OOD examples than training examples. When trained with CoNAL, classifiers improve in their ability to detect and abstain on OOD examples over prior methods by an average of 2.3% AUAC and 5.5% AUROC across 4 NLP datasets, with no cost to in-distribution accuracy.
Mathematical Justification of Hard Negative Mining via Isometric Approximation Theorem
Oct 20, 2022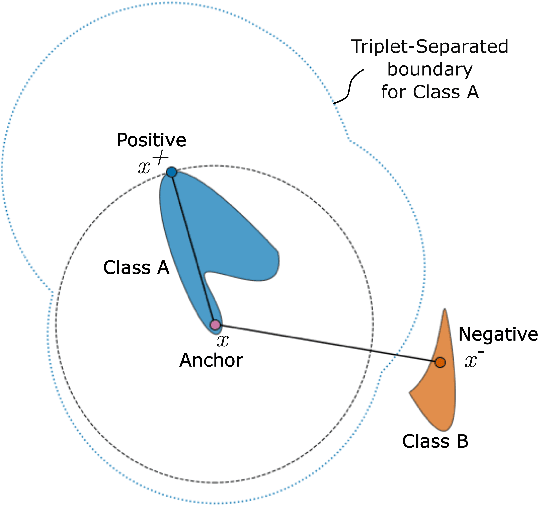
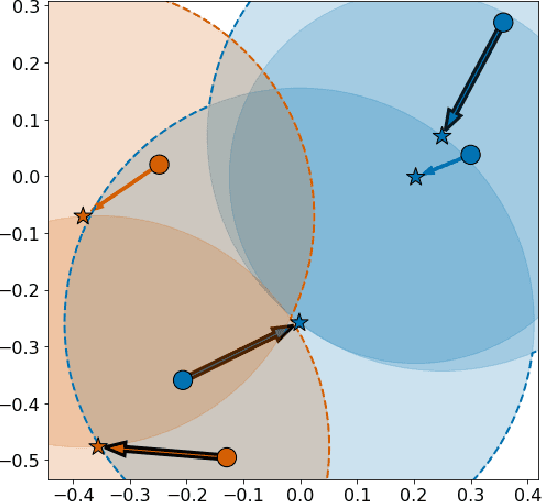
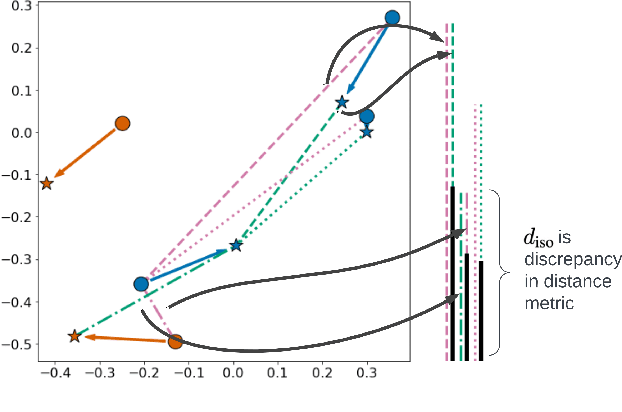
In deep metric learning, the Triplet Loss has emerged as a popular method to learn many computer vision and natural language processing tasks such as facial recognition, object detection, and visual-semantic embeddings. One issue that plagues the Triplet Loss is network collapse, an undesirable phenomenon where the network projects the embeddings of all data onto a single point. Researchers predominately solve this problem by using triplet mining strategies. While hard negative mining is the most effective of these strategies, existing formulations lack strong theoretical justification for their empirical success. In this paper, we utilize the mathematical theory of isometric approximation to show an equivalence between the Triplet Loss sampled by hard negative mining and an optimization problem that minimizes a Hausdorff-like distance between the neural network and its ideal counterpart function. This provides the theoretical justifications for hard negative mining's empirical efficacy. In addition, our novel application of the isometric approximation theorem provides the groundwork for future forms of hard negative mining that avoid network collapse. Our theory can also be extended to analyze other Euclidean space-based metric learning methods like Ladder Loss or Contrastive Learning.
Automated Crossword Solving
May 19, 2022
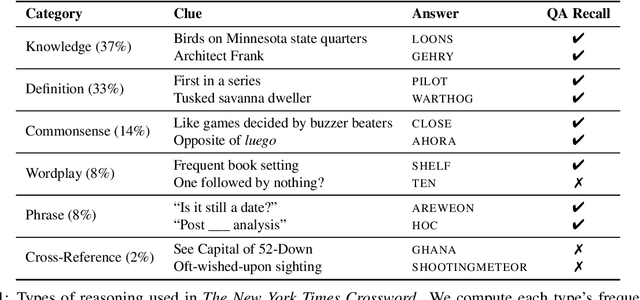
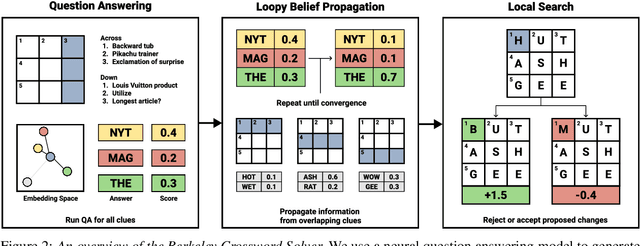
We present the Berkeley Crossword Solver, a state-of-the-art approach for automatically solving crossword puzzles. Our system works by generating answer candidates for each crossword clue using neural question answering models and then combines loopy belief propagation with local search to find full puzzle solutions. Compared to existing approaches, our system improves exact puzzle accuracy from 57% to 82% on crosswords from The New York Times and obtains 99.9% letter accuracy on themeless puzzles. Our system also won first place at the top human crossword tournament, which marks the first time that a computer program has surpassed human performance at this event. To facilitate research on question answering and crossword solving, we analyze our system's remaining errors and release a dataset of over six million question-answer pairs.
Detoxifying Language Models Risks Marginalizing Minority Voices
Apr 13, 2021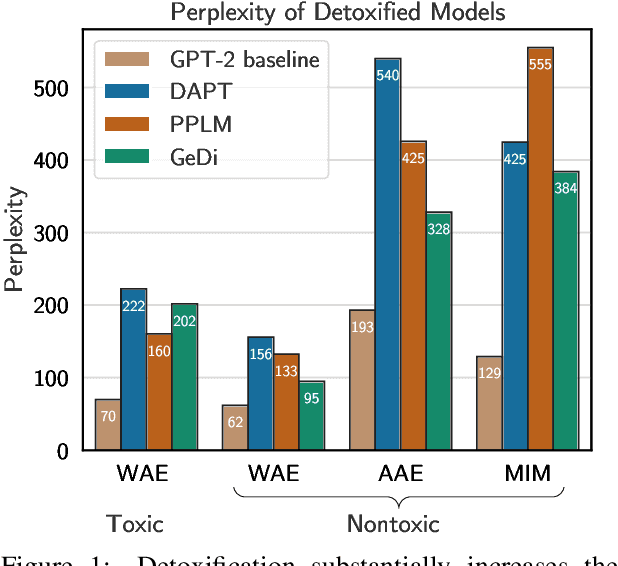



Language models (LMs) must be both safe and equitable to be responsibly deployed in practice. With safety in mind, numerous detoxification techniques (e.g., Dathathri et al. 2020; Krause et al. 2020) have been proposed to mitigate toxic LM generations. In this work, we show that current detoxification techniques hurt equity: they decrease the utility of LMs on language used by marginalized groups (e.g., African-American English and minority identity mentions). In particular, we perform automatic and human evaluations of text generation quality when LMs are conditioned on inputs with different dialects and group identifiers. We find that detoxification makes LMs more brittle to distribution shift, especially on language used by marginalized groups. We identify that these failures stem from detoxification methods exploiting spurious correlations in toxicity datasets. Overall, our results highlight the tension between the controllability and distributional robustness of LMs.