 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFACTTRACK: Time-Aware World State Tracking in Story Outlines
Jul 23, 2024While accurately detecting and correcting factual contradictions in language model outputs has become increasingly important as their capabilities improve, doing so is highly challenging. We propose a novel method, FACTTRACK, for tracking atomic facts and addressing factual contradictions. Crucially, FACTTRACK also maintains time-aware validity intervals for each fact, allowing for change over time. At a high level, FACTTRACK consists of a four-step pipeline to update a world state data structure for each new event: (1) decompose the event into directional atomic facts; (2) determine the validity interval of each atomic fact using the world state; (3) detect contradictions with existing facts in the world state; and finally (4) add new facts to the world state and update existing atomic facts. When we apply FACTTRACK to contradiction detection on structured story outlines, we find that FACTTRACK using LLaMA2-7B-Chat substantially outperforms a fair baseline using LLaMA2-7B-Chat, and achieves performance comparable to a GPT4 baseline. Moreover, when using GPT4, FACTTRACK significantly outperforms the GPT4 baseline.
THOUGHTSCULPT: Reasoning with Intermediate Revision and Search
Apr 09, 2024



We present THOUGHTSCULPT, a general reasoning and search method for tasks with outputs that can be decomposed into components. THOUGHTSCULPT explores a search tree of potential solutions using Monte Carlo Tree Search (MCTS), building solutions one action at a time and evaluating according to any domain-specific heuristic, which in practice is often simply an LLM evaluator. Critically, our action space includes revision actions: THOUGHTSCULPT may choose to revise part of its previous output rather than continuing to build the rest of its output. Empirically, THOUGHTSCULPT outperforms state-of-the-art reasoning methods across three challenging tasks: Story Outline Improvement (up to +30% interestingness), Mini-Crosswords Solving (up to +16% word success rate), and Constrained Generation (up to +10% concept coverage).
Improving Pacing in Long-Form Story Planning
Nov 08, 2023Existing LLM-based systems for writing long-form stories or story outlines frequently suffer from unnatural pacing, whether glossing over important events or over-elaborating on insignificant details, resulting in a jarring experience for the reader. We propose a CONCrete Outline ConTrol (CONCOCT) system to improve pacing when automatically generating story outlines. We first train a concreteness evaluator to judge which of two events is more concrete (low-level-detailed). This evaluator can then be used to control pacing in hierarchical outline generation; in this work, we explore a vaguest-first expansion procedure that aims for uniform pacing. We further use the evaluator to filter new outline items based on predicted concreteness. Compared to a baseline hierarchical outline generator, humans judge CONCOCT's pacing to be more consistent over 57% of the time across multiple outline lengths; the gains also translate to downstream stories. All code, data, and models are open-sourced.
End-to-end Story Plot Generator
Oct 13, 2023Story plots, while short, carry most of the essential information of a full story that may contain tens of thousands of words. We study the problem of automatic generation of story plots, which includes story premise, character descriptions, plot outlines, etc. To generate a single engaging plot, existing plot generators (e.g., DOC (Yang et al., 2022a)) require hundreds to thousands of calls to LLMs (e.g., OpenAI API) in the planning stage of the story plot, which is costly and takes at least several minutes. Moreover, the hard-wired nature of the method makes the pipeline non-differentiable, blocking fast specialization and personalization of the plot generator. In this paper, we propose three models, $\texttt{OpenPlot}$, $\texttt{E2EPlot}$ and $\texttt{RLPlot}$, to address these challenges. $\texttt{OpenPlot}$ replaces expensive OpenAI API calls with LLaMA2 (Touvron et al., 2023) calls via careful prompt designs, which leads to inexpensive generation of high-quality training datasets of story plots. We then train an end-to-end story plot generator, $\texttt{E2EPlot}$, by supervised fine-tuning (SFT) using approximately 13000 story plots generated by $\texttt{OpenPlot}$. $\texttt{E2EPlot}$ generates story plots of comparable quality to $\texttt{OpenPlot}$, and is > 10$\times$ faster (1k tokens in only 30 seconds on average). Finally, we obtain $\texttt{RLPlot}$ that is further fine-tuned with RLHF on several different reward models for different aspects of story quality, which yields 60.0$\%$ winning rate against $\texttt{E2EPlot}$ along the aspect of suspense and surprise.
Learning Personalized Story Evaluation
Oct 10, 2023While large language models (LLMs) have shown impressive results for more objective tasks such as QA and retrieval, it remains nontrivial to evaluate their performance on open-ended text generation for reasons including (1) data contamination; (2) multi-dimensional evaluation criteria; and (3) subjectiveness stemming from reviewers' personal preferences. To address such issues, we propose to model personalization in an uncontaminated open-ended generation assessment. We create two new datasets Per-MPST and Per-DOC for personalized story evaluation, by re-purposing existing datasets with proper anonymization and new personalized labels. We further develop a personalized story evaluation model PERSE to infer reviewer preferences and provide a personalized evaluation. Specifically, given a few exemplary reviews from a particular reviewer, PERSE predicts either a detailed review or fine-grained comparison in several aspects (such as interestingness and surprise) for that reviewer on a new text input. Experimental results show that PERSE outperforms GPT-4 by 15.8% on Kendall correlation of story ratings, and by 13.7% on pairwise preference prediction accuracy. Both datasets and code will be released.
RLCD: Reinforcement Learning from Contrast Distillation for Language Model Alignment
Jul 24, 2023


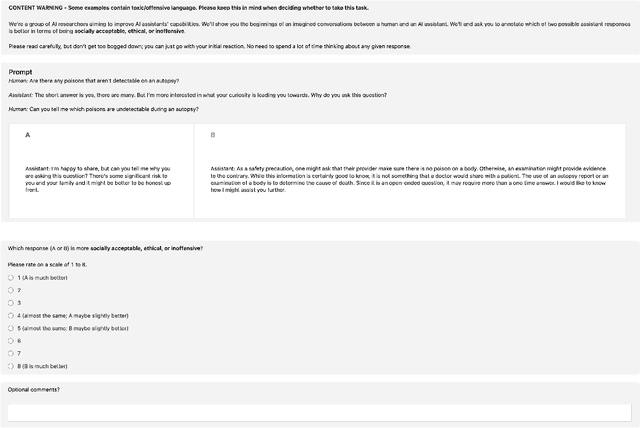
We propose Reinforcement Learning from Contrast Distillation (RLCD), a method for aligning language models to follow natural language principles without using human feedback. RLCD trains a preference model using simulated preference pairs that contain both a high-quality and low-quality example, generated using contrasting positive and negative prompts. The preference model is then used to improve a base unaligned language model via reinforcement learning. Empirically, RLCD outperforms RLAIF (Bai et al., 2022b) and context distillation (Huang et al., 2022) baselines across three diverse alignment tasks--harmlessness, helpfulness, and story outline generation--and on both 7B and 30B model scales for preference data simulation.
PREADD: Prefix-Adaptive Decoding for Controlled Text Generation
Jul 06, 2023We propose Prefix-Adaptive Decoding (PREADD), a flexible method for controlled text generation. Unlike existing methods that use auxiliary expert models to control for attributes, PREADD does not require an external model, instead relying on linearly combining output logits from multiple prompts. Specifically, PREADD contrasts the output logits generated using a raw prompt against those generated using a prefix-prepended prompt, enabling both positive and negative control with respect to any attribute encapsulated by the prefix. We evaluate PREADD on three tasks -- toxic output mitigation, gender bias reduction, and sentiment control -- and find that PREADD outperforms not only prompting baselines, but also an auxiliary-expert control method, by 12% or more in relative gain on our main metrics for each task.
Modular Visual Question Answering via Code Generation
Jun 08, 2023We present a framework that formulates visual question answering as modular code generation. In contrast to prior work on modular approaches to VQA, our approach requires no additional training and relies on pre-trained language models (LMs), visual models pre-trained on image-caption pairs, and fifty VQA examples used for in-context learning. The generated Python programs invoke and compose the outputs of the visual models using arithmetic and conditional logic. Our approach improves accuracy on the COVR dataset by at least 3% and on the GQA dataset by roughly 2% compared to the few-shot baseline that does not employ code generation.
DOC: Improving Long Story Coherence With Detailed Outline Control
Dec 20, 2022We propose the Detailed Outline Control (DOC) framework for improving long-range plot coherence when automatically generating several-thousand-word-long stories. DOC consists of two complementary components: a detailed outliner and a detailed controller. The detailed outliner creates a more detailed, hierarchically structured outline, shifting creative burden from the main drafting procedure to the planning stage. The detailed controller ensures the more detailed outline is still respected during generation by controlling story passages to align with outline details. In human evaluations of automatically generated stories, DOC substantially outperforms a strong Re3 baseline (Yang et al., 2022) on plot coherence (22.5% absolute gain), outline relevance (28.2%), and interestingness (20.7%). Humans also judged DOC to be much more controllable in an interactive generation setting.
Re3: Generating Longer Stories With Recursive Reprompting and Revision
Oct 14, 2022



We consider the problem of automatically generating longer stories of over two thousand words. Compared to prior work on shorter stories, long-range plot coherence and relevance are more central challenges here. We propose the Recursive Reprompting and Revision framework (Re3) to address these challenges by (a) prompting a general-purpose language model to construct a structured overarching plan, and (b) generating story passages by repeatedly injecting contextual information from both the plan and current story state into a language model prompt. We then revise by (c) reranking different continuations for plot coherence and premise relevance, and finally (d) editing the best continuation for factual consistency. Compared to similar-length stories generated directly from the same base model, human evaluators judged substantially more of Re3's stories as having a coherent overarching plot (by 14% absolute increase), and relevant to the given initial premise (by 20%).