 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReuse your FLOPs: Scaling RL on Hard Problems by Conditioning on Very Off-Policy Prefixes
Jan 26, 2026Typical reinforcement learning (RL) methods for LLM reasoning waste compute on hard problems, where correct on-policy traces are rare, policy gradients vanish, and learning stalls. To bootstrap more efficient RL, we consider reusing old sampling FLOPs (from prior inference or RL training) in the form of off-policy traces. Standard off-policy methods supervise against off-policy data, causing instabilities during RL optimization. We introduce PrefixRL, where we condition on the prefix of successful off-policy traces and run on-policy RL to complete them, side-stepping off-policy instabilities. PrefixRL boosts the learning signal on hard problems by modulating the difficulty of the problem through the off-policy prefix length. We prove that the PrefixRL objective is not only consistent with the standard RL objective but also more sample efficient. Empirically, we discover back-generalization: training only on prefixed problems generalizes to out-of-distribution unprefixed performance, with learned strategies often differing from those in the prefix. In our experiments, we source the off-policy traces by rejection sampling with the base model, creating a self-improvement loop. On hard reasoning problems, PrefixRL reaches the same training reward 2x faster than the strongest baseline (SFT on off-policy data then RL), even after accounting for the compute spent on the initial rejection sampling, and increases the final reward by 3x. The gains transfer to held-out benchmarks, and PrefixRL is still effective when off-policy traces are derived from a different model family, validating its flexibility in practical settings.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
PrefPalette: Personalized Preference Modeling with Latent Attributes
Jul 17, 2025



Personalizing AI systems requires understanding not just what users prefer, but the reasons that underlie those preferences - yet current preference models typically treat human judgment as a black box. We introduce PrefPalette, a framework that decomposes preferences into attribute dimensions and tailors its preference prediction to distinct social community values in a human-interpretable manner. PrefPalette operationalizes a cognitive science principle known as multi-attribute decision making in two ways: (1) a scalable counterfactual attribute synthesis step that involves generating synthetic training data to isolate for individual attribute effects (e.g., formality, humor, cultural values), and (2) attention-based preference modeling that learns how different social communities dynamically weight these attributes. This approach moves beyond aggregate preference modeling to capture the diverse evaluation frameworks that drive human judgment. When evaluated on 45 social communities from the online platform Reddit, PrefPalette outperforms GPT-4o by 46.6% in average prediction accuracy. Beyond raw predictive improvements, PrefPalette also shed light on intuitive, community-specific profiles: scholarly communities prioritize verbosity and stimulation, conflict-oriented communities value sarcasm and directness, and support-based communities emphasize empathy. By modeling the attribute-mediated structure of human judgment, PrefPalette delivers both superior preference modeling and transparent, interpretable insights, and serves as a first step toward more trustworthy, value-aware personalized applications.
reWordBench: Benchmarking and Improving the Robustness of Reward Models with Transformed Inputs
Mar 14, 2025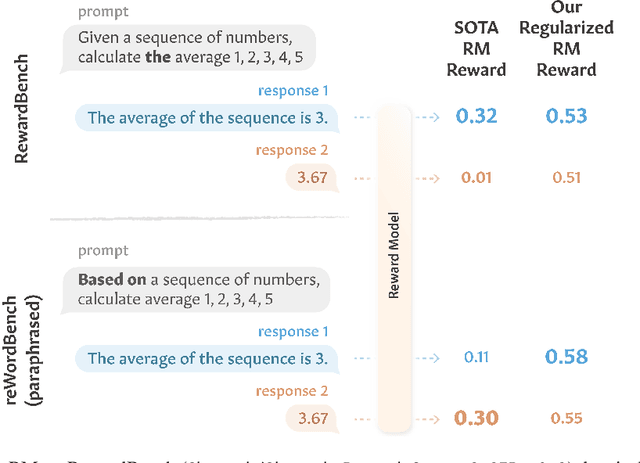


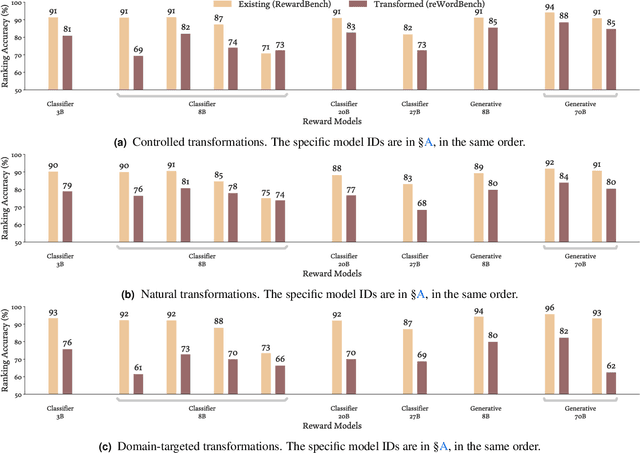
Reward models have become a staple in modern NLP, serving as not only a scalable text evaluator, but also an indispensable component in many alignment recipes and inference-time algorithms. However, while recent reward models increase performance on standard benchmarks, this may partly be due to overfitting effects, which would confound an understanding of their true capability. In this work, we scrutinize the robustness of reward models and the extent of such overfitting. We build **reWordBench**, which systematically transforms reward model inputs in meaning- or ranking-preserving ways. We show that state-of-the-art reward models suffer from substantial performance degradation even with minor input transformations, sometimes dropping to significantly below-random accuracy, suggesting brittleness. To improve reward model robustness, we propose to explicitly train them to assign similar scores to paraphrases, and find that this approach also improves robustness to other distinct kinds of transformations. For example, our robust reward model reduces such degradation by roughly half for the Chat Hard subset in RewardBench. Furthermore, when used in alignment, our robust reward models demonstrate better utility and lead to higher-quality outputs, winning in up to 59% of instances against a standardly trained RM.
LLM Pretraining with Continuous Concepts
Feb 12, 2025



Next token prediction has been the standard training objective used in large language model pretraining. Representations are learned as a result of optimizing for token-level perplexity. We propose Continuous Concept Mixing (CoCoMix), a novel pretraining framework that combines discrete next token prediction with continuous concepts. Specifically, CoCoMix predicts continuous concepts learned from a pretrained sparse autoencoder and mixes them into the model's hidden state by interleaving with token hidden representations. Through experiments on multiple benchmarks, including language modeling and downstream reasoning tasks, we show that CoCoMix is more sample efficient and consistently outperforms standard next token prediction, knowledge distillation and inserting pause tokens. We find that combining both concept learning and interleaving in an end-to-end framework is critical to performance gains. Furthermore, CoCoMix enhances interpretability and steerability by allowing direct inspection and modification of the predicted concept, offering a transparent way to guide the model's internal reasoning process.
Spectral Journey: How Transformers Predict the Shortest Path
Feb 12, 2025Decoder-only transformers lead to a step-change in capability of large language models. However, opinions are mixed as to whether they are really planning or reasoning. A path to making progress in this direction is to study the model's behavior in a setting with carefully controlled data. Then interpret the learned representations and reverse-engineer the computation performed internally. We study decoder-only transformer language models trained from scratch to predict shortest paths on simple, connected and undirected graphs. In this setting, the representations and the dynamics learned by the model are interpretable. We present three major results: (1) Two-layer decoder-only language models can learn to predict shortest paths on simple, connected graphs containing up to 10 nodes. (2) Models learn a graph embedding that is correlated with the spectral decomposition of the line graph. (3) Following the insights, we discover a novel approximate path-finding algorithm Spectral Line Navigator (SLN) that finds shortest path by greedily selecting nodes in the space of spectral embedding of the line graph.
ALMA: Alignment with Minimal Annotation
Dec 05, 2024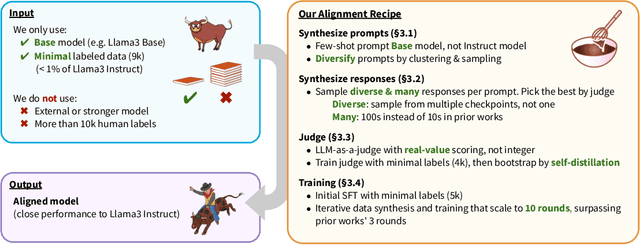
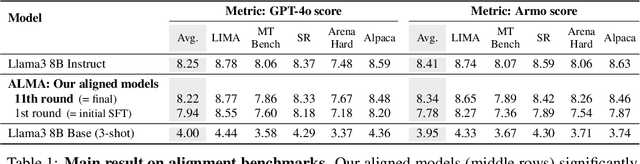
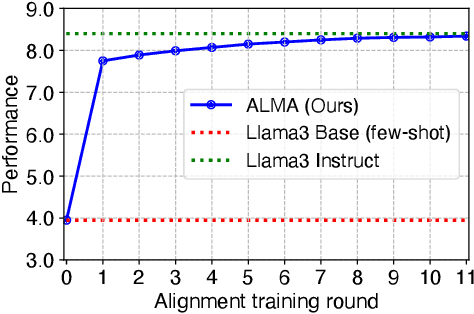

Recent approaches to large language model (LLM) alignment typically require millions of human annotations or rely on external aligned models for synthetic data generation. This paper introduces ALMA: Alignment with Minimal Annotation, demonstrating that effective alignment can be achieved using only 9,000 labeled examples -- less than 1% of conventional approaches. ALMA generates large amounts of high-quality synthetic alignment data through new techniques: diverse prompt synthesis via few-shot learning, diverse response generation with multiple model checkpoints, and judge (reward model) enhancement through score aggregation and self-distillation. Using only a pretrained Llama3 base model, 5,000 SFT examples, and 4,000 judge annotations, ALMA achieves performance close to Llama3-Instruct across diverse alignment benchmarks (e.g., 0.1% difference on AlpacaEval 2.0 score). These results are achieved with a multi-round, self-bootstrapped data synthesis and training recipe that continues to improve for 10 rounds, surpassing the typical 3-round ceiling of previous methods. These results suggest that base models already possess sufficient knowledge for effective alignment, and that synthetic data generation methods can expose it.
Towards Full Delegation: Designing Ideal Agentic Behaviors for Travel Planning
Nov 21, 2024



How are LLM-based agents used in the future? While many of the existing work on agents has focused on improving the performance of a specific family of objective and challenging tasks, in this work, we take a different perspective by thinking about full delegation: agents take over humans' routine decision-making processes and are trusted by humans to find solutions that fit people's personalized needs and are adaptive to ever-changing context. In order to achieve such a goal, the behavior of the agents, i.e., agentic behaviors, should be evaluated not only on their achievements (i.e., outcome evaluation), but also how they achieved that (i.e., procedure evaluation). For this, we propose APEC Agent Constitution, a list of criteria that an agent should follow for good agentic behaviors, including Accuracy, Proactivity, Efficiency and Credibility. To verify whether APEC aligns with human preferences, we develop APEC-Travel, a travel planning agent that proactively extracts hidden personalized needs via multi-round dialog with travelers. APEC-Travel is constructed purely from synthetic data generated by Llama3.1-405B-Instruct with a diverse set of travelers' persona to simulate rich distribution of dialogs. Iteratively fine-tuned to follow APEC Agent Constitution, APEC-Travel surpasses baselines by 20.7% on rule-based metrics and 9.1% on LLM-as-a-Judge scores across the constitution axes.
To the Globe (TTG): Towards Language-Driven Guaranteed Travel Planning
Oct 21, 2024
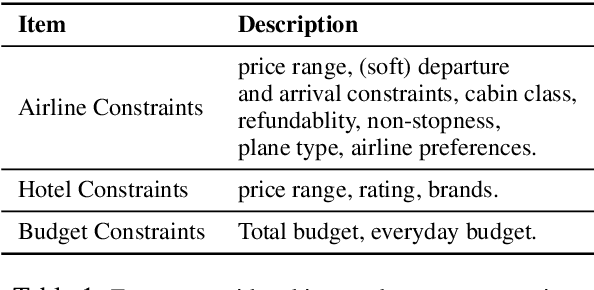
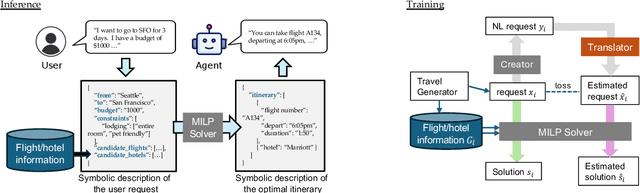

Travel planning is a challenging and time-consuming task that aims to find an itinerary which satisfies multiple, interdependent constraints regarding flights, accommodations, attractions, and other travel arrangements. In this paper, we propose To the Globe (TTG), a real-time demo system that takes natural language requests from users, translates it to symbolic form via a fine-tuned Large Language Model, and produces optimal travel itineraries with Mixed Integer Linear Programming solvers. The overall system takes ~5 seconds to reply to the user request with guaranteed itineraries. To train TTG, we develop a synthetic data pipeline that generates user requests, flight and hotel information in symbolic form without human annotations, based on the statistics of real-world datasets, and fine-tune an LLM to translate NL user requests to their symbolic form, which is sent to the symbolic solver to compute optimal itineraries. Our NL-symbolic translation achieves ~91% exact match in a backtranslation metric (i.e., whether the estimated symbolic form of generated natural language matches the groundtruth), and its returned itineraries have a ratio of 0.979 compared to the optimal cost of the ground truth user request. When evaluated by users, TTG achieves consistently high Net Promoter Scores (NPS) of 35-40% on generated itinerary.
The ART of LLM Refinement: Ask, Refine, and Trust
Nov 14, 2023

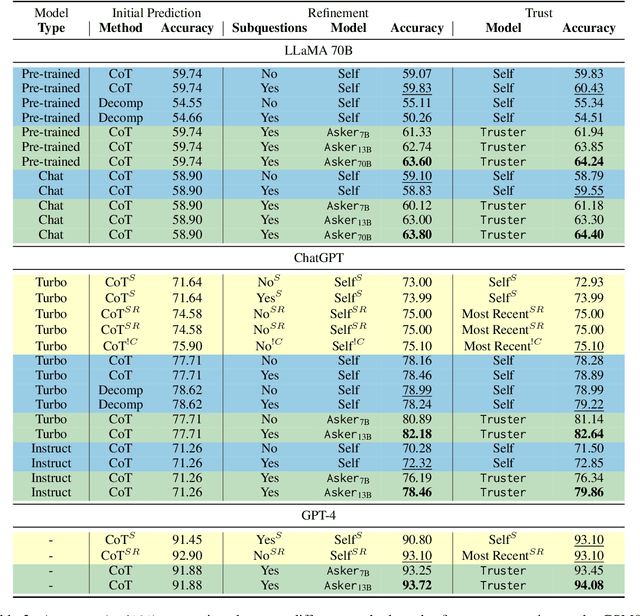

In recent years, Large Language Models (LLMs) have demonstrated remarkable generative abilities, but can they judge the quality of their own generations? A popular concept, referred to as self-refinement, postulates that LLMs can detect and correct the errors in their generations when asked to do so. However, recent empirical evidence points in the opposite direction, suggesting that LLMs often struggle to accurately identify errors when reasoning is involved. To address this, we propose a reasoning with refinement objective called ART: Ask, Refine, and Trust, which asks necessary questions to decide when an LLM should refine its output, and either affirm or withhold trust in its refinement by ranking the refinement and the initial prediction. On two multistep reasoning tasks of mathematical word problems (GSM8K) and question answering (StrategyQA), ART achieves a performance gain of +5 points over self-refinement baselines, while using a much smaller model as the decision maker. We also demonstrate the benefit of using smaller models to make refinement decisions as a cost-effective alternative to fine-tuning a larger model.