 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALMA: Alignment with Minimal Annotation
Dec 05, 2024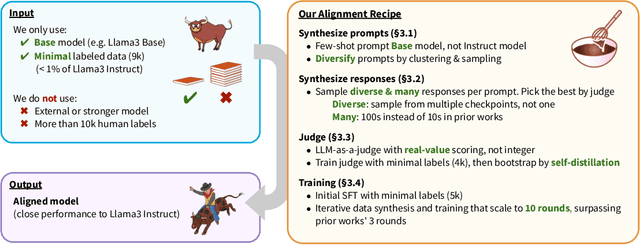
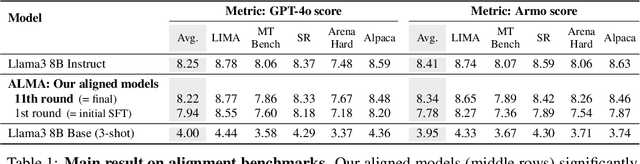
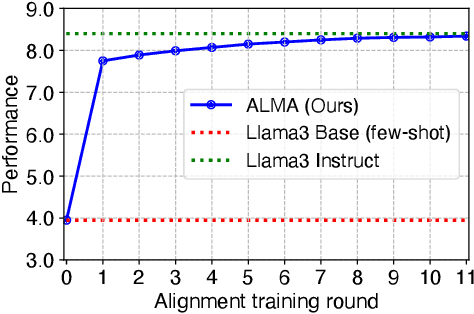

Recent approaches to large language model (LLM) alignment typically require millions of human annotations or rely on external aligned models for synthetic data generation. This paper introduces ALMA: Alignment with Minimal Annotation, demonstrating that effective alignment can be achieved using only 9,000 labeled examples -- less than 1% of conventional approaches. ALMA generates large amounts of high-quality synthetic alignment data through new techniques: diverse prompt synthesis via few-shot learning, diverse response generation with multiple model checkpoints, and judge (reward model) enhancement through score aggregation and self-distillation. Using only a pretrained Llama3 base model, 5,000 SFT examples, and 4,000 judge annotations, ALMA achieves performance close to Llama3-Instruct across diverse alignment benchmarks (e.g., 0.1% difference on AlpacaEval 2.0 score). These results are achieved with a multi-round, self-bootstrapped data synthesis and training recipe that continues to improve for 10 rounds, surpassing the typical 3-round ceiling of previous methods. These results suggest that base models already possess sufficient knowledge for effective alignment, and that synthetic data generation methods can expose it.
Hardware Scaling Trends and Diminishing Returns in Large-Scale Distributed Training
Nov 20, 2024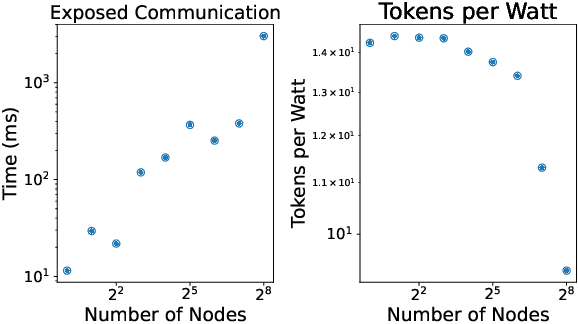

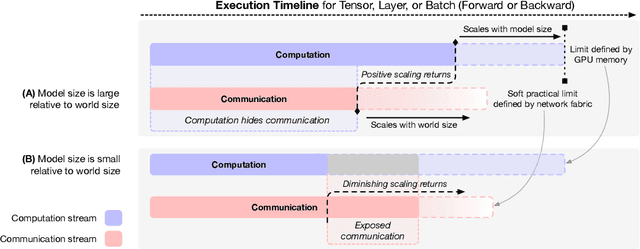
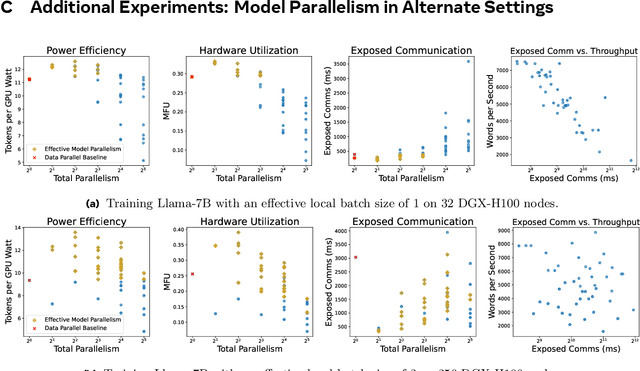
Dramatic increases in the capabilities of neural network models in recent years are driven by scaling model size, training data, and corresponding computational resources. To develop the exceedingly large networks required in modern applications, such as large language models (LLMs), model training is distributed across tens of thousands of hardware accelerators (e.g. GPUs), requiring orchestration of computation and communication across large computing clusters. In this work, we demonstrate that careful consideration of hardware configuration and parallelization strategy is critical for effective (i.e. compute- and cost-efficient) scaling of model size, training data, and total computation. We conduct an extensive empirical study of the performance of large-scale LLM training workloads across model size, hardware configurations, and distributed parallelization strategies. We demonstrate that: (1) beyond certain scales, overhead incurred from certain distributed communication strategies leads parallelization strategies previously thought to be sub-optimal in fact become preferable; and (2) scaling the total number of accelerators for large model training quickly yields diminishing returns even when hardware and parallelization strategies are properly optimized, implying poor marginal performance per additional unit of power or GPU-hour.
Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model
Aug 20, 2024



We introduce Transfusion, a recipe for training a multi-modal model over discrete and continuous data. Transfusion combines the language modeling loss function (next token prediction) with diffusion to train a single transformer over mixed-modality sequences. We pretrain multiple Transfusion models up to 7B parameters from scratch on a mixture of text and image data, establishing scaling laws with respect to a variety of uni- and cross-modal benchmarks. Our experiments show that Transfusion scales significantly better than quantizing images and training a language model over discrete image tokens. By introducing modality-specific encoding and decoding layers, we can further improve the performance of Transfusion models, and even compress each image to just 16 patches. We further demonstrate that scaling our Transfusion recipe to 7B parameters and 2T multi-modal tokens produces a model that can generate images and text on a par with similar scale diffusion models and language models, reaping the benefits of both worlds.