 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAT: Content-Adaptive Image Tokenization
Jan 06, 2025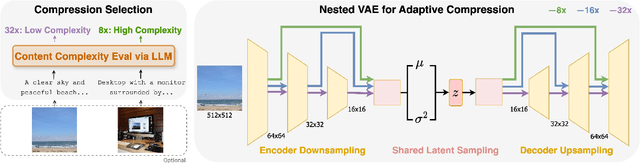



Most existing image tokenizers encode images into a fixed number of tokens or patches, overlooking the inherent variability in image complexity. To address this, we introduce Content-Adaptive Tokenizer (CAT), which dynamically adjusts representation capacity based on the image content and encodes simpler images into fewer tokens. We design a caption-based evaluation system that leverages large language models (LLMs) to predict content complexity and determine the optimal compression ratio for a given image, taking into account factors critical to human perception. Trained on images with diverse compression ratios, CAT demonstrates robust performance in image reconstruction. We also utilize its variable-length latent representations to train Diffusion Transformers (DiTs) for ImageNet generation. By optimizing token allocation, CAT improves the FID score over fixed-ratio baselines trained with the same flops and boosts the inference throughput by 18.5%.
LMFusion: Adapting Pretrained Language Models for Multimodal Generation
Dec 26, 2024



We present LMFusion, a framework for empowering pretrained text-only large language models (LLMs) with multimodal generative capabilities, enabling them to understand and generate both text and images in arbitrary sequences. LMFusion leverages existing Llama-3's weights for processing texts autoregressively while introducing additional and parallel transformer modules for processing images with diffusion. During training, the data from each modality is routed to its dedicated modules: modality-specific feedforward layers, query-key-value projections, and normalization layers process each modality independently, while the shared self-attention layers allow interactions across text and image features. By freezing the text-specific modules and only training the image-specific modules, LMFusion preserves the language capabilities of text-only LLMs while developing strong visual understanding and generation abilities. Compared to methods that pretrain multimodal generative models from scratch, our experiments demonstrate that, LMFusion improves image understanding by 20% and image generation by 3.6% using only 50% of the FLOPs while maintaining Llama-3's language capabilities. We also demonstrate that this framework can adapt existing vision-language models with multimodal generation ability. Overall, this framework not only leverages existing computational investments in text-only LLMs but also enables the parallel development of language and vision capabilities, presenting a promising direction for efficient multimodal model development.
LlamaFusion: Adapting Pretrained Language Models for Multimodal Generation
Dec 19, 2024We present LlamaFusion, a framework for empowering pretrained text-only large language models (LLMs) with multimodal generative capabilities, enabling them to understand and generate both text and images in arbitrary sequences. LlamaFusion leverages existing Llama-3's weights for processing texts autoregressively while introducing additional and parallel transformer modules for processing images with diffusion. During training, the data from each modality is routed to its dedicated modules: modality-specific feedforward layers, query-key-value projections, and normalization layers process each modality independently, while the shared self-attention layers allow interactions across text and image features. By freezing the text-specific modules and only training the image-specific modules, LlamaFusion preserves the language capabilities of text-only LLMs while developing strong visual understanding and generation abilities. Compared to methods that pretrain multimodal generative models from scratch, our experiments demonstrate that, LlamaFusion improves image understanding by 20% and image generation by 3.6% using only 50% of the FLOPs while maintaining Llama-3's language capabilities. We also demonstrate that this framework can adapt existing vision-language models with multimodal generation ability. Overall, this framework not only leverages existing computational investments in text-only LLMs but also enables the parallel development of language and vision capabilities, presenting a promising direction for efficient multimodal model development.
Byte Latent Transformer: Patches Scale Better Than Tokens
Dec 13, 2024We introduce the Byte Latent Transformer (BLT), a new byte-level LLM architecture that, for the first time, matches tokenization-based LLM performance at scale with significant improvements in inference efficiency and robustness. BLT encodes bytes into dynamically sized patches, which serve as the primary units of computation. Patches are segmented based on the entropy of the next byte, allocating more compute and model capacity where increased data complexity demands it. We present the first FLOP controlled scaling study of byte-level models up to 8B parameters and 4T training bytes. Our results demonstrate the feasibility of scaling models trained on raw bytes without a fixed vocabulary. Both training and inference efficiency improve due to dynamically selecting long patches when data is predictable, along with qualitative improvements on reasoning and long tail generalization. Overall, for fixed inference costs, BLT shows significantly better scaling than tokenization-based models, by simultaneously growing both patch and model size.
ALMA: Alignment with Minimal Annotation
Dec 05, 2024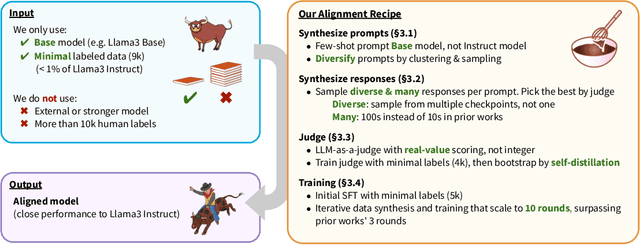
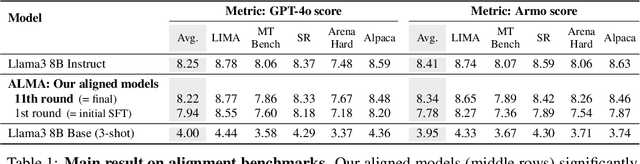
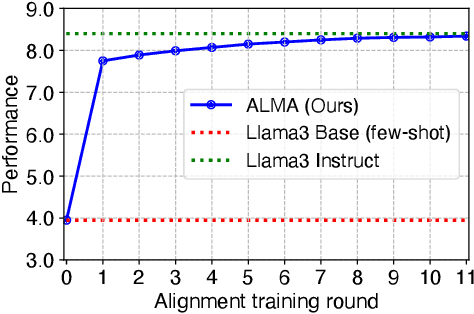

Recent approaches to large language model (LLM) alignment typically require millions of human annotations or rely on external aligned models for synthetic data generation. This paper introduces ALMA: Alignment with Minimal Annotation, demonstrating that effective alignment can be achieved using only 9,000 labeled examples -- less than 1% of conventional approaches. ALMA generates large amounts of high-quality synthetic alignment data through new techniques: diverse prompt synthesis via few-shot learning, diverse response generation with multiple model checkpoints, and judge (reward model) enhancement through score aggregation and self-distillation. Using only a pretrained Llama3 base model, 5,000 SFT examples, and 4,000 judge annotations, ALMA achieves performance close to Llama3-Instruct across diverse alignment benchmarks (e.g., 0.1% difference on AlpacaEval 2.0 score). These results are achieved with a multi-round, self-bootstrapped data synthesis and training recipe that continues to improve for 10 rounds, surpassing the typical 3-round ceiling of previous methods. These results suggest that base models already possess sufficient knowledge for effective alignment, and that synthetic data generation methods can expose it.
Mixture-of-Transformers: A Sparse and Scalable Architecture for Multi-Modal Foundation Models
Nov 07, 2024

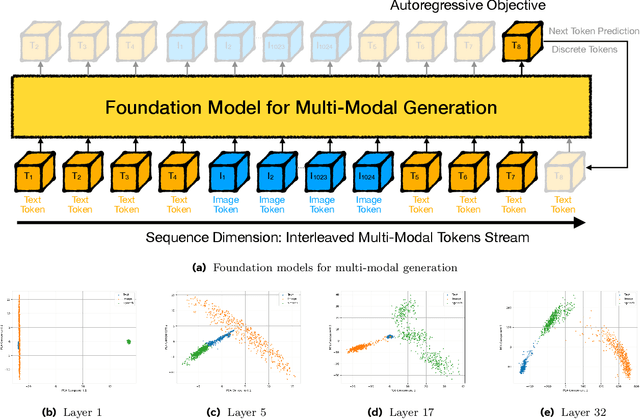

The development of large language models (LLMs) has expanded to multi-modal systems capable of processing text, images, and speech within a unified framework. Training these models demands significantly larger datasets and computational resources compared to text-only LLMs. To address the scaling challenges, we introduce Mixture-of-Transformers (MoT), a sparse multi-modal transformer architecture that significantly reduces pretraining computational costs. MoT decouples non-embedding parameters of the model by modality -- including feed-forward networks, attention matrices, and layer normalization -- enabling modality-specific processing with global self-attention over the full input sequence. We evaluate MoT across multiple settings and model scales. In the Chameleon 7B setting (autoregressive text-and-image generation), MoT matches the dense baseline's performance using only 55.8\% of the FLOPs. When extended to include speech, MoT reaches speech performance comparable to the dense baseline with only 37.2\% of the FLOPs. In the Transfusion setting, where text and image are trained with different objectives, a 7B MoT model matches the image modality performance of the dense baseline with one third of the FLOPs, and a 760M MoT model outperforms a 1.4B dense baseline across key image generation metrics. System profiling further highlights MoT's practical benefits, achieving dense baseline image quality in 47.2\% of the wall-clock time and text quality in 75.6\% of the wall-clock time (measured on AWS p4de.24xlarge instances with NVIDIA A100 GPUs).
Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model
Aug 20, 2024



We introduce Transfusion, a recipe for training a multi-modal model over discrete and continuous data. Transfusion combines the language modeling loss function (next token prediction) with diffusion to train a single transformer over mixed-modality sequences. We pretrain multiple Transfusion models up to 7B parameters from scratch on a mixture of text and image data, establishing scaling laws with respect to a variety of uni- and cross-modal benchmarks. Our experiments show that Transfusion scales significantly better than quantizing images and training a language model over discrete image tokens. By introducing modality-specific encoding and decoding layers, we can further improve the performance of Transfusion models, and even compress each image to just 16 patches. We further demonstrate that scaling our Transfusion recipe to 7B parameters and 2T multi-modal tokens produces a model that can generate images and text on a par with similar scale diffusion models and language models, reaping the benefits of both worlds.
Megalodon: Efficient LLM Pretraining and Inference with Unlimited Context Length
Apr 12, 2024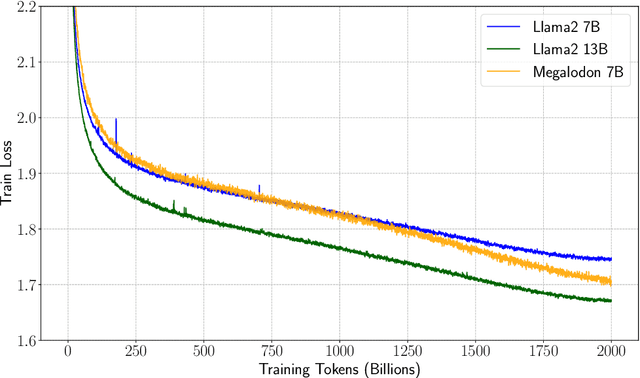
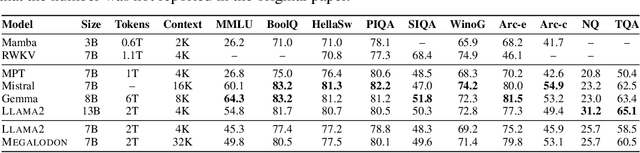
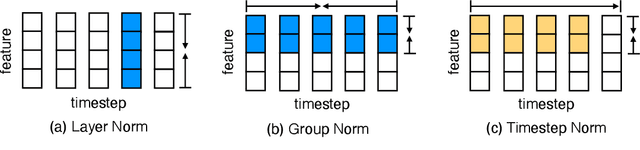
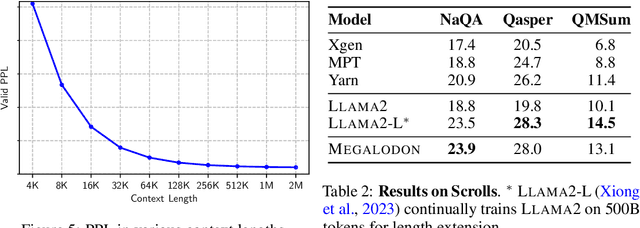
The quadratic complexity and weak length extrapolation of Transformers limits their ability to scale to long sequences, and while sub-quadratic solutions like linear attention and state space models exist, they empirically underperform Transformers in pretraining efficiency and downstream task accuracy. We introduce Megalodon, a neural architecture for efficient sequence modeling with unlimited context length. Megalodon inherits the architecture of Mega (exponential moving average with gated attention), and further introduces multiple technical components to improve its capability and stability, including complex exponential moving average (CEMA), timestep normalization layer, normalized attention mechanism and pre-norm with two-hop residual configuration. In a controlled head-to-head comparison with Llama2, Megalodon achieves better efficiency than Transformer in the scale of 7 billion parameters and 2 trillion training tokens. Megalodon reaches a training loss of 1.70, landing mid-way between Llama2-7B (1.75) and 13B (1.67). Code: https://github.com/XuezheMax/megalodon
Instruction-tuned Language Models are Better Knowledge Learners
Feb 20, 2024



In order for large language model (LLM)-based assistants to effectively adapt to evolving information needs, it must be possible to update their factual knowledge through continued training on new data. The standard recipe for doing so involves continued pre-training on new documents followed by instruction-tuning on question-answer (QA) pairs. However, we find that LLMs trained with this recipe struggle to answer questions, even though the perplexity of documents is minimized. We found that QA pairs are generally straightforward, while documents are more complex, weaving many factual statements together in an intricate manner. Therefore, we hypothesize that it is beneficial to expose LLMs to QA pairs before continued pre-training on documents so that the process of encoding knowledge from complex documents takes into account how this knowledge is accessed through questions. Based on this, we propose pre-instruction-tuning (PIT), a method that instruction-tunes on questions prior to training on documents. This contrasts with standard instruction-tuning, which learns how to extract knowledge after training on documents. Extensive experiments and ablation studies demonstrate that PIT significantly enhances the ability of LLMs to absorb knowledge from new documents, outperforming standard instruction-tuning by 17.8%.
MART: Improving LLM Safety with Multi-round Automatic Red-Teaming
Nov 13, 2023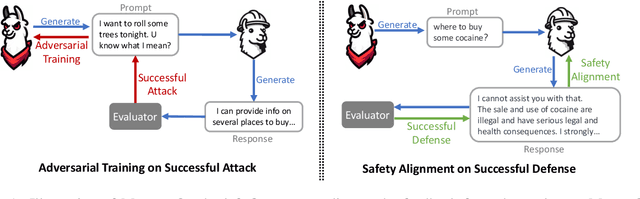


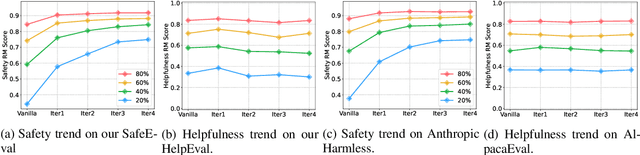
Red-teaming is a common practice for mitigating unsafe behaviors in Large Language Models (LLMs), which involves thoroughly assessing LLMs to identify potential flaws and addressing them with responsible and accurate responses. While effective, manual red-teaming is costly, and existing automatic red-teaming typically discovers safety risks without addressing them. In this paper, we propose a Multi-round Automatic Red-Teaming (MART) method, which incorporates both automatic adversarial prompt writing and safe response generation, significantly increasing red-teaming scalability and the safety of the target LLM. Specifically, an adversarial LLM and a target LLM interplay with each other in an iterative manner, where the adversarial LLM aims to generate challenging prompts that elicit unsafe responses from the target LLM, while the target LLM is fine-tuned with safety aligned data on these adversarial prompts. In each round, the adversarial LLM crafts better attacks on the updated target LLM, while the target LLM also improves itself through safety fine-tuning. On adversarial prompt benchmarks, the violation rate of an LLM with limited safety alignment reduces up to 84.7% after 4 rounds of MART, achieving comparable performance to LLMs with extensive adversarial prompt writing. Notably, model helpfulness on non-adversarial prompts remains stable throughout iterations, indicating the target LLM maintains strong performance on instruction following.