 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-Aware Heterogeneous GNN Architecture for Real-Time BESS Optimization in Unbalanced Distribution Systems
Dec 10, 2025Battery energy storage systems (BESS) have become increasingly vital in three-phase unbalanced distribution grids for maintaining voltage stability and enabling optimal dispatch. However, existing deep learning approaches often lack explicit three-phase representation, making it difficult to accurately model phase-specific dynamics and enforce operational constraints--leading to infeasible dispatch solutions. This paper demonstrates that by embedding detailed three-phase grid information--including phase voltages, unbalanced loads, and BESS states--into heterogeneous graph nodes, diverse GNN architectures (GCN, GAT, GraphSAGE, GPS) can jointly predict network state variables with high accuracy. Moreover, a physics-informed loss function incorporates critical battery constraints--SoC and C-rate limits--via soft penalties during training. Experimental validation on the CIGRE 18-bus distribution system shows that this embedding-loss approach achieves low prediction errors, with bus voltage MSEs of 6.92e-07 (GCN), 1.21e-06 (GAT), 3.29e-05 (GPS), and 9.04e-07 (SAGE). Importantly, the physics-informed method ensures nearly zero SoC and C-rate constraint violations, confirming its effectiveness for reliable, constraint-compliant dispatch.
Byte Latent Transformer: Patches Scale Better Than Tokens
Dec 13, 2024We introduce the Byte Latent Transformer (BLT), a new byte-level LLM architecture that, for the first time, matches tokenization-based LLM performance at scale with significant improvements in inference efficiency and robustness. BLT encodes bytes into dynamically sized patches, which serve as the primary units of computation. Patches are segmented based on the entropy of the next byte, allocating more compute and model capacity where increased data complexity demands it. We present the first FLOP controlled scaling study of byte-level models up to 8B parameters and 4T training bytes. Our results demonstrate the feasibility of scaling models trained on raw bytes without a fixed vocabulary. Both training and inference efficiency improve due to dynamically selecting long patches when data is predictable, along with qualitative improvements on reasoning and long tail generalization. Overall, for fixed inference costs, BLT shows significantly better scaling than tokenization-based models, by simultaneously growing both patch and model size.
PowerFlowMultiNet: Multigraph Neural Networks for Unbalanced Three-Phase Distribution Systems
Mar 12, 2024



Efficiently solving unbalanced three-phase power flow in distribution grids is pivotal for grid analysis and simulation. There is a pressing need for scalable algorithms capable of handling large-scale unbalanced power grids that can provide accurate and fast solutions. To address this, deep learning techniques, especially Graph Neural Networks (GNNs), have emerged. However, existing literature primarily focuses on balanced networks, leaving a critical gap in supporting unbalanced three-phase power grids. This letter introduces PowerFlowMultiNet, a novel multigraph GNN framework explicitly designed for unbalanced three-phase power grids. The proposed approach models each phase separately in a multigraph representation, effectively capturing the inherent asymmetry in unbalanced grids. A graph embedding mechanism utilizing message passing is introduced to capture spatial dependencies within the power system network. PowerFlowMultiNet outperforms traditional methods and other deep learning approaches in terms of accuracy and computational speed. Rigorous testing reveals significantly lower error rates and a notable hundredfold increase in computational speed for large power networks compared to model-based methods.
MultiContrievers: Analysis of Dense Retrieval Representations
Feb 24, 2024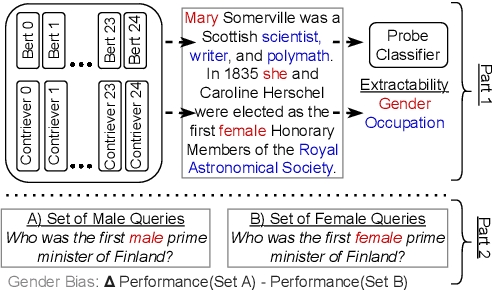

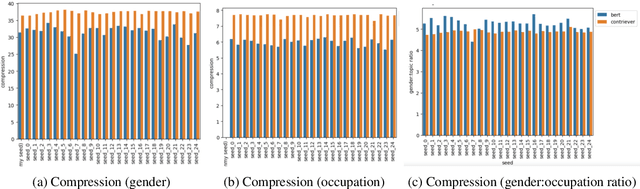
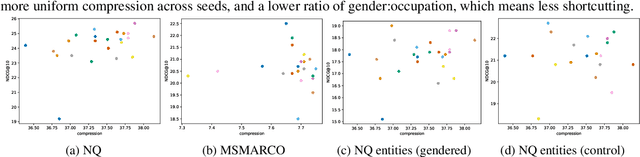
Dense retrievers compress source documents into (possibly lossy) vector representations, yet there is little analysis of what information is lost versus preserved, and how it affects downstream tasks. We conduct the first analysis of the information captured by dense retrievers compared to the language models they are based on (e.g., BERT versus Contriever). We use 25 MultiBert checkpoints as randomized initialisations to train MultiContrievers, a set of 25 contriever models. We test whether specific pieces of information -- such as gender and occupation -- can be extracted from contriever vectors of wikipedia-like documents. We measure this extractability via information theoretic probing. We then examine the relationship of extractability to performance and gender bias, as well as the sensitivity of these results to many random initialisations and data shuffles. We find that (1) contriever models have significantly increased extractability, but extractability usually correlates poorly with benchmark performance 2) gender bias is present, but is not caused by the contriever representations 3) there is high sensitivity to both random initialisation and to data shuffle, suggesting that future retrieval research should test across a wider spread of both.
Instruction-tuned Language Models are Better Knowledge Learners
Feb 20, 2024



In order for large language model (LLM)-based assistants to effectively adapt to evolving information needs, it must be possible to update their factual knowledge through continued training on new data. The standard recipe for doing so involves continued pre-training on new documents followed by instruction-tuning on question-answer (QA) pairs. However, we find that LLMs trained with this recipe struggle to answer questions, even though the perplexity of documents is minimized. We found that QA pairs are generally straightforward, while documents are more complex, weaving many factual statements together in an intricate manner. Therefore, we hypothesize that it is beneficial to expose LLMs to QA pairs before continued pre-training on documents so that the process of encoding knowledge from complex documents takes into account how this knowledge is accessed through questions. Based on this, we propose pre-instruction-tuning (PIT), a method that instruction-tunes on questions prior to training on documents. This contrasts with standard instruction-tuning, which learns how to extract knowledge after training on documents. Extensive experiments and ablation studies demonstrate that PIT significantly enhances the ability of LLMs to absorb knowledge from new documents, outperforming standard instruction-tuning by 17.8%.
RA-DIT: Retrieval-Augmented Dual Instruction Tuning
Oct 08, 2023
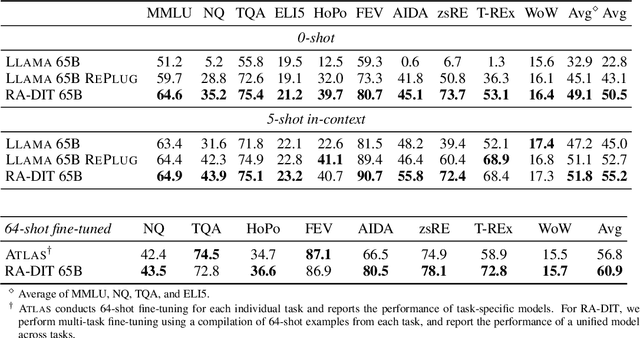
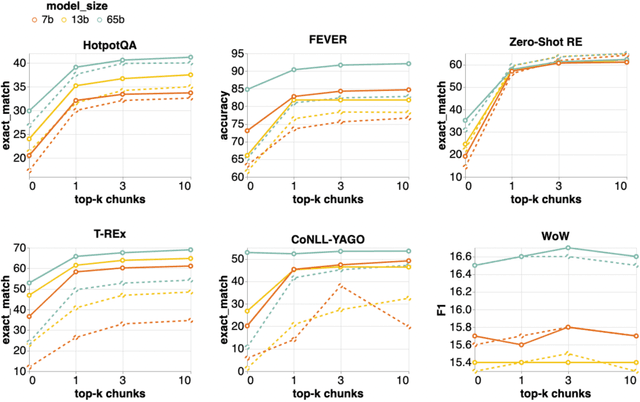
Retrieval-augmented language models (RALMs) improve performance by accessing long-tail and up-to-date knowledge from external data stores, but are challenging to build. Existing approaches require either expensive retrieval-specific modifications to LM pre-training or use post-hoc integration of the data store that leads to suboptimal performance. We introduce Retrieval-Augmented Dual Instruction Tuning (RA-DIT), a lightweight fine-tuning methodology that provides a third option by retrofitting any LLM with retrieval capabilities. Our approach operates in two distinct fine-tuning steps: (1) one updates a pre-trained LM to better use retrieved information, while (2) the other updates the retriever to return more relevant results, as preferred by the LM. By fine-tuning over tasks that require both knowledge utilization and contextual awareness, we demonstrate that each stage yields significant performance improvements, and using both leads to additional gains. Our best model, RA-DIT 65B, achieves state-of-the-art performance across a range of knowledge-intensive zero- and few-shot learning benchmarks, significantly outperforming existing in-context RALM approaches by up to +8.9% in 0-shot setting and +1.4% in 5-shot setting on average.
Reimagining Retrieval Augmented Language Models for Answering Queries
Jun 01, 2023

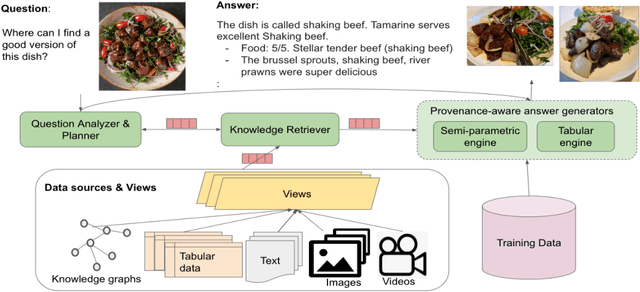
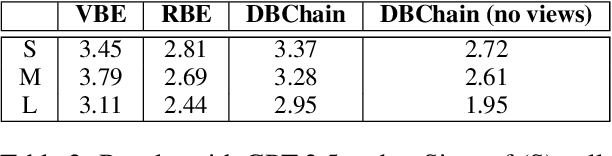
We present a reality check on large language models and inspect the promise of retrieval augmented language models in comparison. Such language models are semi-parametric, where models integrate model parameters and knowledge from external data sources to make their predictions, as opposed to the parametric nature of vanilla large language models. We give initial experimental findings that semi-parametric architectures can be enhanced with views, a query analyzer/planner, and provenance to make a significantly more powerful system for question answering in terms of accuracy and efficiency, and potentially for other NLP tasks
Fighting FIRe with FIRE: Assessing the Validity of Text-to-Video Retrieval Benchmarks
Oct 10, 2022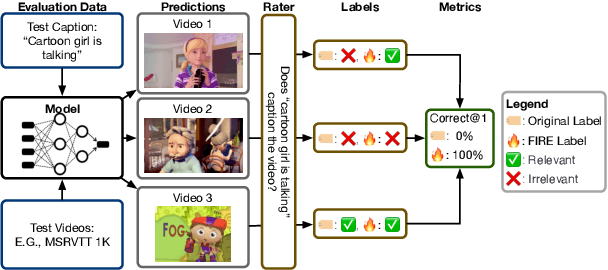
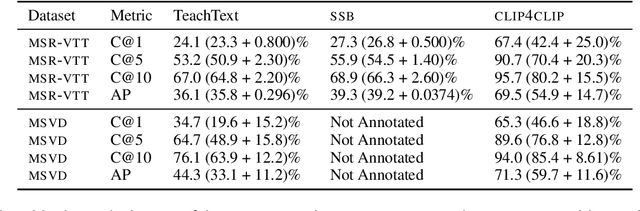
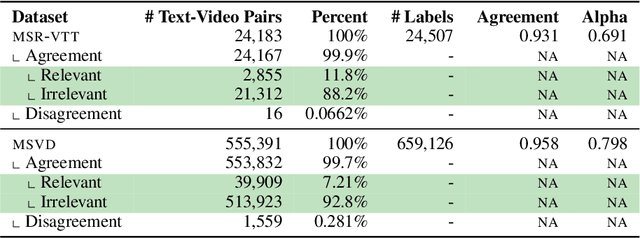
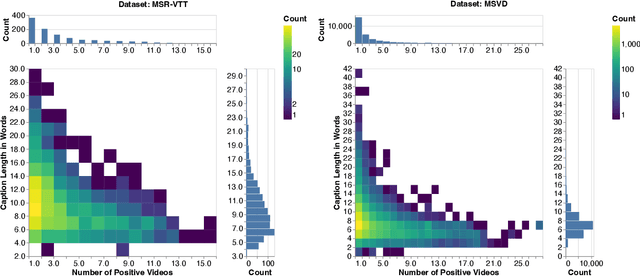
Searching vast troves of videos with textual descriptions is a core multimodal retrieval task. Owing to the lack of a purpose-built dataset for text-to-video retrieval, video captioning datasets have been re-purposed to evaluate models by (1) treating captions as positive matches to their respective videos and (2) all other videos as negatives. However, this methodology leads to a fundamental flaw during evaluation: since captions are marked as relevant only to their original video, many alternate videos also match the caption, which creates false-negative caption-video pairs. We show that when these false negatives are corrected, a recent state-of-the-art model gains 25% recall points -- a difference that threatens the validity of the benchmark itself. To diagnose and mitigate this issue, we annotate and release 683K additional caption-video pairs. Using these, we recompute effectiveness scores for three models on two standard benchmarks (MSR-VTT and MSVD). We find that (1) the recomputed metrics are up to 25% recall points higher for the best models, (2) these benchmarks are nearing saturation for Recall@10, (3) caption length (generality) is related to the number of positives, and (4) annotation costs can be mitigated by choosing evaluation sizes corresponding to desired effect size to detect. We recommend retiring these benchmarks in their current form and make recommendations for future text-to-video retrieval benchmarks.
Dynatask: A Framework for Creating Dynamic AI Benchmark Tasks
Apr 05, 2022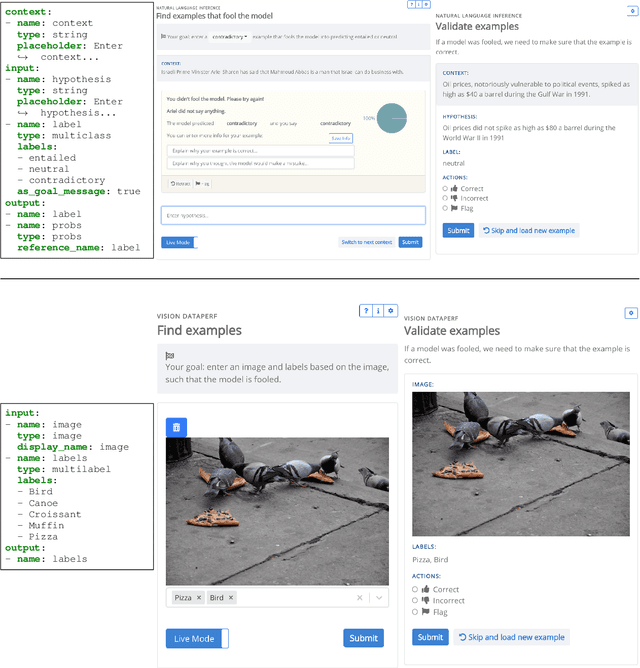
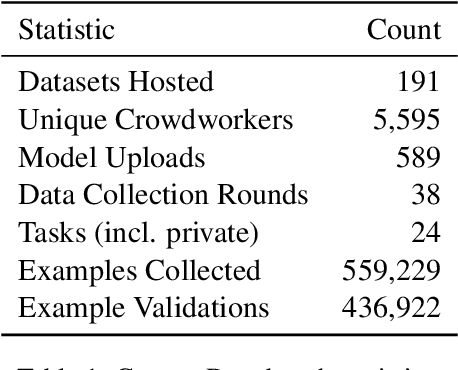
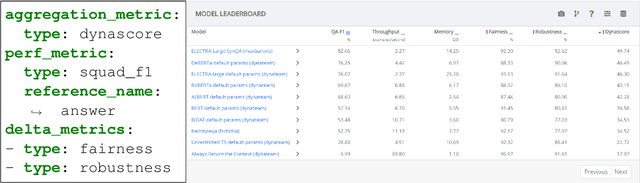
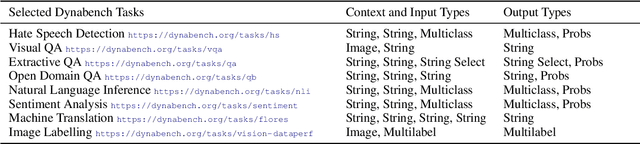
We introduce Dynatask: an open source system for setting up custom NLP tasks that aims to greatly lower the technical knowledge and effort required for hosting and evaluating state-of-the-art NLP models, as well as for conducting model in the loop data collection with crowdworkers. Dynatask is integrated with Dynabench, a research platform for rethinking benchmarking in AI that facilitates human and model in the loop data collection and evaluation. To create a task, users only need to write a short task configuration file from which the relevant web interfaces and model hosting infrastructure are automatically generated. The system is available at https://dynabench.org/ and the full library can be found at https://github.com/facebookresearch/dynabench.
py-irt: A Scalable Item Response Theory Library for Python
Mar 13, 2022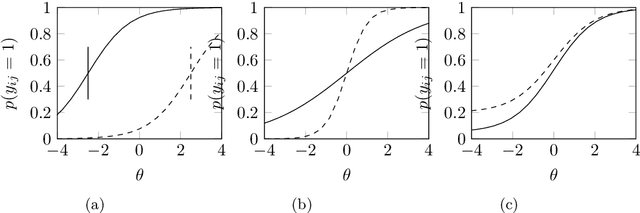
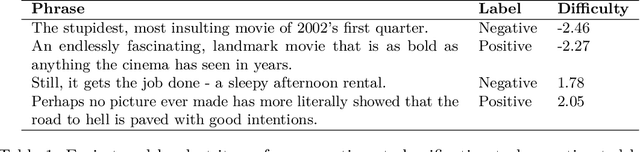

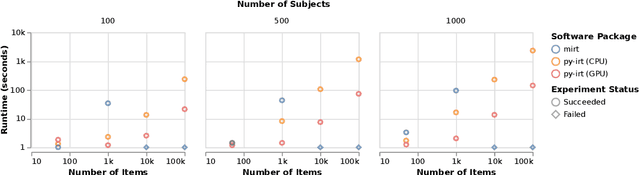
py-irt is a Python library for fitting Bayesian Item Response Theory (IRT) models. py-irt estimates latent traits of subjects and items, making it appropriate for use in IRT tasks as well as ideal-point models. py-irt is built on top of the Pyro and PyTorch frameworks and uses GPU-accelerated training to scale to large data sets. Code, documentation, and examples can be found at https://github.com/nd-ball/py-irt. py-irt can be installed from the GitHub page or the Python Package Index (PyPI).