 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePokeNet: Learning Kinematic Models of Articulated Objects from Human Observations
Feb 02, 2026Articulation modeling enables robots to learn joint parameters of articulated objects for effective manipulation which can then be used downstream for skill learning or planning. Existing approaches often rely on prior knowledge about the objects, such as the number or type of joints. Some of these approaches also fail to recover occluded joints that are only revealed during interaction. Others require large numbers of multi-view images for every object, which is impractical in real-world settings. Furthermore, prior works neglect the order of manipulations, which is essential for many multi-DoF objects where one joint must be operated before another, such as a dishwasher. We introduce PokeNet, an end-to-end framework that estimates articulation models from a single human demonstration without prior object knowledge. Given a sequence of point cloud observations of a human manipulating an unknown object, PokeNet predicts joint parameters, infers manipulation order, and tracks joint states over time. PokeNet outperforms existing state-of-the-art methods, improving joint axis and state estimation accuracy by an average of over 27% across diverse objects, including novel and unseen categories. We demonstrate these gains in both simulation and real-world environments.
Learning Sequential Kinematic Models from Demonstrations for Multi-Jointed Articulated Objects
May 09, 2025As robots become more generalized and deployed in diverse environments, they must interact with complex objects, many with multiple independent joints or degrees of freedom (DoF) requiring precise control. A common strategy is object modeling, where compact state-space models are learned from real-world observations and paired with classical planning. However, existing methods often rely on prior knowledge or focus on single-DoF objects, limiting their applicability. They also fail to handle occluded joints and ignore the manipulation sequences needed to access them. We address this by learning object models from human demonstrations. We introduce Object Kinematic Sequence Machines (OKSMs), a novel representation capturing both kinematic constraints and manipulation order for multi-DoF objects. To estimate these models from point cloud data, we present Pokenet, a deep neural network trained on human demonstrations. We validate our approach on 8,000 simulated and 1,600 real-world annotated samples. Pokenet improves joint axis and state estimation by over 20 percent on real-world data compared to prior methods. Finally, we demonstrate OKSMs on a Sawyer robot using inverse kinematics-based planning to manipulate multi-DoF objects.
TSPP: A Unified Benchmarking Tool for Time-series Forecasting
Jan 08, 2024



While machine learning has witnessed significant advancements, the emphasis has largely been on data acquisition and model creation. However, achieving a comprehensive assessment of machine learning solutions in real-world settings necessitates standardization throughout the entire pipeline. This need is particularly acute in time series forecasting, where diverse settings impede meaningful comparisons between various methods. To bridge this gap, we propose a unified benchmarking framework that exposes the crucial modelling and machine learning decisions involved in developing time series forecasting models. This framework fosters seamless integration of models and datasets, aiding both practitioners and researchers in their development efforts. We benchmark recently proposed models within this framework, demonstrating that carefully implemented deep learning models with minimal effort can rival gradient-boosting decision trees requiring extensive feature engineering and expert knowledge.
Improving Voice Trigger Detection with Metric Learning
Apr 05, 2022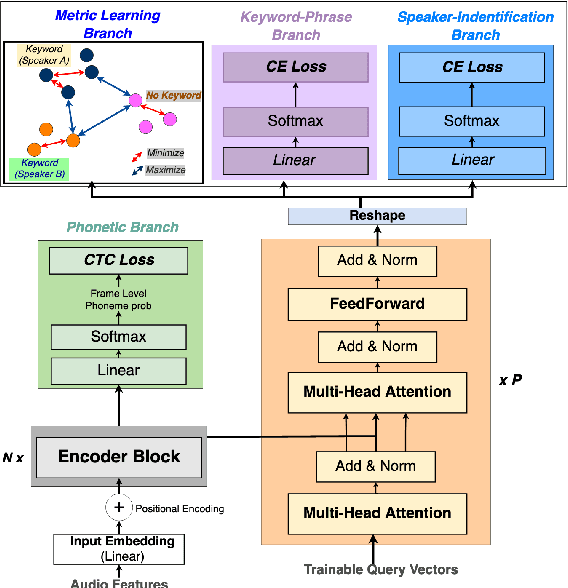

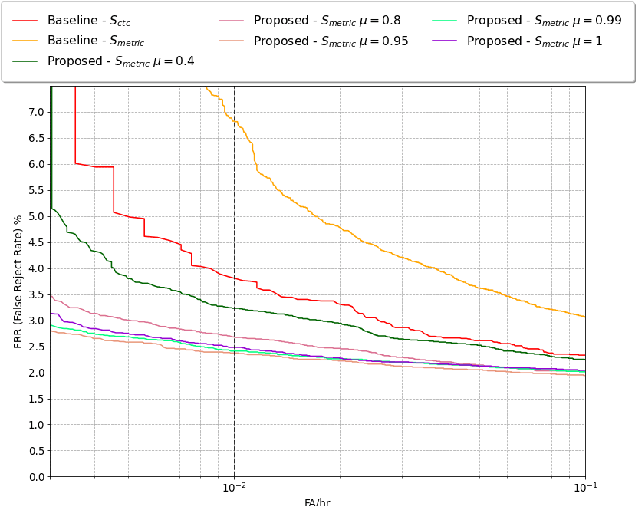
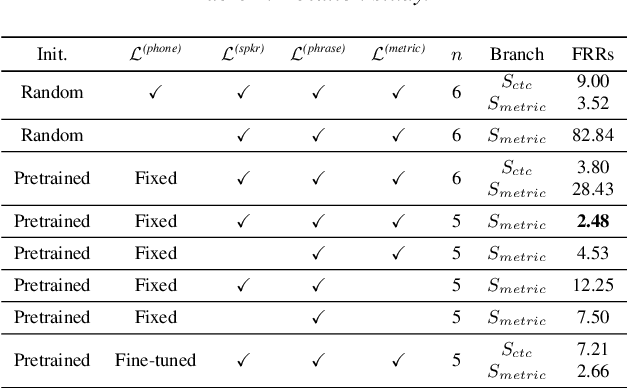
Voice trigger detection is an important task, which enables activating a voice assistant when a target user speaks a keyword phrase. A detector is typically trained on speech data independent of speaker information and used for the voice trigger detection task. However, such a speaker independent voice trigger detector typically suffers from performance degradation on speech from underrepresented groups, such as accented speakers. In this work, we propose a novel voice trigger detector that can use a small number of utterances from a target speaker to improve detection accuracy. Our proposed model employs an encoder-decoder architecture. While the encoder performs speaker independent voice trigger detection, similar to the conventional detector, the decoder predicts a personalized embedding for each utterance. A personalized voice trigger score is then obtained as a similarity score between the embeddings of enrollment utterances and a test utterance. The personalized embedding allows adapting to target speaker's speech when computing the voice trigger score, hence improving voice trigger detection accuracy. Experimental results show that the proposed approach achieves a 38% relative reduction in a false rejection rate (FRR) compared to a baseline speaker independent voice trigger model.
Dynatask: A Framework for Creating Dynamic AI Benchmark Tasks
Apr 05, 2022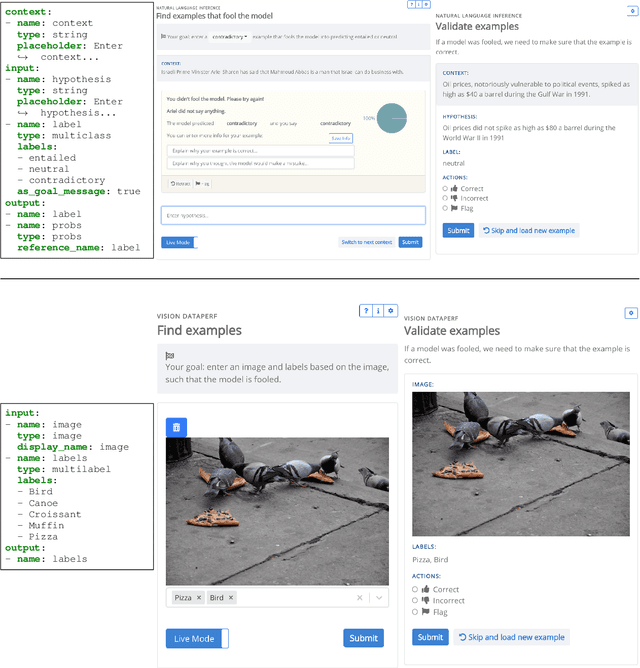
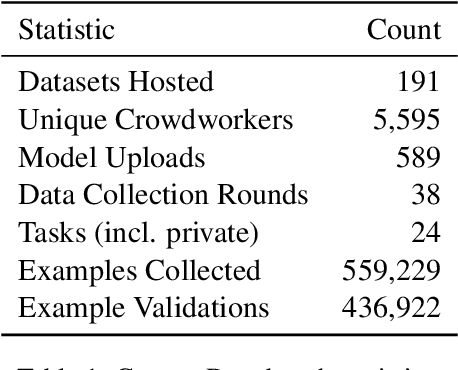
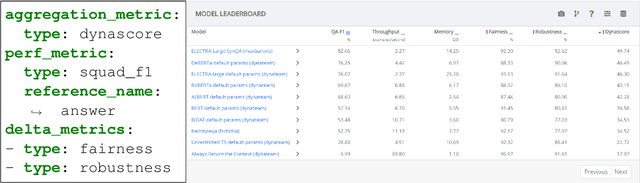
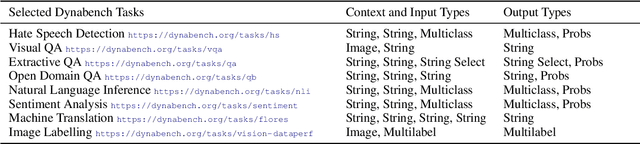
We introduce Dynatask: an open source system for setting up custom NLP tasks that aims to greatly lower the technical knowledge and effort required for hosting and evaluating state-of-the-art NLP models, as well as for conducting model in the loop data collection with crowdworkers. Dynatask is integrated with Dynabench, a research platform for rethinking benchmarking in AI that facilitates human and model in the loop data collection and evaluation. To create a task, users only need to write a short task configuration file from which the relevant web interfaces and model hosting infrastructure are automatically generated. The system is available at https://dynabench.org/ and the full library can be found at https://github.com/facebookresearch/dynabench.
Efficacy of Transformer Networks for Classification of Raw EEG Data
Feb 08, 2022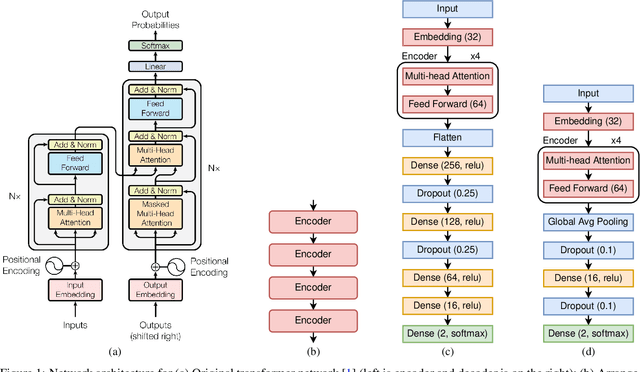
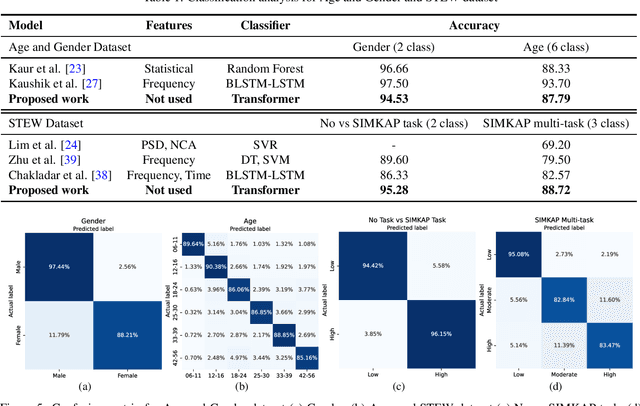
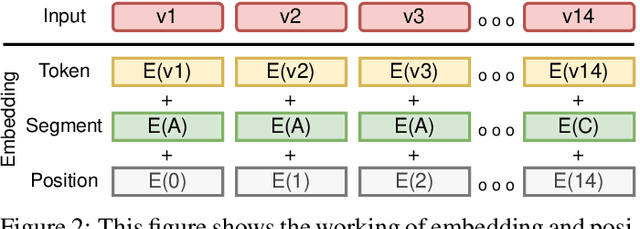
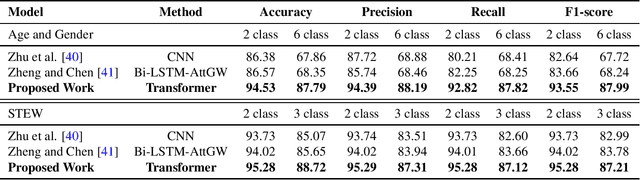
With the unprecedented success of transformer networks in natural language processing (NLP), recently, they have been successfully adapted to areas like computer vision, generative adversarial networks (GAN), and reinforcement learning. Classifying electroencephalogram (EEG) data has been challenging and researchers have been overly dependent on pre-processing and hand-crafted feature extraction. Despite having achieved automated feature extraction in several other domains, deep learning has not yet been accomplished for EEG. In this paper, the efficacy of the transformer network for the classification of raw EEG data (cleaned and pre-processed) is explored. The performance of transformer networks was evaluated on a local (age and gender data) and a public dataset (STEW). First, a classifier using a transformer network is built to classify the age and gender of a person with raw resting-state EEG data. Second, the classifier is tuned for mental workload classification with open access raw multi-tasking mental workload EEG data (STEW). The network achieves an accuracy comparable to state-of-the-art accuracy on both the local (Age and Gender dataset; 94.53% (gender) and 87.79% (age)) and the public (STEW dataset; 95.28% (two workload levels) and 88.72% (three workload levels)) dataset. The accuracy values have been achieved using raw EEG data without feature extraction. Results indicate that the transformer-based deep learning models can successfully abate the need for heavy feature-extraction of EEG data for successful classification.
Multi-task Learning with Cross Attention for Keyword Spotting
Jul 15, 2021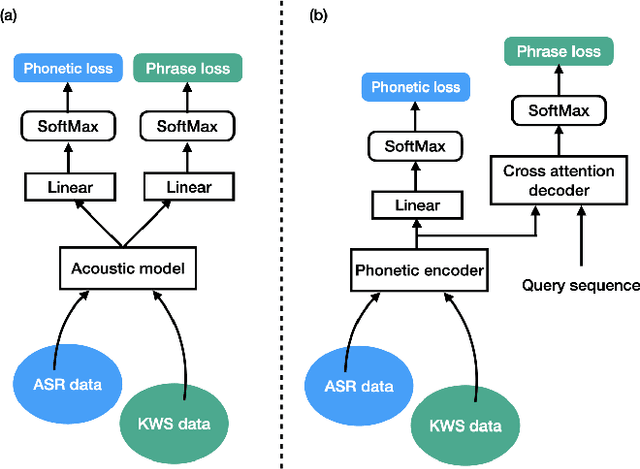
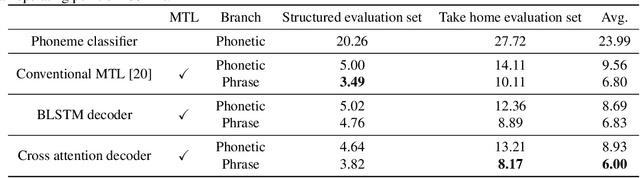
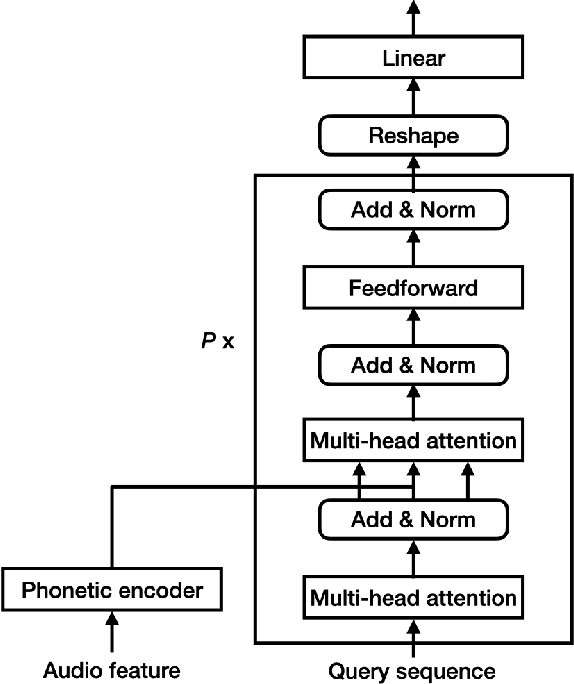
Keyword spotting (KWS) is an important technique for speech applications, which enables users to activate devices by speaking a keyword phrase. Although a phoneme classifier can be used for KWS, exploiting a large amount of transcribed data for automatic speech recognition (ASR), there is a mismatch between the training criterion (phoneme recognition) and the target task (KWS). Recently, multi-task learning has been applied to KWS to exploit both ASR and KWS training data. In this approach, an output of an acoustic model is split into two branches for the two tasks, one for phoneme transcription trained with the ASR data and one for keyword classification trained with the KWS data. In this paper, we introduce a cross attention decoder in the multi-task learning framework. Unlike the conventional multi-task learning approach with the simple split of the output layer, the cross attention decoder summarizes information from a phonetic encoder by performing cross attention between the encoder outputs and a trainable query sequence to predict a confidence score for the KWS task. Experimental results on KWS tasks show that the proposed approach outperformed the conventional multi-task learning with split branches and a bi-directional long short-team memory decoder by 12% on average.