 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multimodal Approach to Device-Directed Speech Detection with Large Language Models
Mar 26, 2024Interactions with virtual assistants typically start with a predefined trigger phrase followed by the user command. To make interactions with the assistant more intuitive, we explore whether it is feasible to drop the requirement that users must begin each command with a trigger phrase. We explore this task in three ways: First, we train classifiers using only acoustic information obtained from the audio waveform. Second, we take the decoder outputs of an automatic speech recognition (ASR) system, such as 1-best hypotheses, as input features to a large language model (LLM). Finally, we explore a multimodal system that combines acoustic and lexical features, as well as ASR decoder signals in an LLM. Using multimodal information yields relative equal-error-rate improvements over text-only and audio-only models of up to 39% and 61%. Increasing the size of the LLM and training with low-rank adaption leads to further relative EER reductions of up to 18% on our dataset.
Multimodal Data and Resource Efficient Device-Directed Speech Detection with Large Foundation Models
Dec 06, 2023Interactions with virtual assistants typically start with a trigger phrase followed by a command. In this work, we explore the possibility of making these interactions more natural by eliminating the need for a trigger phrase. Our goal is to determine whether a user addressed the virtual assistant based on signals obtained from the streaming audio recorded by the device microphone. We address this task by combining 1-best hypotheses and decoder signals from an automatic speech recognition system with acoustic representations from an audio encoder as input features to a large language model (LLM). In particular, we are interested in data and resource efficient systems that require only a small amount of training data and can operate in scenarios with only a single frozen LLM available on a device. For this reason, our model is trained on 80k or less examples of multimodal data using a combination of low-rank adaptation and prefix tuning. We compare the proposed system to unimodal baselines and show that the multimodal approach achieves lower equal-error-rates (EERs), while using only a fraction of the training data. We also show that low-dimensional specialized audio representations lead to lower EERs than high-dimensional general audio representations.
Improving Voice Trigger Detection with Metric Learning
Apr 05, 2022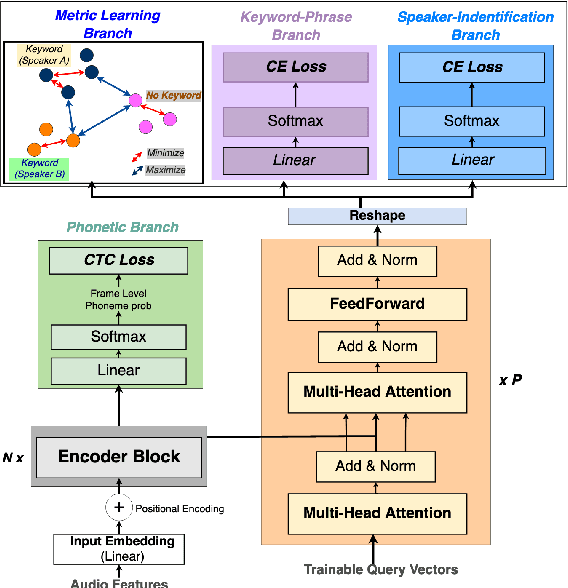

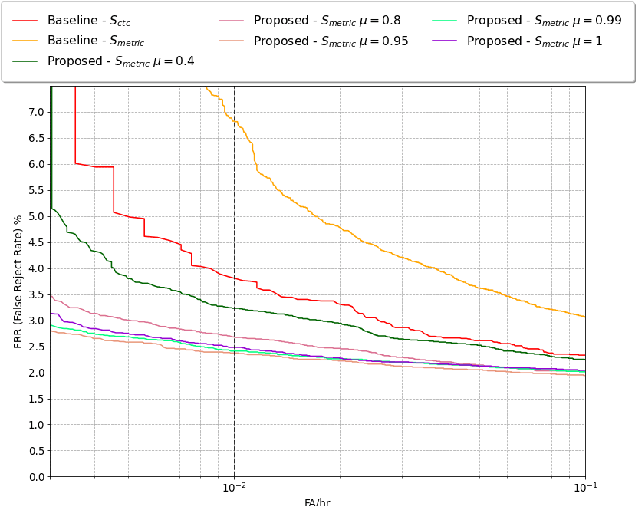
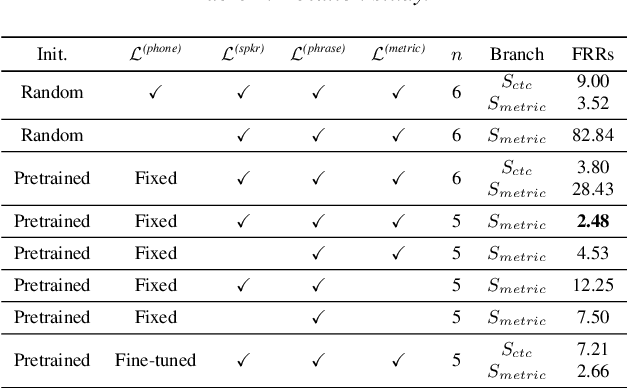
Voice trigger detection is an important task, which enables activating a voice assistant when a target user speaks a keyword phrase. A detector is typically trained on speech data independent of speaker information and used for the voice trigger detection task. However, such a speaker independent voice trigger detector typically suffers from performance degradation on speech from underrepresented groups, such as accented speakers. In this work, we propose a novel voice trigger detector that can use a small number of utterances from a target speaker to improve detection accuracy. Our proposed model employs an encoder-decoder architecture. While the encoder performs speaker independent voice trigger detection, similar to the conventional detector, the decoder predicts a personalized embedding for each utterance. A personalized voice trigger score is then obtained as a similarity score between the embeddings of enrollment utterances and a test utterance. The personalized embedding allows adapting to target speaker's speech when computing the voice trigger score, hence improving voice trigger detection accuracy. Experimental results show that the proposed approach achieves a 38% relative reduction in a false rejection rate (FRR) compared to a baseline speaker independent voice trigger model.
Streaming Transformer for Hardware Efficient Voice Trigger Detection and False Trigger Mitigation
May 14, 2021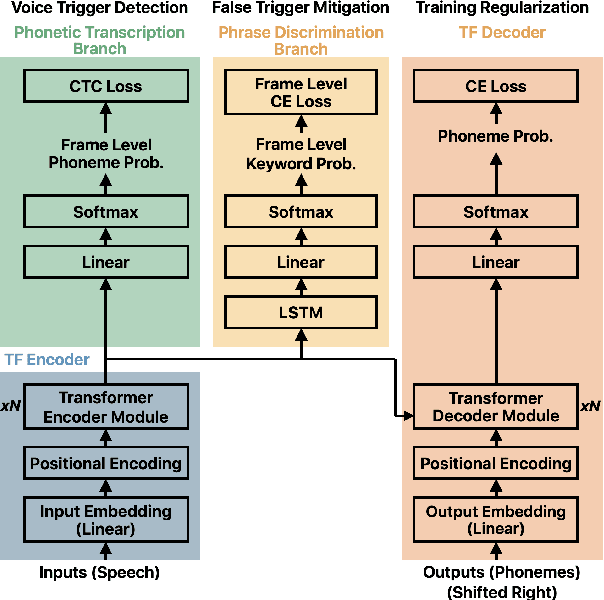
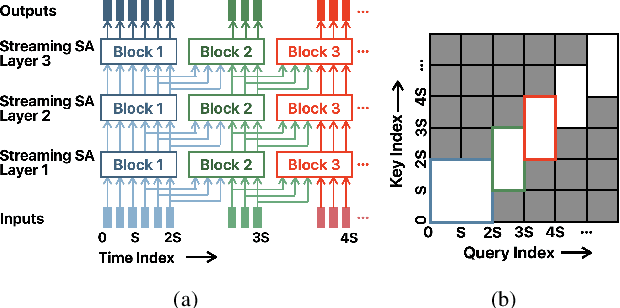

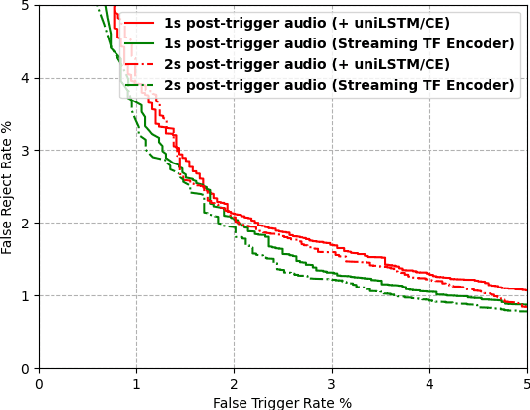
We present a unified and hardware efficient architecture for two stage voice trigger detection (VTD) and false trigger mitigation (FTM) tasks. Two stage VTD systems of voice assistants can get falsely activated to audio segments acoustically similar to the trigger phrase of interest. FTM systems cancel such activations by using post trigger audio context. Traditional FTM systems rely on automatic speech recognition lattices which are computationally expensive to obtain on device. We propose a streaming transformer (TF) encoder architecture, which progressively processes incoming audio chunks and maintains audio context to perform both VTD and FTM tasks using only acoustic features. The proposed joint model yields an average 18% relative reduction in false reject rate (FRR) for the VTD task at a given false alarm rate. Moreover, our model suppresses 95% of the false triggers with an additional one second of post-trigger audio. Finally, on-device measurements show 32% reduction in runtime memory and 56% reduction in inference time compared to non-streaming version of the model.
Progressive Voice Trigger Detection: Accuracy vs Latency
Oct 29, 2020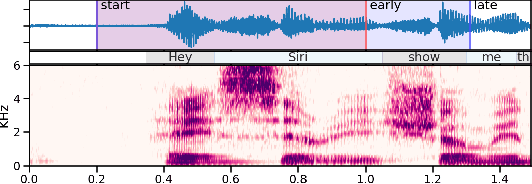
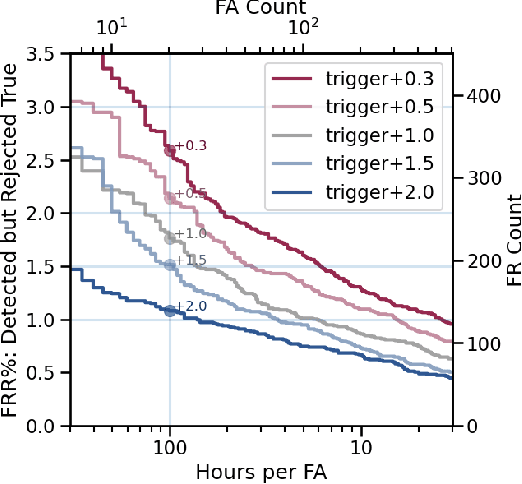
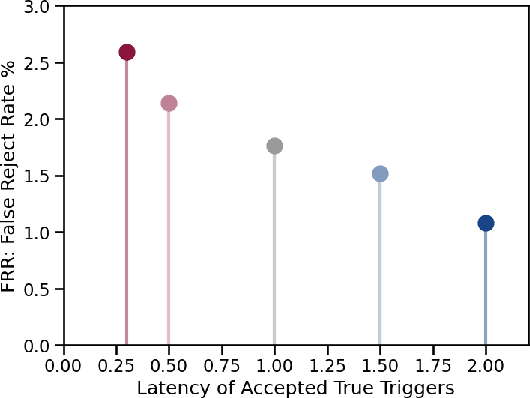
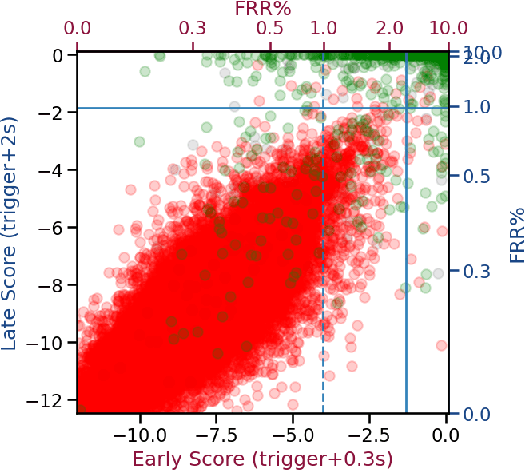
We present an architecture for voice trigger detection for virtual assistants. The main idea in this work is to exploit information in words that immediately follow the trigger phrase. We first demonstrate that by including more audio context after a detected trigger phrase, we can indeed get a more accurate decision. However, waiting to listen to more audio each time incurs a latency increase. Progressive Voice Trigger Detection allows us to trade-off latency and accuracy by accepting clear trigger candidates quickly, but waiting for more context to decide whether to accept more marginal examples. Using a two-stage architecture, we show that by delaying the decision for just 3% of detected true triggers in the test set, we are able to obtain a relative improvement of 66% in false rejection rate, while incurring only a negligible increase in latency.
Hybrid Transformer/CTC Networks for Hardware Efficient Voice Triggering
Aug 05, 2020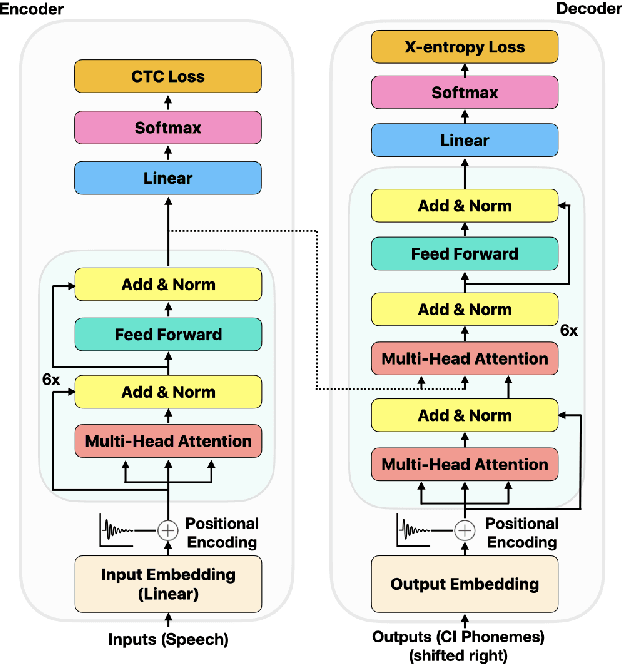
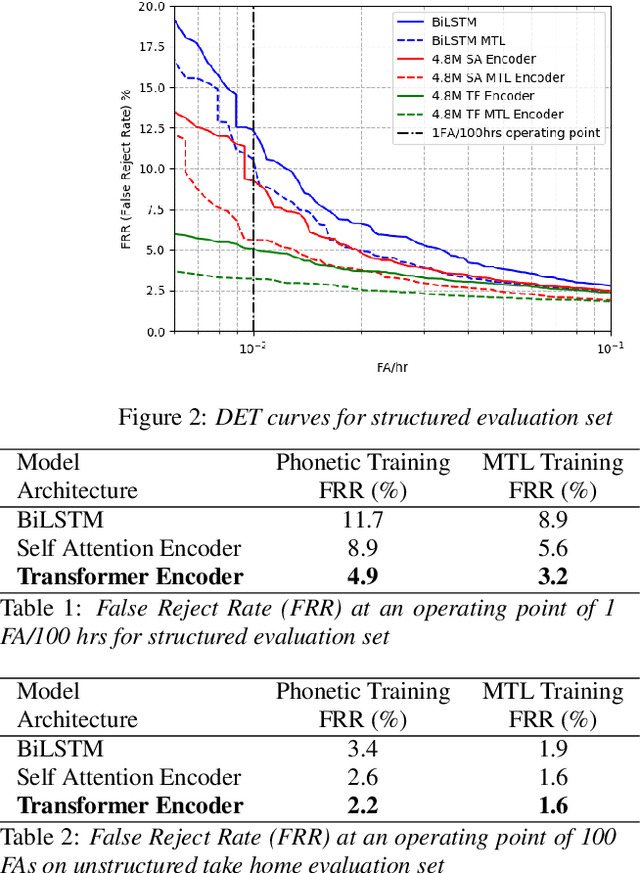
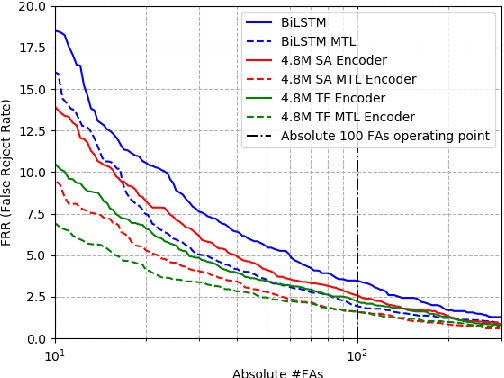
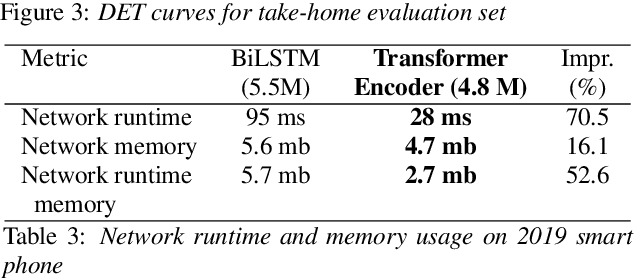
We consider the design of two-pass voice trigger detection systems. We focus on the networks in the second pass that are used to re-score candidate segments obtained from the first-pass. Our baseline is an acoustic model(AM), with BiLSTM layers, trained by minimizing the CTC loss. We replace the BiLSTM layers with self-attention layers. Results on internal evaluation sets show that self-attention networks yield better accuracy while requiring fewer parameters. We add an auto-regressive decoder network on top of the self-attention layers and jointly minimize the CTC loss on the encoder and the cross-entropy loss on the decoder. This design yields further improvements over the baseline. We retrain all the models above in a multi-task learning(MTL) setting, where one branch of a shared network is trained as an AM, while the second branch classifies the whole sequence to be true-trigger or not. Results demonstrate that networks with self-attention layers yield $\sim$60% relative reduction in false reject rates for a given false-alarm rate, while requiring 10% fewer parameters. When trained in the MTL setup, self-attention networks yield further accuracy improvements. On-device measurements show that we observe 70% relative reduction in inference time. Additionally, the proposed network architectures are $\sim$5X faster to train.
Multi-task Learning for Speaker Verification and Voice Trigger Detection
Jan 26, 2020
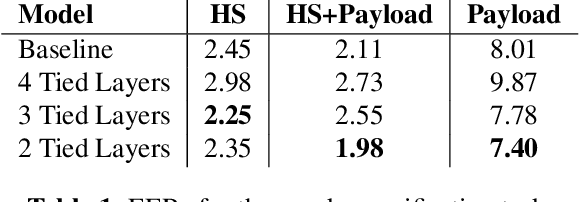
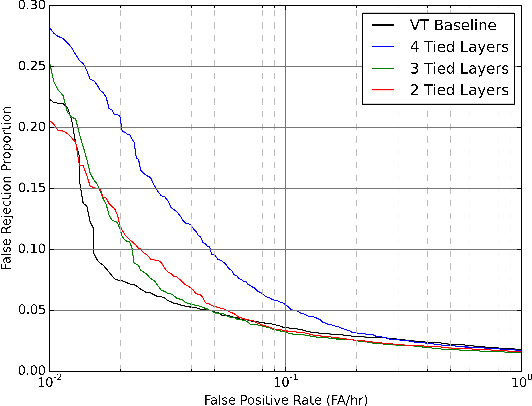
Automatic speech transcription and speaker recognition are usually treated as separate tasks even though they are interdependent. In this study, we investigate training a single network to perform both tasks jointly. We train the network in a supervised multi-task learning setup, where the speech transcription branch of the network is trained to minimise a phonetic connectionist temporal classification (CTC) loss while the speaker recognition branch of the network is trained to label the input sequence with the correct label for the speaker. We present a large-scale empirical study where the model is trained using several thousand hours of labelled training data for each task. We evaluate the speech transcription branch of the network on a voice trigger detection task while the speaker recognition branch is evaluated on a speaker verification task. Results demonstrate that the network is able to encode both phonetic \emph{and} speaker information in its learnt representations while yielding accuracies at least as good as the baseline models for each task, with the same number of parameters as the independent models.
Multi-task Learning for Voice Trigger Detection
Jan 26, 2020
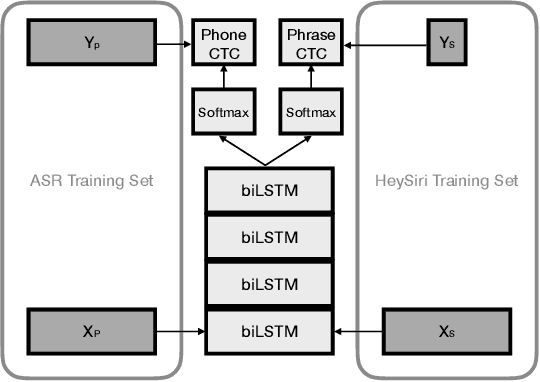
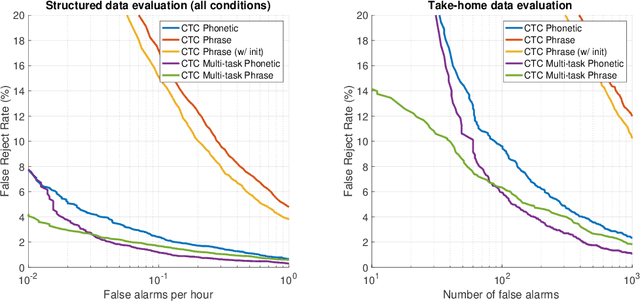
We describe the design of a voice trigger detection system for smart speakers. In this study, we address two major challenges. The first is that the detectors are deployed in complex acoustic environments with external noise and loud playback by the device itself. Secondly, collecting training examples for a specific keyword or trigger phrase is challenging resulting in a scarcity of trigger phrase specific training data. We describe a two-stage cascaded architecture where a low-power detector is always running and listening for the trigger phrase. If a detection is made at this stage, the candidate audio segment is re-scored by larger, more complex models to verify that the segment contains the trigger phrase. In this study, we focus our attention on the architecture and design of these second-pass detectors. We start by training a general acoustic model that produces phonetic transcriptions given a large labelled training dataset. Next, we collect a much smaller dataset of examples that are challenging for the baseline system. We then use multi-task learning to train a model to simultaneously produce accurate phonetic transcriptions on the larger dataset \emph{and} discriminate between true and easily confusable examples using the smaller dataset. Our results demonstrate that the proposed model reduces errors by half compared to the baseline in a range of challenging test conditions \emph{without} requiring extra parameters.
Unsupervised Feature Learning Based on Deep Models for Environmental Audio Tagging
Nov 29, 2016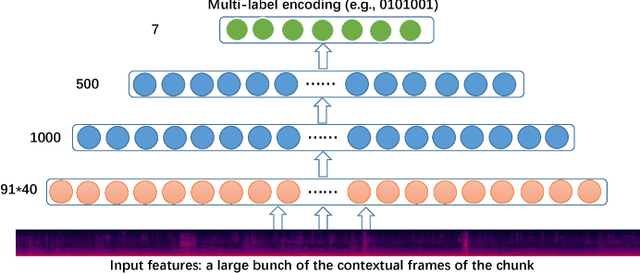
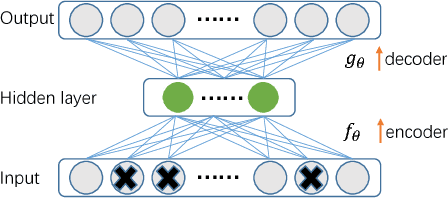
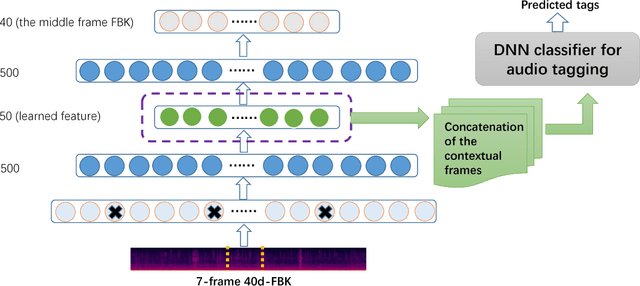
Environmental audio tagging aims to predict only the presence or absence of certain acoustic events in the interested acoustic scene. In this paper we make contributions to audio tagging in two parts, respectively, acoustic modeling and feature learning. We propose to use a shrinking deep neural network (DNN) framework incorporating unsupervised feature learning to handle the multi-label classification task. For the acoustic modeling, a large set of contextual frames of the chunk are fed into the DNN to perform a multi-label classification for the expected tags, considering that only chunk (or utterance) level rather than frame-level labels are available. Dropout and background noise aware training are also adopted to improve the generalization capability of the DNNs. For the unsupervised feature learning, we propose to use a symmetric or asymmetric deep de-noising auto-encoder (sDAE or aDAE) to generate new data-driven features from the Mel-Filter Banks (MFBs) features. The new features, which are smoothed against background noise and more compact with contextual information, can further improve the performance of the DNN baseline. Compared with the standard Gaussian Mixture Model (GMM) baseline of the DCASE 2016 audio tagging challenge, our proposed method obtains a significant equal error rate (EER) reduction from 0.21 to 0.13 on the development set. The proposed aDAE system can get a relative 6.7% EER reduction compared with the strong DNN baseline on the development set. Finally, the results also show that our approach obtains the state-of-the-art performance with 0.15 EER on the evaluation set of the DCASE 2016 audio tagging task while EER of the first prize of this challenge is 0.17.
* 10 pages, dcase 2016 challenge
Automatic Environmental Sound Recognition: Performance versus Computational Cost
Jul 15, 2016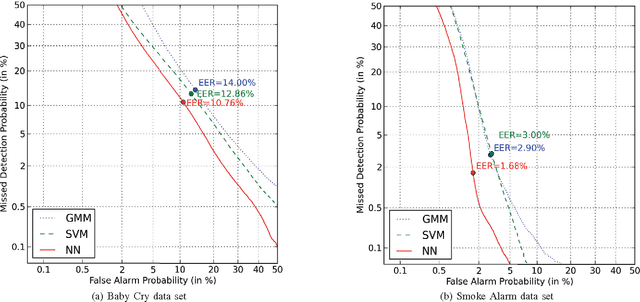
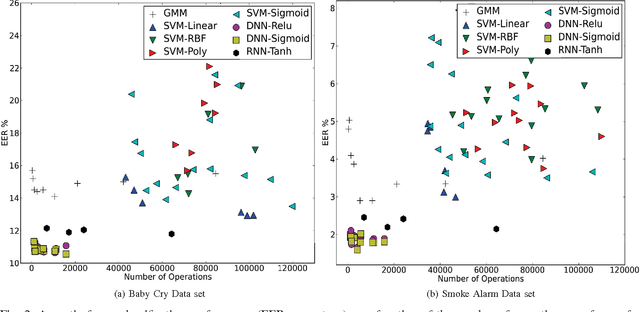
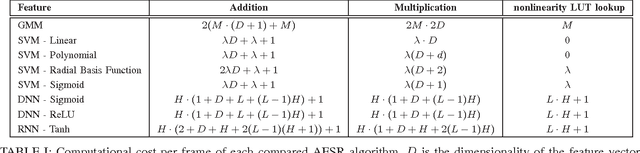

In the context of the Internet of Things (IoT), sound sensing applications are required to run on embedded platforms where notions of product pricing and form factor impose hard constraints on the available computing power. Whereas Automatic Environmental Sound Recognition (AESR) algorithms are most often developed with limited consideration for computational cost, this article seeks which AESR algorithm can make the most of a limited amount of computing power by comparing the sound classification performance em as a function of its computational cost. Results suggest that Deep Neural Networks yield the best ratio of sound classification accuracy across a range of computational costs, while Gaussian Mixture Models offer a reasonable accuracy at a consistently small cost, and Support Vector Machines stand between both in terms of compromise between accuracy and computational cost.