 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnomaly detection on streamed data
Jun 05, 2020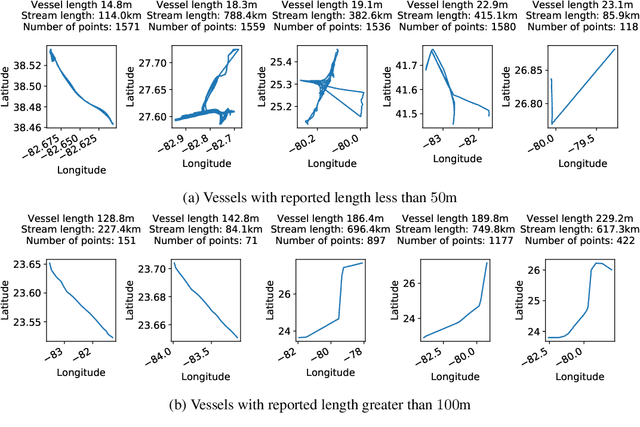

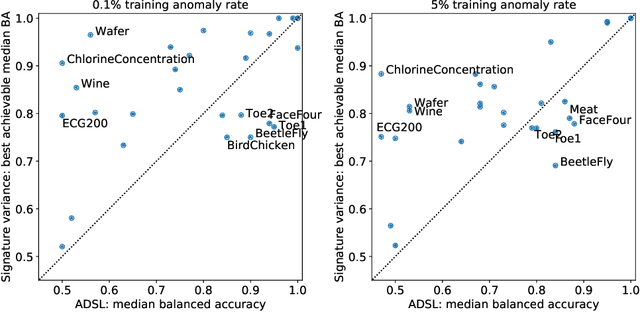
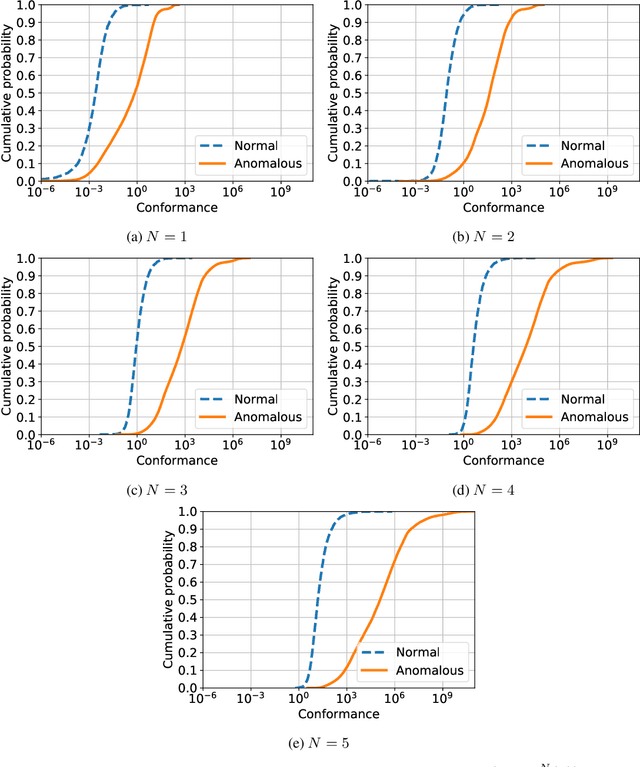
We introduce powerful but simple methodology for identifying anomalous observations against a corpus of `normal' observations. All data are observed through a vector-valued feature map. Our approach depends on the choice of corpus and that feature map but is invariant to affine transformations of the map and has no other external dependencies, such as choices of metric; we call it conformance. Applying this method to (signatures) of time series and other types of streamed data we provide an effective methodology of broad applicability for identifying anomalous complex multimodal sequential data. We demonstrate the applicability and effectiveness of our method by evaluating it against multiple data sets. Based on quantifying performance using the receiver operating characteristic (ROC) area under the curve (AUC), our method yields an AUC score of 98.9\% for the PenDigits data set; in a subsequent experiment involving marine vessel traffic data our approach yields an AUC score of 89.1\%. Based on comparison involving univariate time series from the UEA \& UCR time series repository with performance quantified using balanced accuracy and assuming an optimal operating point, our approach outperforms a state-of-the-art shapelet method for 19 out of 28 data sets.
Unsupervised Feature Learning Based on Deep Models for Environmental Audio Tagging
Nov 29, 2016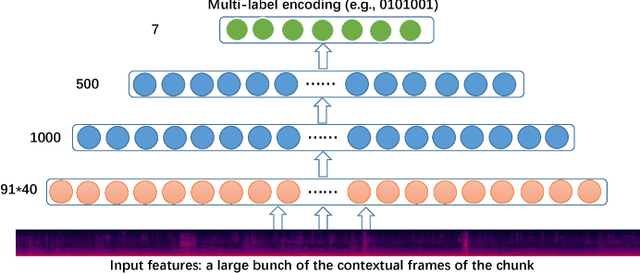
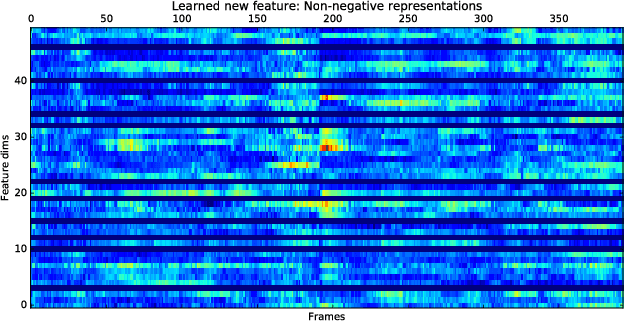
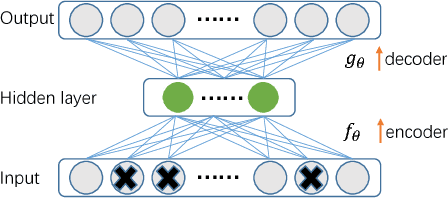
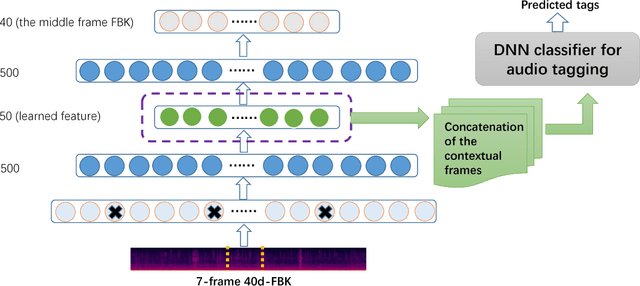
Environmental audio tagging aims to predict only the presence or absence of certain acoustic events in the interested acoustic scene. In this paper we make contributions to audio tagging in two parts, respectively, acoustic modeling and feature learning. We propose to use a shrinking deep neural network (DNN) framework incorporating unsupervised feature learning to handle the multi-label classification task. For the acoustic modeling, a large set of contextual frames of the chunk are fed into the DNN to perform a multi-label classification for the expected tags, considering that only chunk (or utterance) level rather than frame-level labels are available. Dropout and background noise aware training are also adopted to improve the generalization capability of the DNNs. For the unsupervised feature learning, we propose to use a symmetric or asymmetric deep de-noising auto-encoder (sDAE or aDAE) to generate new data-driven features from the Mel-Filter Banks (MFBs) features. The new features, which are smoothed against background noise and more compact with contextual information, can further improve the performance of the DNN baseline. Compared with the standard Gaussian Mixture Model (GMM) baseline of the DCASE 2016 audio tagging challenge, our proposed method obtains a significant equal error rate (EER) reduction from 0.21 to 0.13 on the development set. The proposed aDAE system can get a relative 6.7% EER reduction compared with the strong DNN baseline on the development set. Finally, the results also show that our approach obtains the state-of-the-art performance with 0.15 EER on the evaluation set of the DCASE 2016 audio tagging task while EER of the first prize of this challenge is 0.17.
* 10 pages, dcase 2016 challenge
Identifying Cover Songs Using Information-Theoretic Measures of Similarity
May 17, 2015

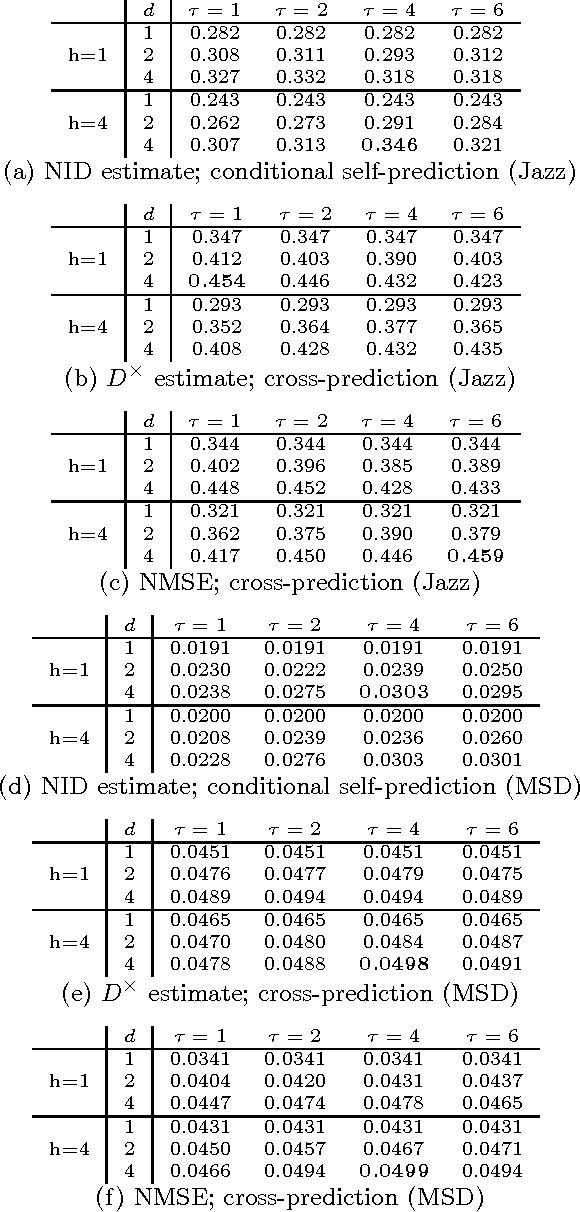
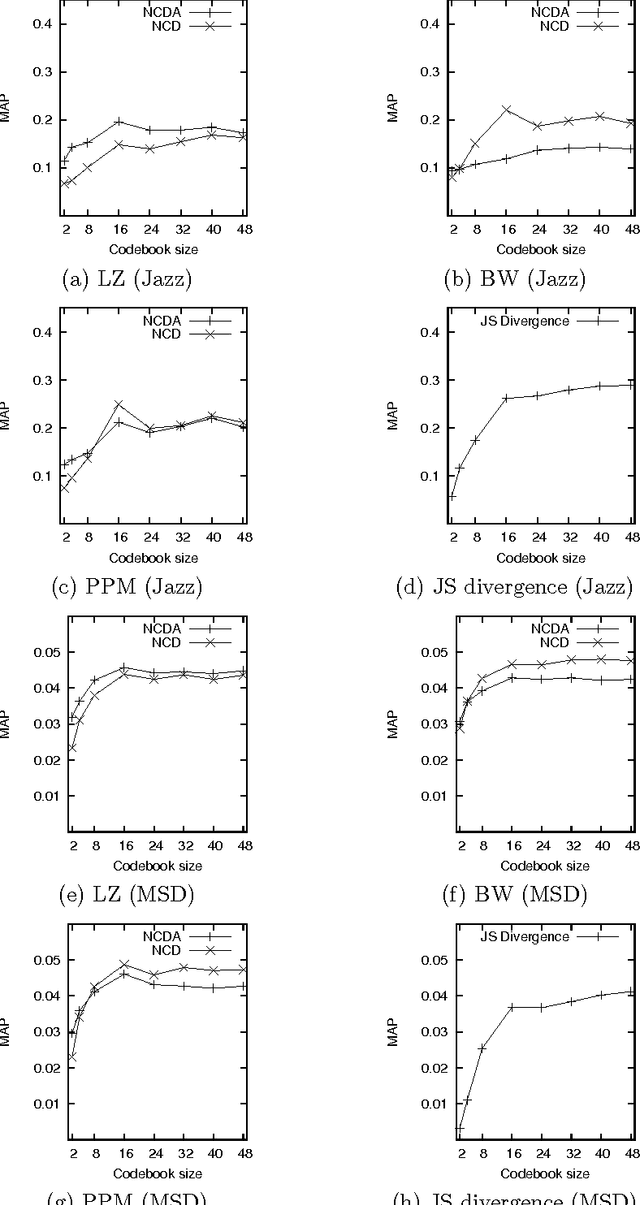
This paper investigates methods for quantifying similarity between audio signals, specifically for the task of of cover song detection. We consider an information-theoretic approach, where we compute pairwise measures of predictability between time series. We compare discrete-valued approaches operating on quantised audio features, to continuous-valued approaches. In the discrete case, we propose a method for computing the normalised compression distance, where we account for correlation between time series. In the continuous case, we propose to compute information-based measures of similarity as statistics of the prediction error between time series. We evaluate our methods on two cover song identification tasks using a data set comprised of 300 Jazz standards and using the Million Song Dataset. For both datasets, we observe that continuous-valued approaches outperform discrete-valued approaches. We consider approaches to estimating the normalised compression distance (NCD) based on string compression and prediction, where we observe that our proposed normalised compression distance with alignment (NCDA) improves average performance over NCD, for sequential compression algorithms. Finally, we demonstrate that continuous-valued distances may be combined to improve performance with respect to baseline approaches. Using a large-scale filter-and-refine approach, we demonstrate state-of-the-art performance for cover song identification using the Million Song Dataset.
* 13 pages, 5 figures, 4 tables. v3: Accepted version
Sequential Complexity as a Descriptor for Musical Similarity
Sep 28, 2014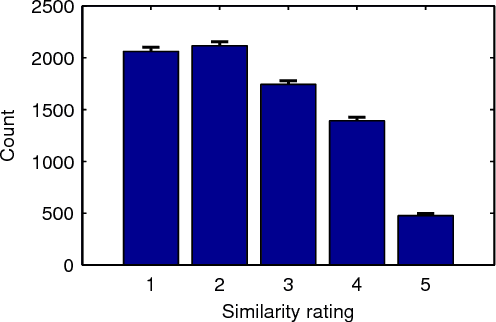

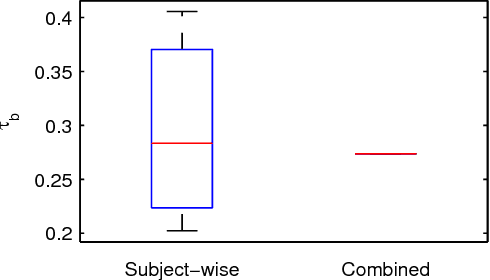

We propose string compressibility as a descriptor of temporal structure in audio, for the purpose of determining musical similarity. Our descriptors are based on computing track-wise compression rates of quantised audio features, using multiple temporal resolutions and quantisation granularities. To verify that our descriptors capture musically relevant information, we incorporate our descriptors into similarity rating prediction and song year prediction tasks. We base our evaluation on a dataset of 15500 track excerpts of Western popular music, for which we obtain 7800 web-sourced pairwise similarity ratings. To assess the agreement among similarity ratings, we perform an evaluation under controlled conditions, obtaining a rank correlation of 0.33 between intersected sets of ratings. Combined with bag-of-features descriptors, we obtain performance gains of 31.1% and 10.9% for similarity rating prediction and song year prediction. For both tasks, analysis of selected descriptors reveals that representing features at multiple time scales benefits prediction accuracy.
* 13 pages, 9 figures, 8 tables. Accepted version