 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFretNet: Continuous-Valued Pitch Contour Streaming for Polyphonic Guitar Tablature Transcription
Dec 06, 2022In recent years, the task of Automatic Music Transcription (AMT), whereby various attributes of music notes are estimated from audio, has received increasing attention. At the same time, the related task of Multi-Pitch Estimation (MPE) remains a challenging but necessary component of almost all AMT approaches, even if only implicitly. In the context of AMT, pitch information is typically quantized to the nominal pitches of the Western music scale. Even in more general contexts, MPE systems typically produce pitch predictions with some degree of quantization. In certain applications of AMT, such as Guitar Tablature Transcription (GTT), it is more meaningful to estimate continuous-valued pitch contours. Guitar tablature has the capacity to represent various playing techniques, some of which involve pitch modulation. Contemporary approaches to AMT do not adequately address pitch modulation, and offer only less quantization at the expense of more model complexity. In this paper, we present a GTT formulation that estimates continuous-valued pitch contours, grouping them according to their string and fret of origin. We demonstrate that for this task, the proposed method significantly improves the resolution of MPE and simultaneously yields tablature estimation results competitive with baseline models.
Identifying Cover Songs Using Information-Theoretic Measures of Similarity
May 17, 2015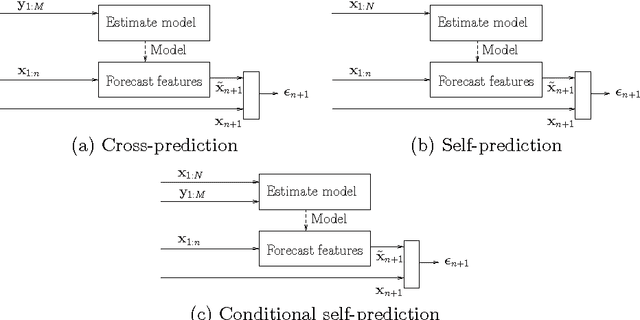

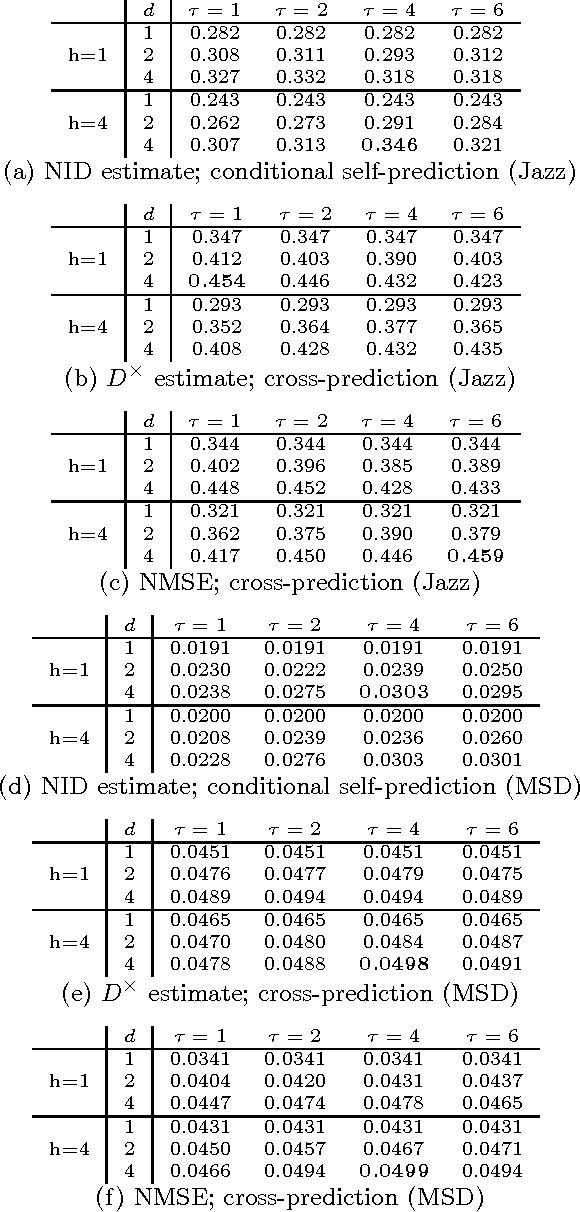
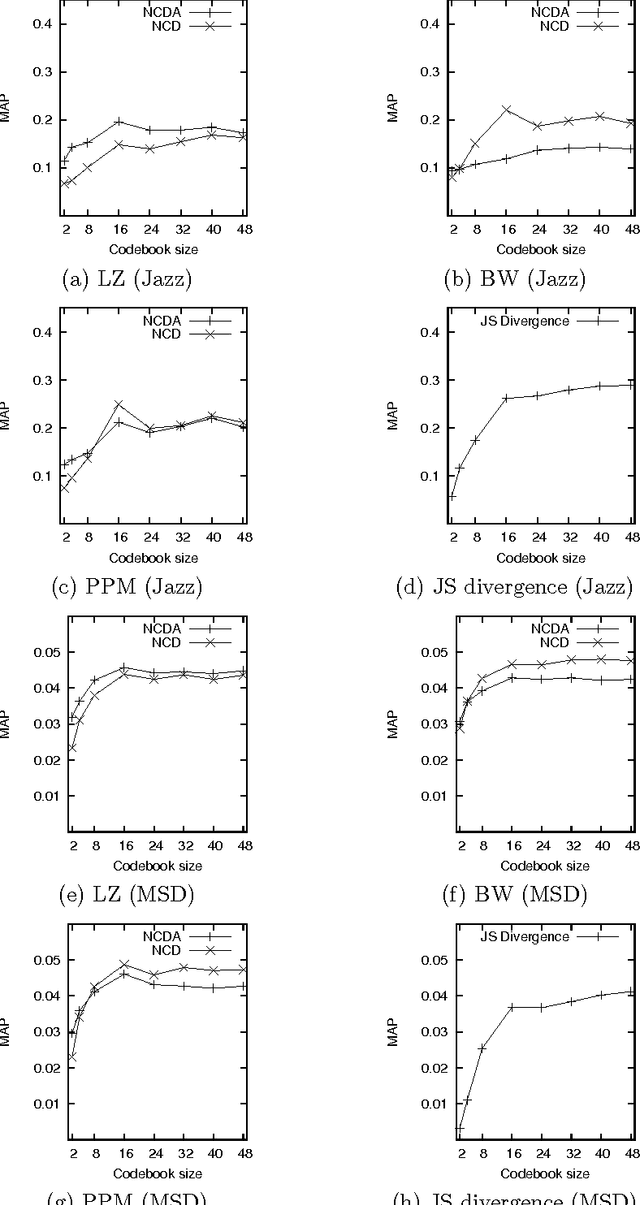
This paper investigates methods for quantifying similarity between audio signals, specifically for the task of of cover song detection. We consider an information-theoretic approach, where we compute pairwise measures of predictability between time series. We compare discrete-valued approaches operating on quantised audio features, to continuous-valued approaches. In the discrete case, we propose a method for computing the normalised compression distance, where we account for correlation between time series. In the continuous case, we propose to compute information-based measures of similarity as statistics of the prediction error between time series. We evaluate our methods on two cover song identification tasks using a data set comprised of 300 Jazz standards and using the Million Song Dataset. For both datasets, we observe that continuous-valued approaches outperform discrete-valued approaches. We consider approaches to estimating the normalised compression distance (NCD) based on string compression and prediction, where we observe that our proposed normalised compression distance with alignment (NCDA) improves average performance over NCD, for sequential compression algorithms. Finally, we demonstrate that continuous-valued distances may be combined to improve performance with respect to baseline approaches. Using a large-scale filter-and-refine approach, we demonstrate state-of-the-art performance for cover song identification using the Million Song Dataset.
* 13 pages, 5 figures, 4 tables. v3: Accepted version