 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Data-driven Market Simulator for Small Data Environments
Jun 21, 2020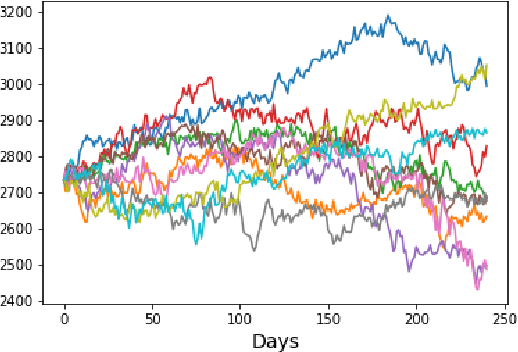
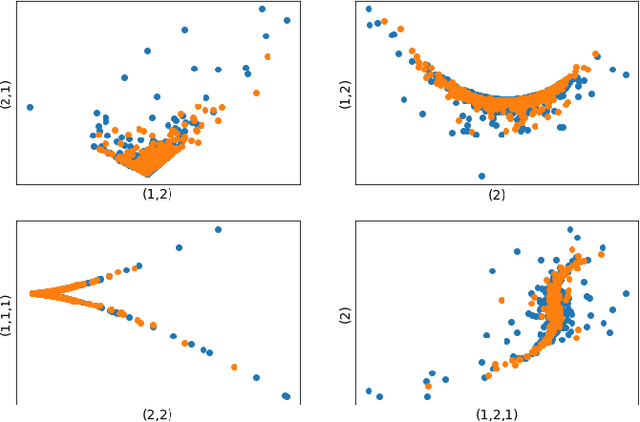
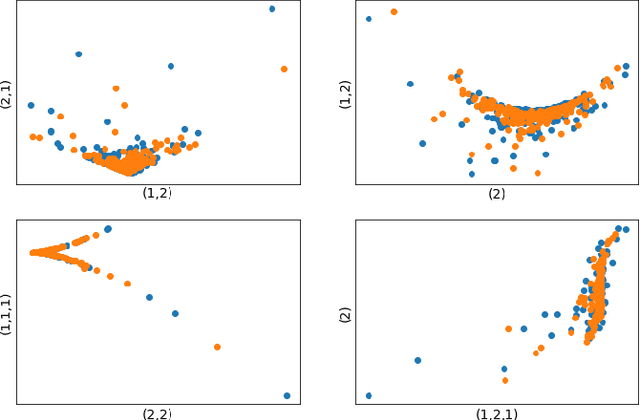
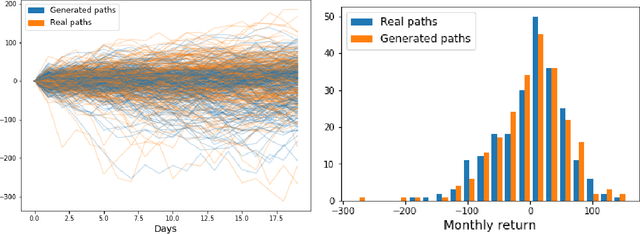
Neural network based data-driven market simulation unveils a new and flexible way of modelling financial time series without imposing assumptions on the underlying stochastic dynamics. Though in this sense generative market simulation is model-free, the concrete modelling choices are nevertheless decisive for the features of the simulated paths. We give a brief overview of currently used generative modelling approaches and performance evaluation metrics for financial time series, and address some of the challenges to achieve good results in the latter. We also contrast some classical approaches of market simulation with simulation based on generative modelling and highlight some advantages and pitfalls of the new approach. While most generative models tend to rely on large amounts of training data, we present here a generative model that works reliably in environments where the amount of available training data is notoriously small. Furthermore, we show how a rough paths perspective combined with a parsimonious Variational Autoencoder framework provides a powerful way for encoding and evaluating financial time series in such environments where available training data is scarce. Finally, we also propose a suitable performance evaluation metric for financial time series and discuss some connections of our Market Generator to deep hedging.
Anomaly detection on streamed data
Jun 05, 2020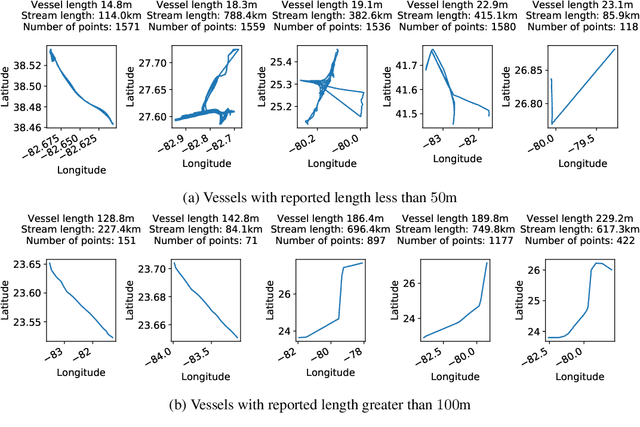

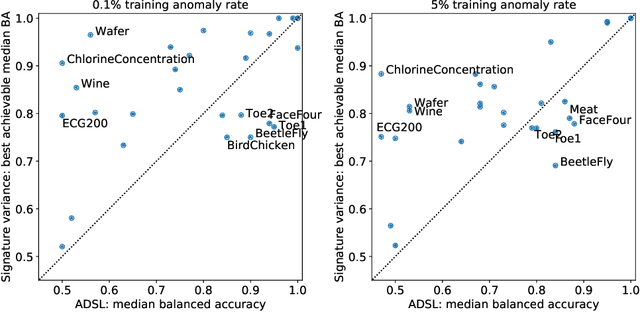
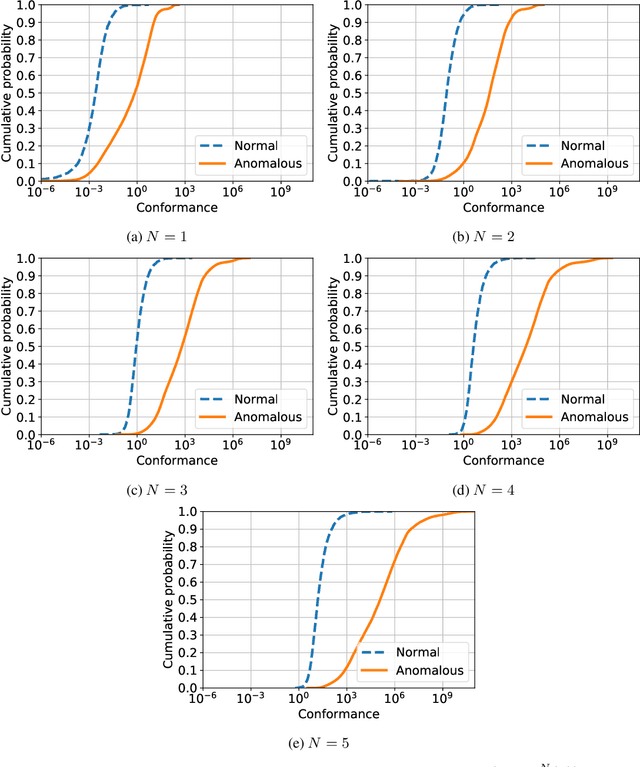
We introduce powerful but simple methodology for identifying anomalous observations against a corpus of `normal' observations. All data are observed through a vector-valued feature map. Our approach depends on the choice of corpus and that feature map but is invariant to affine transformations of the map and has no other external dependencies, such as choices of metric; we call it conformance. Applying this method to (signatures) of time series and other types of streamed data we provide an effective methodology of broad applicability for identifying anomalous complex multimodal sequential data. We demonstrate the applicability and effectiveness of our method by evaluating it against multiple data sets. Based on quantifying performance using the receiver operating characteristic (ROC) area under the curve (AUC), our method yields an AUC score of 98.9\% for the PenDigits data set; in a subsequent experiment involving marine vessel traffic data our approach yields an AUC score of 89.1\%. Based on comparison involving univariate time series from the UEA \& UCR time series repository with performance quantified using balanced accuracy and assuming an optimal operating point, our approach outperforms a state-of-the-art shapelet method for 19 out of 28 data sets.
Deep Signatures
May 21, 2019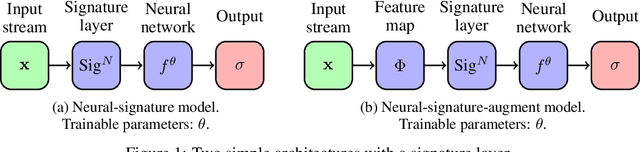
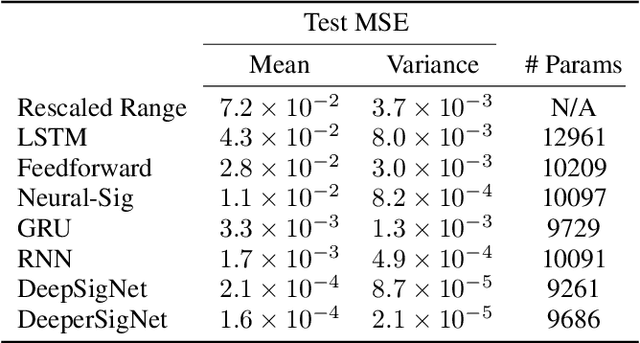


The signature is an infinite graded sequence of statistics known to characterise a stream of data up to a negligible equivalence class. It is a transform which has previously been treated as a fixed feature transformation, on top of which a model may be built. We propose a novel approach which combines the advantages of the signature transform with modern deep learning frameworks. By learning an augmentation of the stream prior to the signature transform, the terms of the signature may be selected in a data-dependent way. More generally, we describe how the signature transform may be used as a layer anywhere within a neural network. In this context it may be interpreted as an activation function not operating element-wise. We present the results of empirical experiments to back up the theoretical justification. Code available at github.com/patrick-kidger/Deep-Signatures.
Labelling as an unsupervised learning problem
May 30, 2018

Unravelling hidden patterns in datasets is a classical problem with many potential applications. In this paper, we present a challenge whose objective is to discover nonlinear relationships in noisy cloud of points. If a set of point satisfies a nonlinear relationship that is unlikely to be due to randomness, we will label the set with this relationship. Since points can satisfy one, many or no such nonlinear relationships, cloud of points will typically have one, multiple or no labels at all. This introduces the labelling problem that will be studied in this paper. The objective of this paper is to develop a framework for the labelling problem. We introduce a precise notion of a label, and we propose an algorithm to discover such labels in a given dataset, which is then tested in synthetic datasets. We also analyse, using tools from random matrix theory, the problem of discovering false labels in the dataset.
A signature-based machine learning model for bipolar disorder and borderline personality disorder
Oct 04, 2017
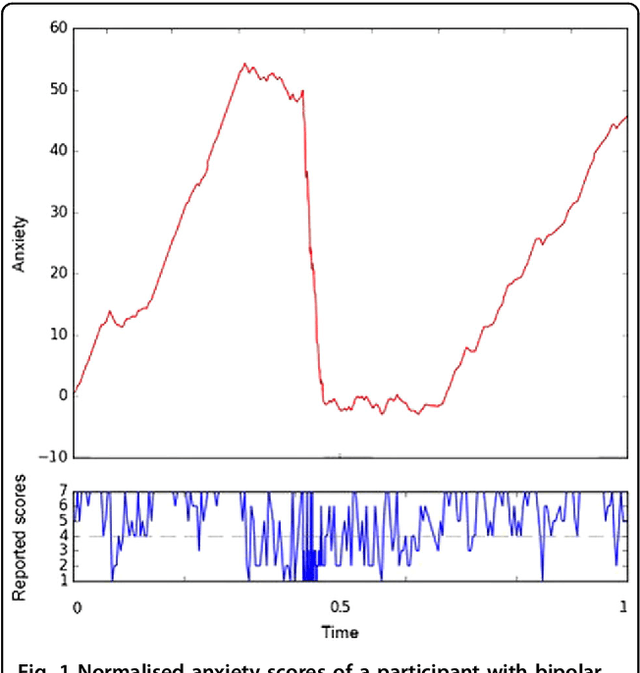
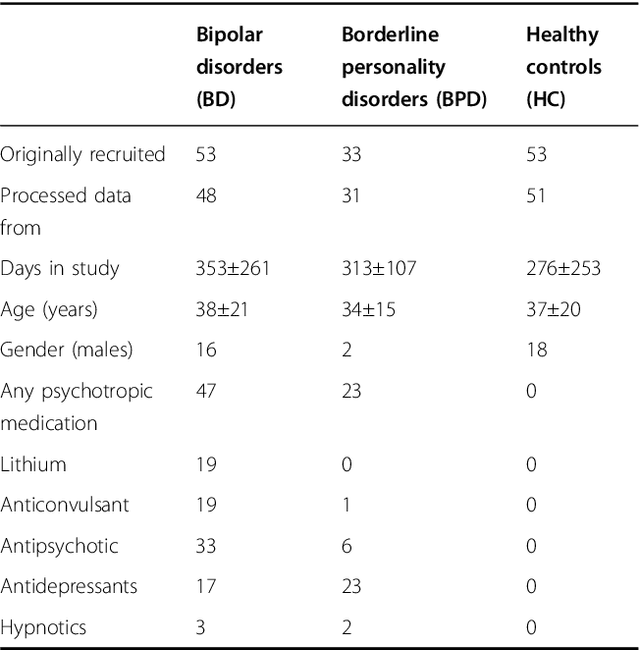
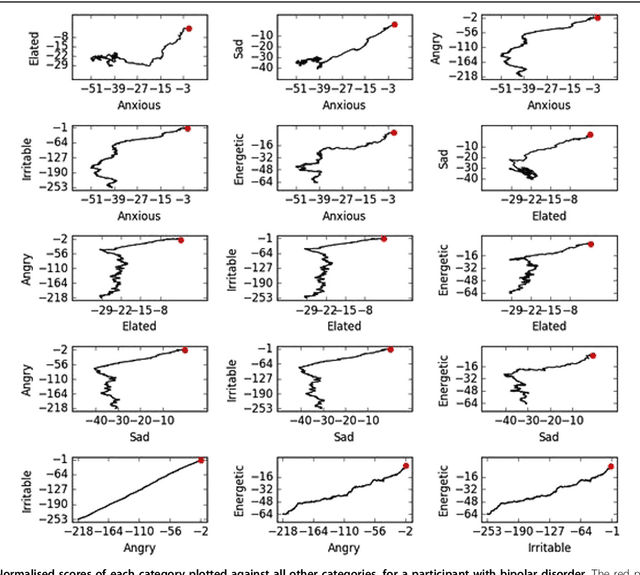
Mobile technologies offer opportunities for higher resolution monitoring of health conditions. This opportunity seems of particular promise in psychiatry where diagnoses often rely on retrospective and subjective recall of mood states. However, getting actionable information from these rather complex time series is challenging, and at present the implications for clinical care are largely hypothetical. This research demonstrates that, with well chosen cohorts (of bipolar disorder, borderline personality disorder, and control) and modern methods, it is possible to objectively learn to identify distinctive behaviour over short periods (20 reports) that effectively separate the cohorts. Participants with bipolar disorder or borderline personality disorder and healthy volunteers completed daily mood ratings using a bespoke smartphone app for up to a year. A signature-based machine learning model was used to classify participants on the basis of the interrelationship between the different mood items assessed and to predict subsequent mood. The signature methodology was significantly superior to earlier statistical approaches applied to this data in distinguishing the participant three groups, clearly placing 75% into their original groups on the basis of their reports. Subsequent mood ratings were correctly predicted with greater than 70% accuracy in all groups. Prediction of mood was most accurate in healthy volunteers (89-98%) compared to bipolar disorder (82-90%) and borderline personality disorder (70-78%).