 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResource-constrained stereo singing voice cancellation
Jan 22, 2024We study the problem of stereo singing voice cancellation, a subtask of music source separation, whose goal is to estimate an instrumental background from a stereo mix. We explore how to achieve performance similar to large state-of-the-art source separation networks starting from a small, efficient model for real-time speech separation. Such a model is useful when memory and compute are limited and singing voice processing has to run with limited look-ahead. In practice, this is realised by adapting an existing mono model to handle stereo input. Improvements in quality are obtained by tuning model parameters and expanding the training set. Moreover, we highlight the benefits a stereo model brings by introducing a new metric which detects attenuation inconsistencies between channels. Our approach is evaluated using objective offline metrics and a large-scale MUSHRA trial, confirming the effectiveness of our techniques in stringent listening tests.
Multi-objective Hyper-parameter Optimization of Behavioral Song Embeddings
Aug 26, 2022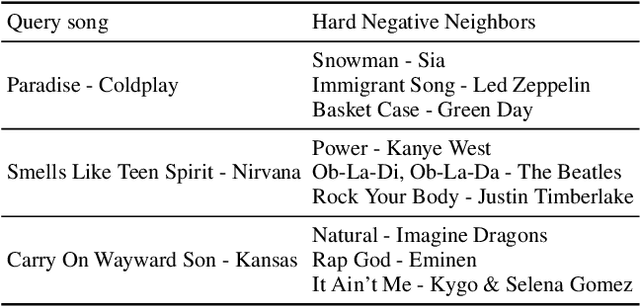
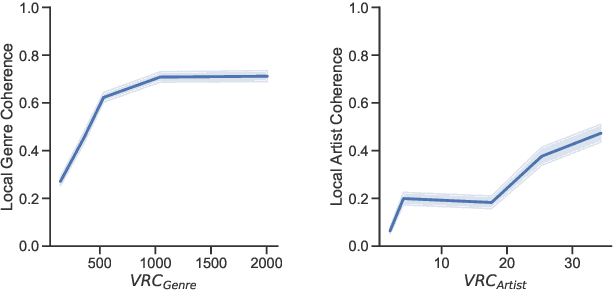
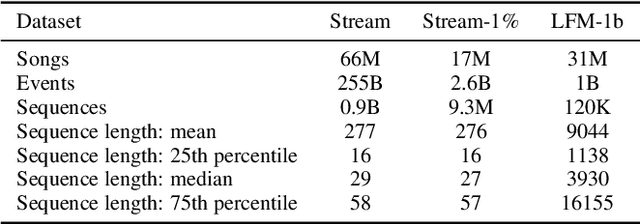
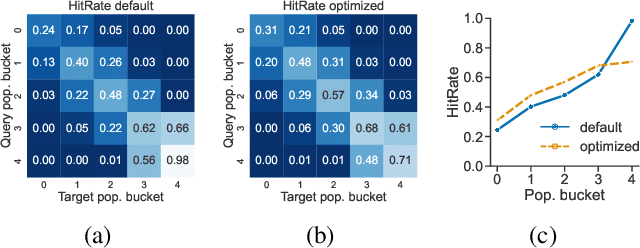
Song embeddings are a key component of most music recommendation engines. In this work, we study the hyper-parameter optimization of behavioral song embeddings based on Word2Vec on a selection of downstream tasks, namely next-song recommendation, false neighbor rejection, and artist and genre clustering. We present new optimization objectives and metrics to monitor the effects of hyper-parameter optimization. We show that single-objective optimization can cause side effects on the non optimized metrics and propose a simple multi-objective optimization to mitigate these effects. We find that next-song recommendation quality of Word2Vec is anti-correlated with song popularity, and we show how song embedding optimization can balance performance across different popularity levels. We then show potential positive downstream effects on the task of play prediction. Finally, we provide useful insights on the effects of training dataset scale by testing hyper-parameter optimization on an industry-scale dataset.
Lyric document embeddings for music tagging
Nov 29, 2021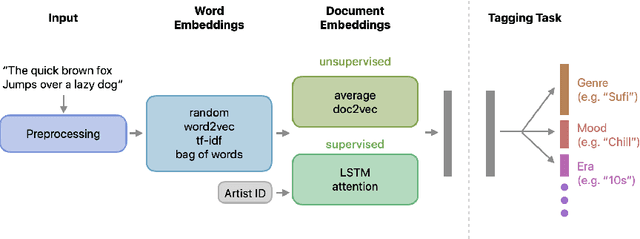
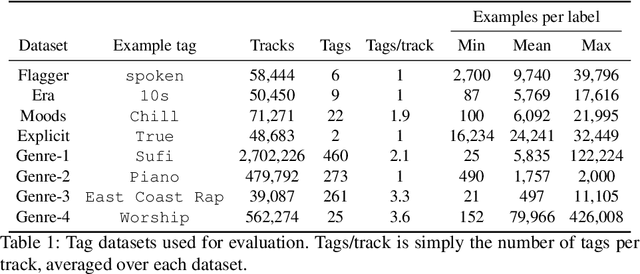
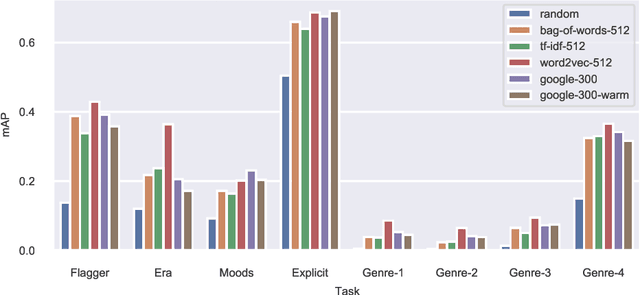
We present an empirical study on embedding the lyrics of a song into a fixed-dimensional feature for the purpose of music tagging. Five methods of computing token-level and four methods of computing document-level representations are trained on an industrial-scale dataset of tens of millions of songs. We compare simple averaging of pretrained embeddings to modern recurrent and attention-based neural architectures. Evaluating on a wide range of tagging tasks such as genre classification, explicit content identification and era detection, we find that averaging word embeddings outperform more complex architectures in many downstream metrics.
Downbeat Tracking with Tempo-Invariant Convolutional Neural Networks
Feb 03, 2021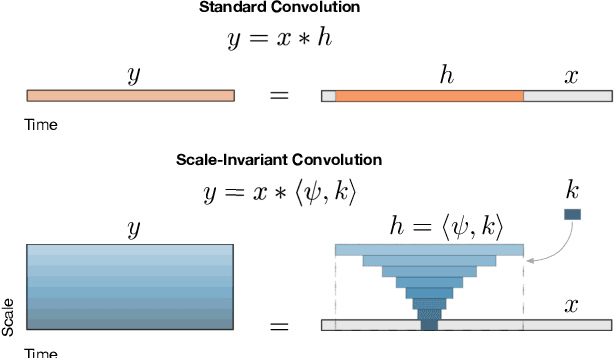

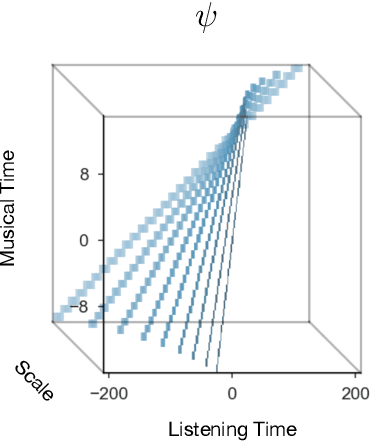
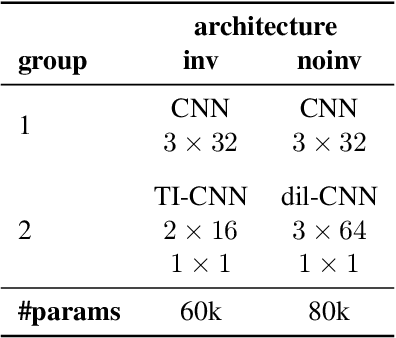
The human ability to track musical downbeats is robust to changes in tempo, and it extends to tempi never previously encountered. We propose a deterministic time-warping operation that enables this skill in a convolutional neural network (CNN) by allowing the network to learn rhythmic patterns independently of tempo. Unlike conventional deep learning approaches, which learn rhythmic patterns at the tempi present in the training dataset, the patterns learned in our model are tempo-invariant, leading to better tempo generalisation and more efficient usage of the network capacity. We test the generalisation property on a synthetic dataset created by rendering the Groove MIDI Dataset using FluidSynth, split into a training set containing the original performances and a test set containing tempo-scaled versions rendered with different SoundFonts (test-time augmentation). The proposed model generalises nearly perfectly to unseen tempi (F-measure of 0.89 on both training and test sets), whereas a comparable conventional CNN achieves similar accuracy only for the training set (0.89) and drops to 0.54 on the test set. The generalisation advantage of the proposed model extends to real music, as shown by results on the GTZAN and Ballroom datasets.
* 7 pages, 5 figures, Proceedings of the 21st International Society for Music Information Retrieval Conference, ISMIR 2020
Sequential Complexity as a Descriptor for Musical Similarity
Sep 28, 2014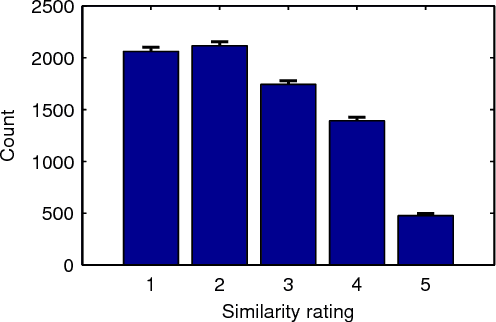

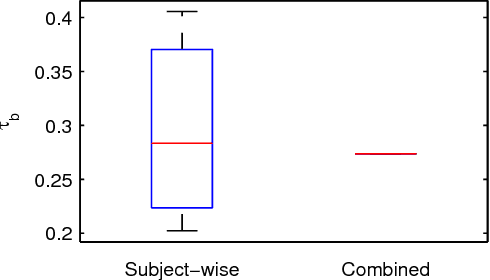

We propose string compressibility as a descriptor of temporal structure in audio, for the purpose of determining musical similarity. Our descriptors are based on computing track-wise compression rates of quantised audio features, using multiple temporal resolutions and quantisation granularities. To verify that our descriptors capture musically relevant information, we incorporate our descriptors into similarity rating prediction and song year prediction tasks. We base our evaluation on a dataset of 15500 track excerpts of Western popular music, for which we obtain 7800 web-sourced pairwise similarity ratings. To assess the agreement among similarity ratings, we perform an evaluation under controlled conditions, obtaining a rank correlation of 0.33 between intersected sets of ratings. Combined with bag-of-features descriptors, we obtain performance gains of 31.1% and 10.9% for similarity rating prediction and song year prediction. For both tasks, analysis of selected descriptors reveals that representing features at multiple time scales benefits prediction accuracy.
* 13 pages, 9 figures, 8 tables. Accepted version