 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControllable Music Production with Diffusion Models and Guidance Gradients
Nov 01, 2023


We demonstrate how conditional generation from diffusion models can be used to tackle a variety of realistic tasks in the production of music in 44.1kHz stereo audio with sampling-time guidance. The scenarios we consider include continuation, inpainting and regeneration of musical audio, the creation of smooth transitions between two different music tracks, and the transfer of desired stylistic characteristics to existing audio clips. We achieve this by applying guidance at sampling time in a simple framework that supports both reconstruction and classification losses, or any combination of the two. This approach ensures that generated audio can match its surrounding context, or conform to a class distribution or latent representation specified relative to any suitable pre-trained classifier or embedding model.
Mel Spectrogram Inversion with Stable Pitch
Aug 26, 2022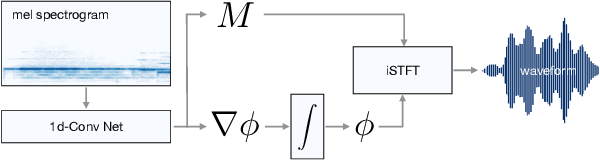
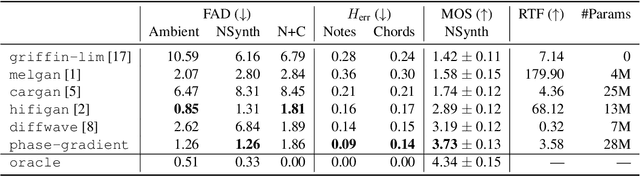
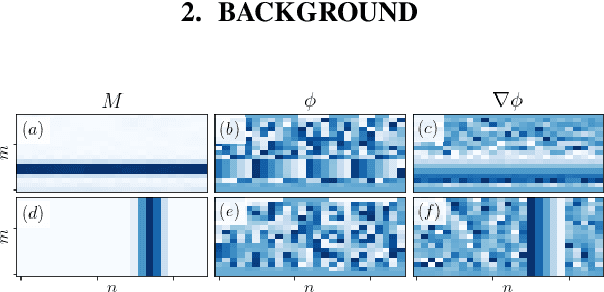
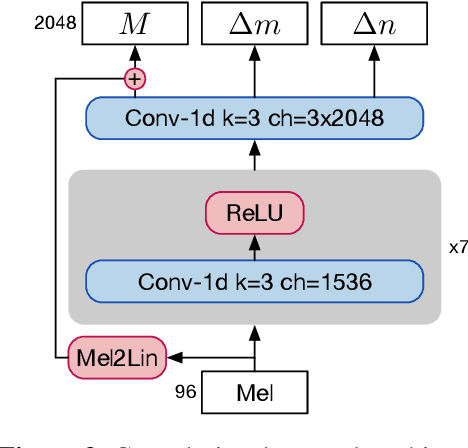
Vocoders are models capable of transforming a low-dimensional spectral representation of an audio signal, typically the mel spectrogram, to a waveform. Modern speech generation pipelines use a vocoder as their final component. Recent vocoder models developed for speech achieve a high degree of realism, such that it is natural to wonder how they would perform on music signals. Compared to speech, the heterogeneity and structure of the musical sound texture offers new challenges. In this work we focus on one specific artifact that some vocoder models designed for speech tend to exhibit when applied to music: the perceived instability of pitch when synthesizing sustained notes. We argue that the characteristic sound of this artifact is due to the lack of horizontal phase coherence, which is often the result of using a time-domain target space with a model that is invariant to time-shifts, such as a convolutional neural network. We propose a new vocoder model that is specifically designed for music. Key to improving the pitch stability is the choice of a shift-invariant target space that consists of the magnitude spectrum and the phase gradient. We discuss the reasons that inspired us to re-formulate the vocoder task, outline a working example, and evaluate it on musical signals. Our method results in 60% and 10% improved reconstruction of sustained notes and chords with respect to existing models, using a novel harmonic error metric.
Downbeat Tracking with Tempo-Invariant Convolutional Neural Networks
Feb 03, 2021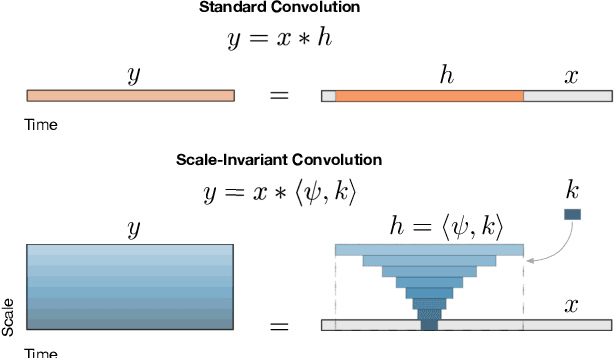

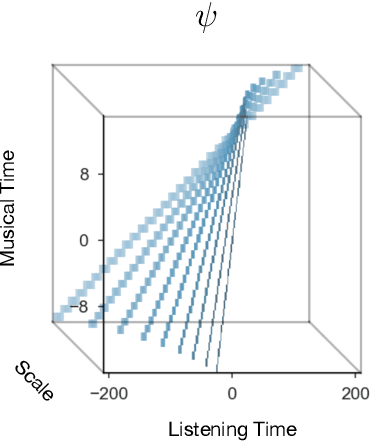
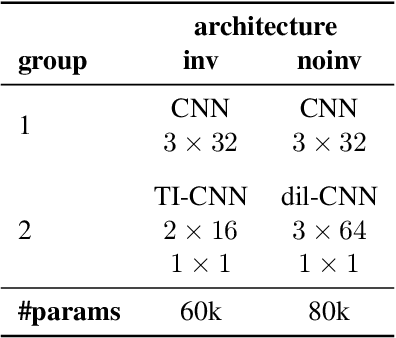
The human ability to track musical downbeats is robust to changes in tempo, and it extends to tempi never previously encountered. We propose a deterministic time-warping operation that enables this skill in a convolutional neural network (CNN) by allowing the network to learn rhythmic patterns independently of tempo. Unlike conventional deep learning approaches, which learn rhythmic patterns at the tempi present in the training dataset, the patterns learned in our model are tempo-invariant, leading to better tempo generalisation and more efficient usage of the network capacity. We test the generalisation property on a synthetic dataset created by rendering the Groove MIDI Dataset using FluidSynth, split into a training set containing the original performances and a test set containing tempo-scaled versions rendered with different SoundFonts (test-time augmentation). The proposed model generalises nearly perfectly to unseen tempi (F-measure of 0.89 on both training and test sets), whereas a comparable conventional CNN achieves similar accuracy only for the training set (0.89) and drops to 0.54 on the test set. The generalisation advantage of the proposed model extends to real music, as shown by results on the GTZAN and Ballroom datasets.
* 7 pages, 5 figures, Proceedings of the 21st International Society for Music Information Retrieval Conference, ISMIR 2020