 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Splitting of Language Models from Mixtures to Specialized Domains
Mar 19, 2026Language models achieve impressive performance on a variety of knowledge, language, and reasoning tasks due to the scale and diversity of pretraining data available. The standard training recipe is a two-stage paradigm: pretraining first on the full corpus of data followed by specialization on a subset of high quality, specialized data from the full corpus. In the multi-domain setting, this involves continued pretraining of multiple models on each specialized domain, referred to as split model training. We propose a method for pretraining multiple models independently over a general pretraining corpus, and determining the optimal compute allocation between pretraining and continued pretraining using scaling laws. Our approach accurately predicts the loss of a model of size N with D pretraining and D' specialization tokens, and extrapolates to larger model sizes and number of tokens. Applied to language model training, our approach improves performance consistently across common sense knowledge and reasoning benchmarks across different model sizes and compute budgets.
Partial Parameter Updates for Efficient Distributed Training
Sep 26, 2025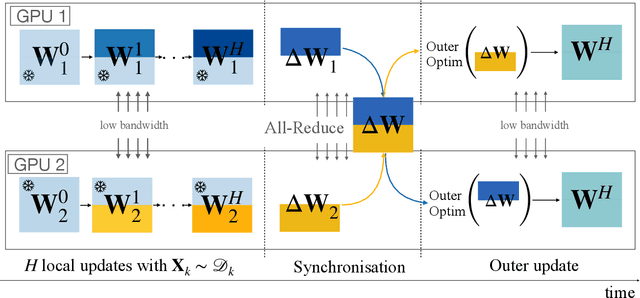
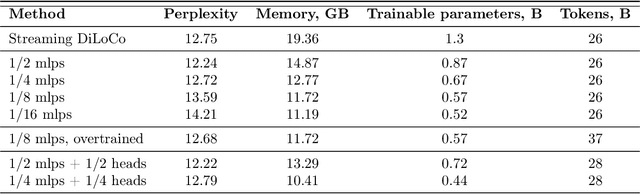
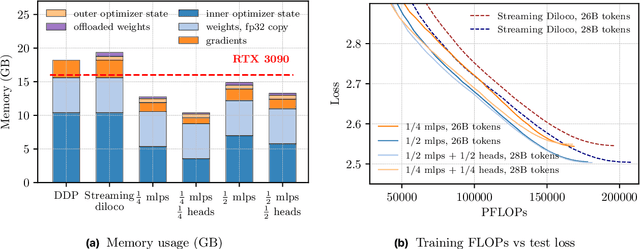
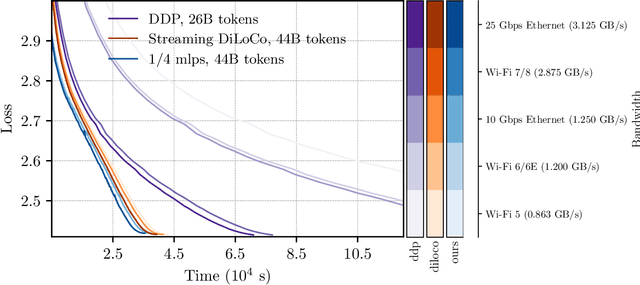
We introduce a memory- and compute-efficient method for low-communication distributed training. Existing methods reduce communication by performing multiple local updates between infrequent global synchronizations. We demonstrate that their efficiency can be significantly improved by restricting backpropagation: instead of updating all the parameters, each node updates only a fixed subset while keeping the remainder frozen during local steps. This constraint substantially reduces peak memory usage and training FLOPs, while a full forward pass over all parameters eliminates the need for cross-node activation exchange. Experiments on a $1.3$B-parameter language model trained across $32$ nodes show that our method matches the perplexity of prior low-communication approaches under identical token and bandwidth budgets while reducing training FLOPs and peak memory.
Soup-of-Experts: Pretraining Specialist Models via Parameters Averaging
Feb 03, 2025Machine learning models are routinely trained on a mixture of different data domains. Different domain weights yield very different downstream performances. We propose the Soup-of-Experts, a novel architecture that can instantiate a model at test time for any domain weights with minimal computational cost and without re-training the model. Our architecture consists of a bank of expert parameters, which are linearly combined to instantiate one model. We learn the linear combination coefficients as a function of the input domain weights. To train this architecture, we sample random domain weights, instantiate the corresponding model, and backprop through one batch of data sampled with these domain weights. We demonstrate how our approach obtains small specialized models on several language modeling tasks quickly. Soup-of-Experts are particularly appealing when one needs to ship many different specialist models quickly under a model size constraint.
No Need to Talk: Asynchronous Mixture of Language Models
Oct 04, 2024

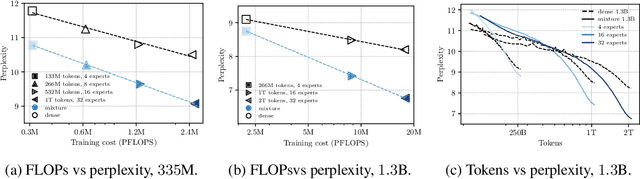
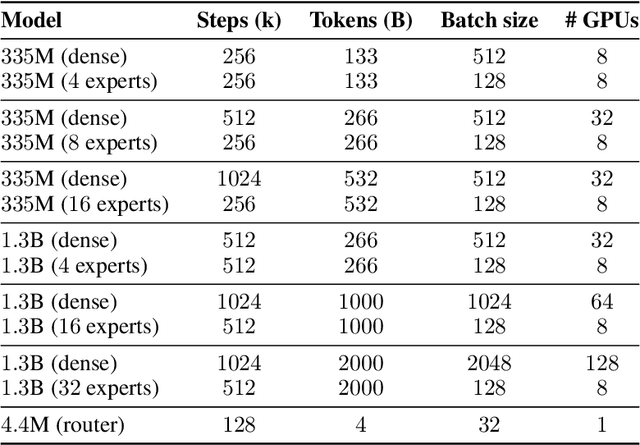
We introduce SmallTalk LM, an innovative method for training a mixture of language models in an almost asynchronous manner. Each model of the mixture specializes in distinct parts of the data distribution, without the need of high-bandwidth communication between the nodes training each model. At inference, a lightweight router directs a given sequence to a single expert, according to a short prefix. This inference scheme naturally uses a fraction of the parameters from the overall mixture model. Our experiments on language modeling demonstrate tha SmallTalk LM achieves significantly lower perplexity than dense model baselines for the same total training FLOPs and an almost identical inference cost. Finally, in our downstream evaluations we outperform the dense baseline on $75\%$ of the tasks.
Specialized Language Models with Cheap Inference from Limited Domain Data
Feb 02, 2024



Large language models have emerged as a versatile tool but are challenging to apply to tasks lacking large inference budgets and large in-domain training sets. This work formalizes these constraints and distinguishes four important variables: the pretraining budget (for training before the target domain is known), the specialization budget (for training after the target domain is known), the inference budget, and the in-domain training set size. Across these settings, we compare different approaches from the machine learning literature. Limited by inference cost, we find better alternatives to the standard practice of training very large vanilla transformer models. In particular, we show that hyper-networks and mixture of experts have better perplexity for large pretraining budgets, while small models trained on importance sampled datasets are attractive for large specialization budgets.
Controllable Music Production with Diffusion Models and Guidance Gradients
Nov 01, 2023


We demonstrate how conditional generation from diffusion models can be used to tackle a variety of realistic tasks in the production of music in 44.1kHz stereo audio with sampling-time guidance. The scenarios we consider include continuation, inpainting and regeneration of musical audio, the creation of smooth transitions between two different music tracks, and the transfer of desired stylistic characteristics to existing audio clips. We achieve this by applying guidance at sampling time in a simple framework that supports both reconstruction and classification losses, or any combination of the two. This approach ensures that generated audio can match its surrounding context, or conform to a class distribution or latent representation specified relative to any suitable pre-trained classifier or embedding model.
Self Supervision Does Not Help Natural Language Supervision at Scale
Jan 20, 2023



Self supervision and natural language supervision have emerged as two exciting ways to train general purpose image encoders which excel at a variety of downstream tasks. Recent works such as M3AE and SLIP have suggested that these approaches can be effectively combined, but most notably their results use small pre-training datasets (<50M samples) and don't effectively reflect the large-scale regime (>100M examples) that is commonly used for these approaches. Here we investigate whether a similar approach can be effective when trained with a much larger amount of data. We find that a combination of two state of the art approaches: masked auto-encoders, MAE and contrastive language image pre-training, CLIP provides a benefit over CLIP when trained on a corpus of 11.3M image-text pairs, but little to no benefit (as evaluated on a suite of common vision tasks) over CLIP when trained on a large corpus of 1.4B images. Our work provides some much needed clarity into the effectiveness (or lack thereof) of self supervision for large-scale image-text training.
Neural Parts: Learning Expressive 3D Shape Abstractions with Invertible Neural Networks
Mar 18, 2021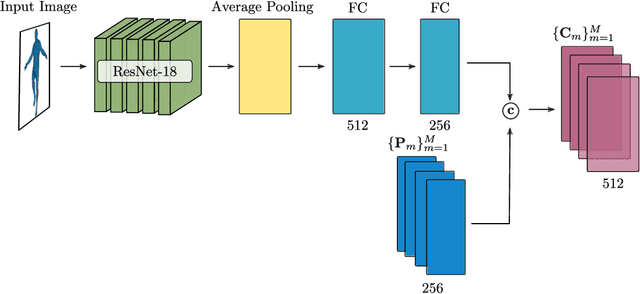

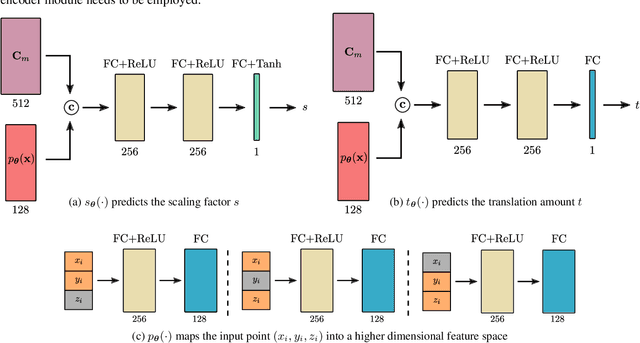

Impressive progress in 3D shape extraction led to representations that can capture object geometries with high fidelity. In parallel, primitive-based methods seek to represent objects as semantically consistent part arrangements. However, due to the simplicity of existing primitive representations, these methods fail to accurately reconstruct 3D shapes using a small number of primitives/parts. We address the trade-off between reconstruction quality and number of parts with Neural Parts, a novel 3D primitive representation that defines primitives using an Invertible Neural Network (INN) which implements homeomorphic mappings between a sphere and the target object. The INN allows us to compute the inverse mapping of the homeomorphism, which in turn, enables the efficient computation of both the implicit surface function of a primitive and its mesh, without any additional post-processing. Our model learns to parse 3D objects into semantically consistent part arrangements without any part-level supervision. Evaluations on ShapeNet, D-FAUST and FreiHAND demonstrate that our primitives can capture complex geometries and thus simultaneously achieve geometrically accurate as well as interpretable reconstructions using an order of magnitude fewer primitives than state-of-the-art shape abstraction methods.
Fast Transformers with Clustered Attention
Jul 09, 2020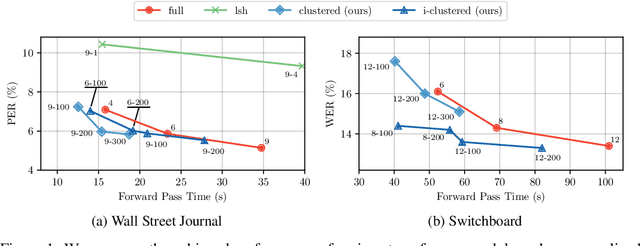
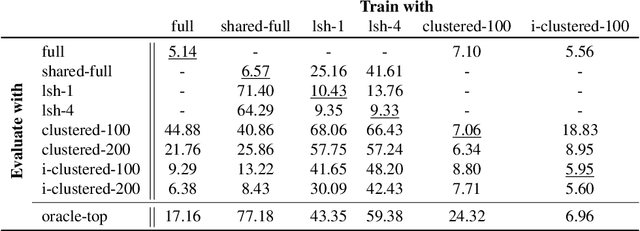

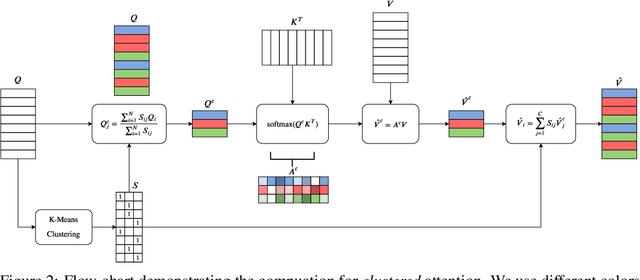
Transformers have been proven a successful model for a variety of tasks in sequence modeling. However, computing the attention matrix, which is their key component, has quadratic complexity with respect to the sequence length, thus making them prohibitively expensive for large sequences. To address this, we propose clustered attention, which instead of computing the attention for every query, groups queries into clusters and computes attention just for the centroids. To further improve this approximation, we use the computed clusters to identify the keys with the highest attention per query and compute the exact key/query dot products. This results in a model with linear complexity with respect to the sequence length for a fixed number of clusters. We evaluate our approach on two automatic speech recognition datasets and show that our model consistently outperforms vanilla transformers for a given computational budget. Finally, we demonstrate that our model can approximate arbitrarily complex attention distributions with a minimal number of clusters by approximating a pretrained BERT model on GLUE and SQuAD benchmarks with only 25 clusters and no loss in performance.
Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention
Jun 30, 2020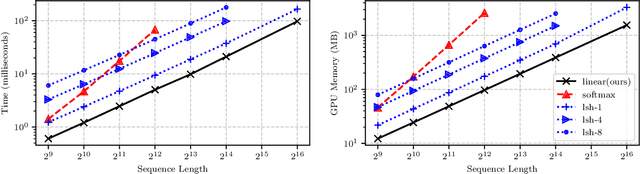
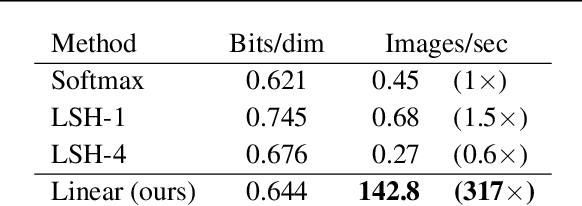
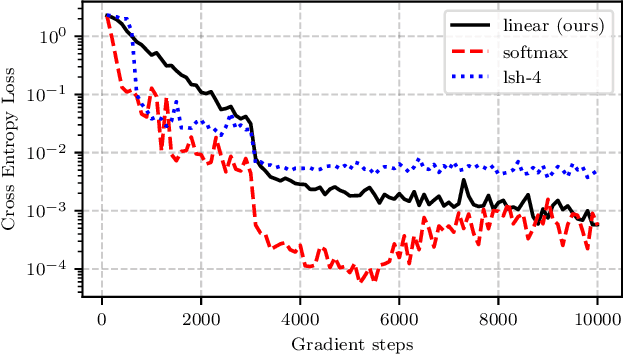
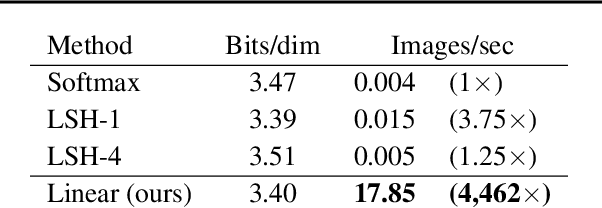
Transformers achieve remarkable performance in several tasks but due to their quadratic complexity, with respect to the input's length, they are prohibitively slow for very long sequences. To address this limitation, we express the self-attention as a linear dot-product of kernel feature maps and make use of the associativity property of matrix products to reduce the complexity from $\mathcal{O}\left(N^2\right)$ to $\mathcal{O}\left(N\right)$, where $N$ is the sequence length. We show that this formulation permits an iterative implementation that dramatically accelerates autoregressive transformers and reveals their relationship to recurrent neural networks. Our linear transformers achieve similar performance to vanilla transformers and they are up to 4000x faster on autoregressive prediction of very long sequences.