 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePartial Parameter Updates for Efficient Distributed Training
Sep 26, 2025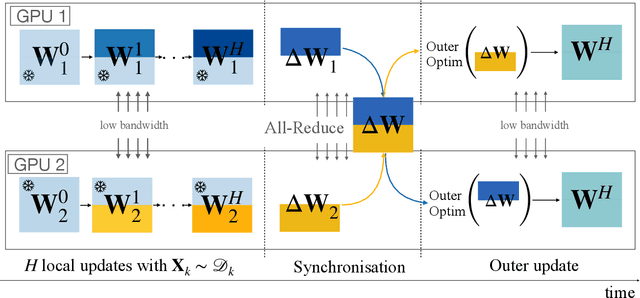
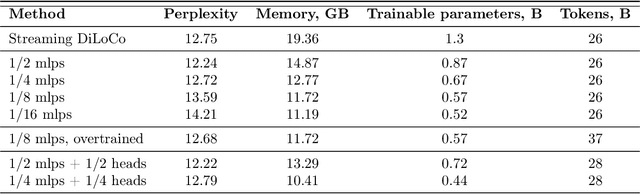
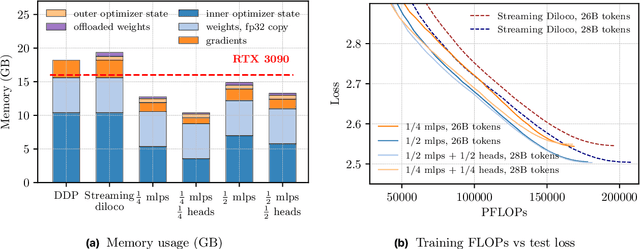
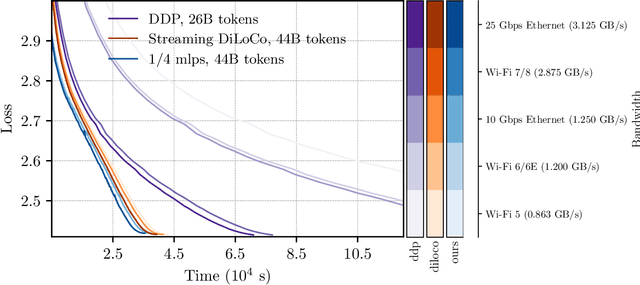
We introduce a memory- and compute-efficient method for low-communication distributed training. Existing methods reduce communication by performing multiple local updates between infrequent global synchronizations. We demonstrate that their efficiency can be significantly improved by restricting backpropagation: instead of updating all the parameters, each node updates only a fixed subset while keeping the remainder frozen during local steps. This constraint substantially reduces peak memory usage and training FLOPs, while a full forward pass over all parameters eliminates the need for cross-node activation exchange. Experiments on a $1.3$B-parameter language model trained across $32$ nodes show that our method matches the perplexity of prior low-communication approaches under identical token and bandwidth budgets while reducing training FLOPs and peak memory.
Time-series attribution maps with regularized contrastive learning
Feb 17, 2025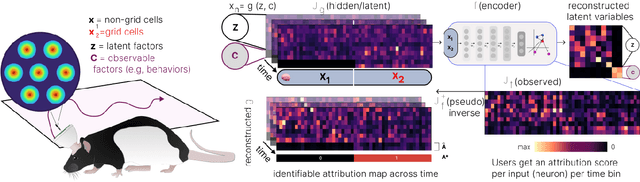
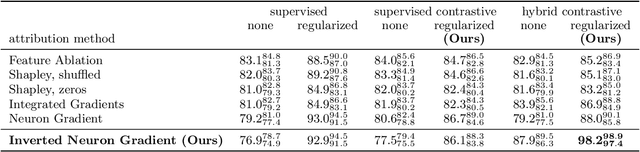
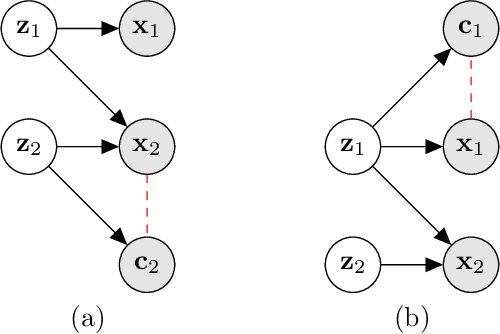
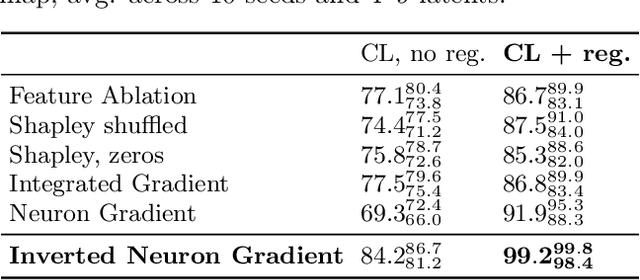
Gradient-based attribution methods aim to explain decisions of deep learning models but so far lack identifiability guarantees. Here, we propose a method to generate attribution maps with identifiability guarantees by developing a regularized contrastive learning algorithm trained on time-series data plus a new attribution method called Inverted Neuron Gradient (collectively named xCEBRA). We show theoretically that xCEBRA has favorable properties for identifying the Jacobian matrix of the data generating process. Empirically, we demonstrate robust approximation of zero vs. non-zero entries in the ground-truth attribution map on synthetic datasets, and significant improvements across previous attribution methods based on feature ablation, Shapley values, and other gradient-based methods. Our work constitutes a first example of identifiable inference of time-series attribution maps and opens avenues to a better understanding of time-series data, such as for neural dynamics and decision-processes within neural networks.
* Accepted at The 28th International Conference on Artificial Intelligence and Statistics (AISTATS 2025). Code is available at https://github.com/AdaptiveMotorControlLab/CEBRA
No Need to Talk: Asynchronous Mixture of Language Models
Oct 04, 2024

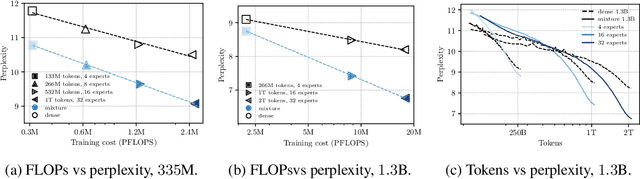
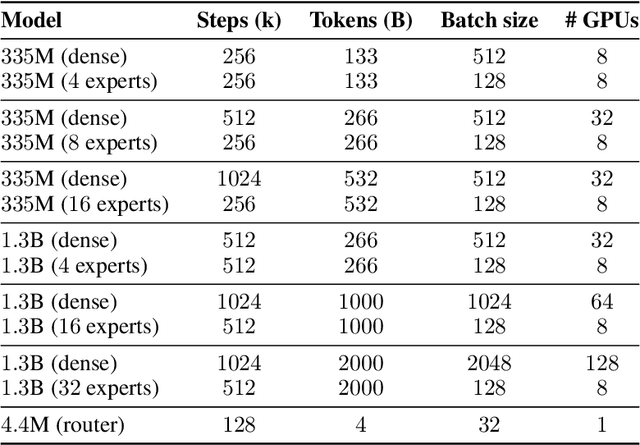
We introduce SmallTalk LM, an innovative method for training a mixture of language models in an almost asynchronous manner. Each model of the mixture specializes in distinct parts of the data distribution, without the need of high-bandwidth communication between the nodes training each model. At inference, a lightweight router directs a given sequence to a single expert, according to a short prefix. This inference scheme naturally uses a fraction of the parameters from the overall mixture model. Our experiments on language modeling demonstrate tha SmallTalk LM achieves significantly lower perplexity than dense model baselines for the same total training FLOPs and an almost identical inference cost. Finally, in our downstream evaluations we outperform the dense baseline on $75\%$ of the tasks.