 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbarrassingly Simple Self-Distillation Improves Code Generation
Apr 01, 2026Can a large language model (LLM) improve at code generation using only its own raw outputs, without a verifier, a teacher model, or reinforcement learning? We answer in the affirmative with simple self-distillation (SSD): sample solutions from the model with certain temperature and truncation configurations, then fine-tune on those samples with standard supervised fine-tuning. SSD improves Qwen3-30B-Instruct from 42.4% to 55.3% pass@1 on LiveCodeBench v6, with gains concentrating on harder problems, and it generalizes across Qwen and Llama models at 4B, 8B, and 30B scale, including both instruct and thinking variants. To understand why such a simple method can work, we trace these gains to a precision-exploration conflict in LLM decoding and show that SSD reshapes token distributions in a context-dependent way, suppressing distractor tails where precision matters while preserving useful diversity where exploration matters. Taken together, SSD offers a complementary post-training direction for improving LLM code generation.
Partial Parameter Updates for Efficient Distributed Training
Sep 26, 2025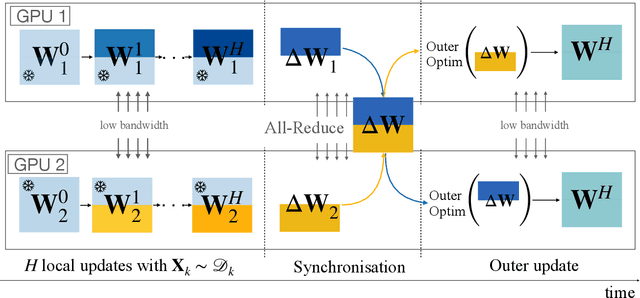
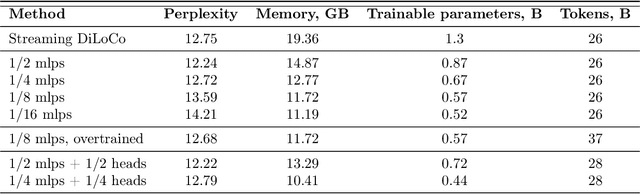
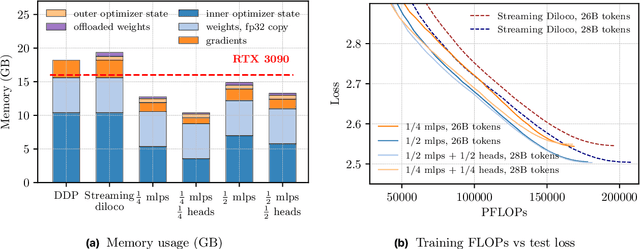
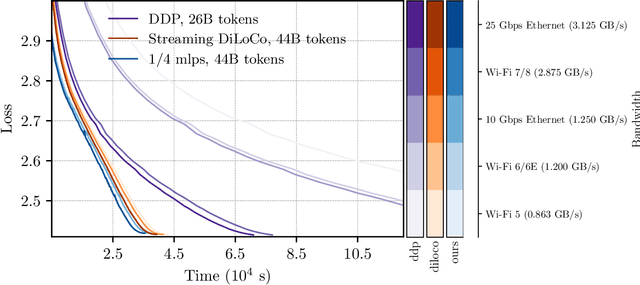
We introduce a memory- and compute-efficient method for low-communication distributed training. Existing methods reduce communication by performing multiple local updates between infrequent global synchronizations. We demonstrate that their efficiency can be significantly improved by restricting backpropagation: instead of updating all the parameters, each node updates only a fixed subset while keeping the remainder frozen during local steps. This constraint substantially reduces peak memory usage and training FLOPs, while a full forward pass over all parameters eliminates the need for cross-node activation exchange. Experiments on a $1.3$B-parameter language model trained across $32$ nodes show that our method matches the perplexity of prior low-communication approaches under identical token and bandwidth budgets while reducing training FLOPs and peak memory.
No Need to Talk: Asynchronous Mixture of Language Models
Oct 04, 2024

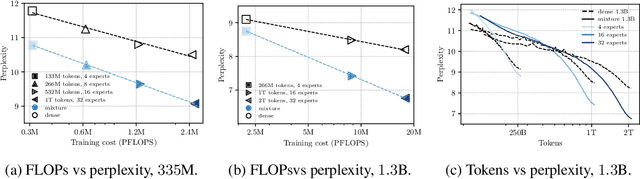
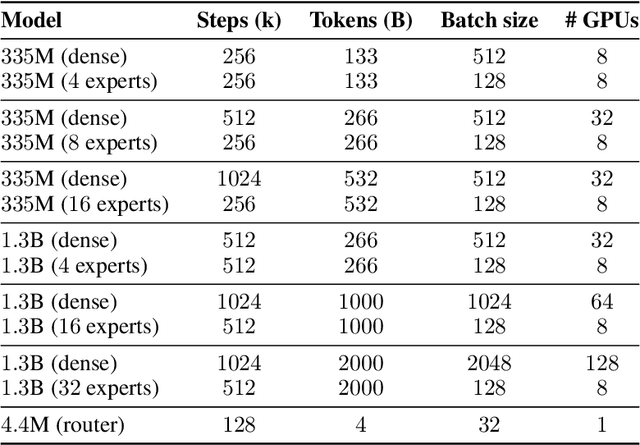
We introduce SmallTalk LM, an innovative method for training a mixture of language models in an almost asynchronous manner. Each model of the mixture specializes in distinct parts of the data distribution, without the need of high-bandwidth communication between the nodes training each model. At inference, a lightweight router directs a given sequence to a single expert, according to a short prefix. This inference scheme naturally uses a fraction of the parameters from the overall mixture model. Our experiments on language modeling demonstrate tha SmallTalk LM achieves significantly lower perplexity than dense model baselines for the same total training FLOPs and an almost identical inference cost. Finally, in our downstream evaluations we outperform the dense baseline on $75\%$ of the tasks.
Denoising LM: Pushing the Limits of Error Correction Models for Speech Recognition
May 24, 2024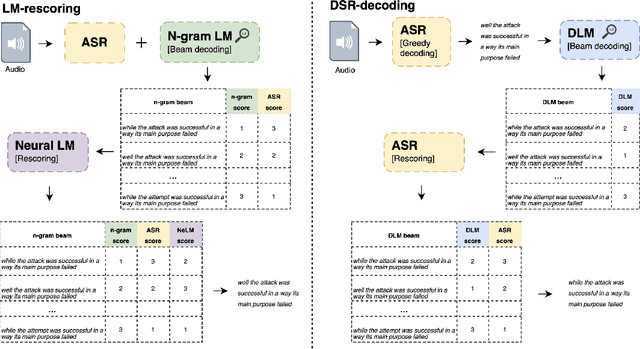
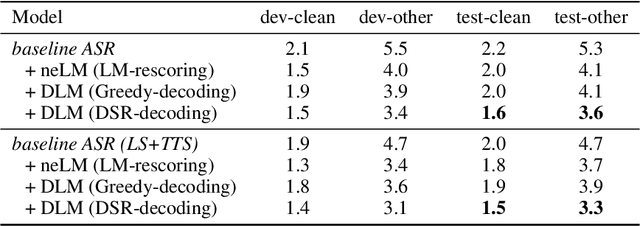

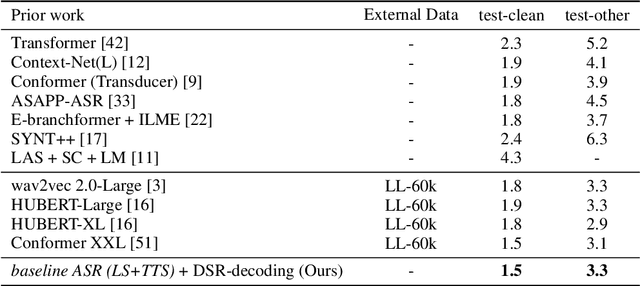
Language models (LMs) have long been used to improve results of automatic speech recognition (ASR) systems, but they are unaware of the errors that ASR systems make. Error correction models are designed to fix ASR errors, however, they showed little improvement over traditional LMs mainly due to the lack of supervised training data. In this paper, we present Denoising LM (DLM), which is a $\textit{scaled}$ error correction model trained with vast amounts of synthetic data, significantly exceeding prior attempts meanwhile achieving new state-of-the-art ASR performance. We use text-to-speech (TTS) systems to synthesize audio, which is fed into an ASR system to produce noisy hypotheses, which are then paired with the original texts to train the DLM. DLM has several $\textit{key ingredients}$: (i) up-scaled model and data; (ii) usage of multi-speaker TTS systems; (iii) combination of multiple noise augmentation strategies; and (iv) new decoding techniques. With a Transformer-CTC ASR, DLM achieves 1.5% word error rate (WER) on $\textit{test-clean}$ and 3.3% WER on $\textit{test-other}$ on Librispeech, which to our knowledge are the best reported numbers in the setting where no external audio data are used and even match self-supervised methods which use external audio data. Furthermore, a single DLM is applicable to different ASRs, and greatly surpassing the performance of conventional LM based beam-search rescoring. These results indicate that properly investigated error correction models have the potential to replace conventional LMs, holding the key to a new level of accuracy in ASR systems.
AV-CPL: Continuous Pseudo-Labeling for Audio-Visual Speech Recognition
Sep 29, 2023Audio-visual speech contains synchronized audio and visual information that provides cross-modal supervision to learn representations for both automatic speech recognition (ASR) and visual speech recognition (VSR). We introduce continuous pseudo-labeling for audio-visual speech recognition (AV-CPL), a semi-supervised method to train an audio-visual speech recognition (AVSR) model on a combination of labeled and unlabeled videos with continuously regenerated pseudo-labels. Our models are trained for speech recognition from audio-visual inputs and can perform speech recognition using both audio and visual modalities, or only one modality. Our method uses the same audio-visual model for both supervised training and pseudo-label generation, mitigating the need for external speech recognition models to generate pseudo-labels. AV-CPL obtains significant improvements in VSR performance on the LRS3 dataset while maintaining practical ASR and AVSR performance. Finally, using visual-only speech data, our method is able to leverage unlabeled visual speech to improve VSR.
Unsupervised ASR via Cross-Lingual Pseudo-Labeling
May 19, 2023

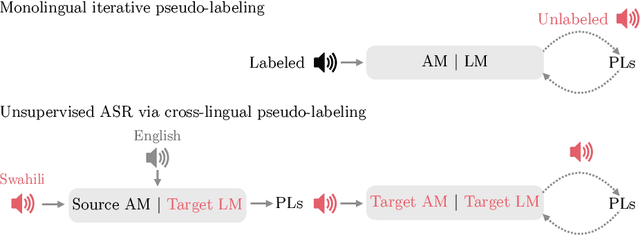

Recent work has shown that it is possible to train an $\textit{unsupervised}$ automatic speech recognition (ASR) system using only unpaired audio and text. Existing unsupervised ASR methods assume that no labeled data can be used for training. We argue that even if one does not have any labeled audio for a given language, there is $\textit{always}$ labeled data available for other languages. We show that it is possible to use character-level acoustic models (AMs) from other languages to bootstrap an $\textit{unsupervised}$ AM in a new language. Here, "unsupervised" means no labeled audio is available for the $\textit{target}$ language. Our approach is based on two key ingredients: (i) generating pseudo-labels (PLs) of the $\textit{target}$ language using some $\textit{other}$ language AM and (ii) constraining these PLs with a $\textit{target language model}$. Our approach is effective on Common Voice: e.g. transfer of English AM to Swahili achieves 18% WER. It also outperforms character-based wav2vec-U 2.0 by 15% absolute WER on LJSpeech with 800h of labeled German data instead of 60k hours of unlabeled English data.
Continuous Soft Pseudo-Labeling in ASR
Nov 11, 2022



Continuous pseudo-labeling (PL) algorithms such as slimIPL have recently emerged as a powerful strategy for semi-supervised learning in speech recognition. In contrast with earlier strategies that alternated between training a model and generating pseudo-labels (PLs) with it, here PLs are generated in end-to-end manner as training proceeds, improving training speed and the accuracy of the final model. PL shares a common theme with teacher-student models such as distillation in that a teacher model generates targets that need to be mimicked by the student model being trained. However, interestingly, PL strategies in general use hard-labels, whereas distillation uses the distribution over labels as the target to mimic. Inspired by distillation we expect that specifying the whole distribution (aka soft-labels) over sequences as the target for unlabeled data, instead of a single best pass pseudo-labeled transcript (hard-labels) should improve PL performance and convergence. Surprisingly and unexpectedly, we find that soft-labels targets can lead to training divergence, with the model collapsing to a degenerate token distribution per frame. We hypothesize that the reason this does not happen with hard-labels is that training loss on hard-labels imposes sequence-level consistency that keeps the model from collapsing to the degenerate solution. In this paper, we show several experiments that support this hypothesis, and experiment with several regularization approaches that can ameliorate the degenerate collapse when using soft-labels. These approaches can bring the accuracy of soft-labels closer to that of hard-labels, and while they are unable to outperform them yet, they serve as a useful framework for further improvements.
More Speaking or More Speakers?
Nov 02, 2022
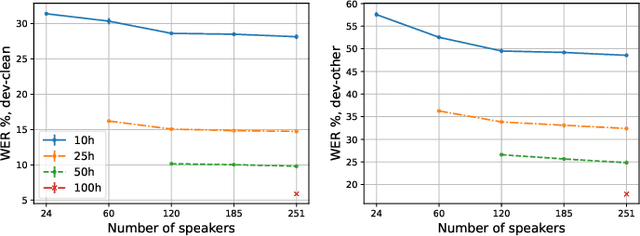
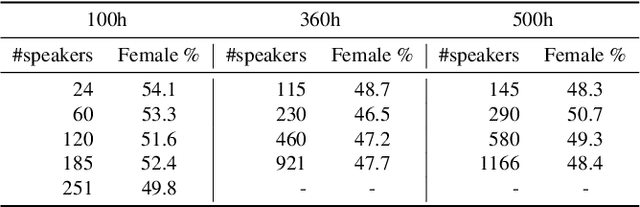
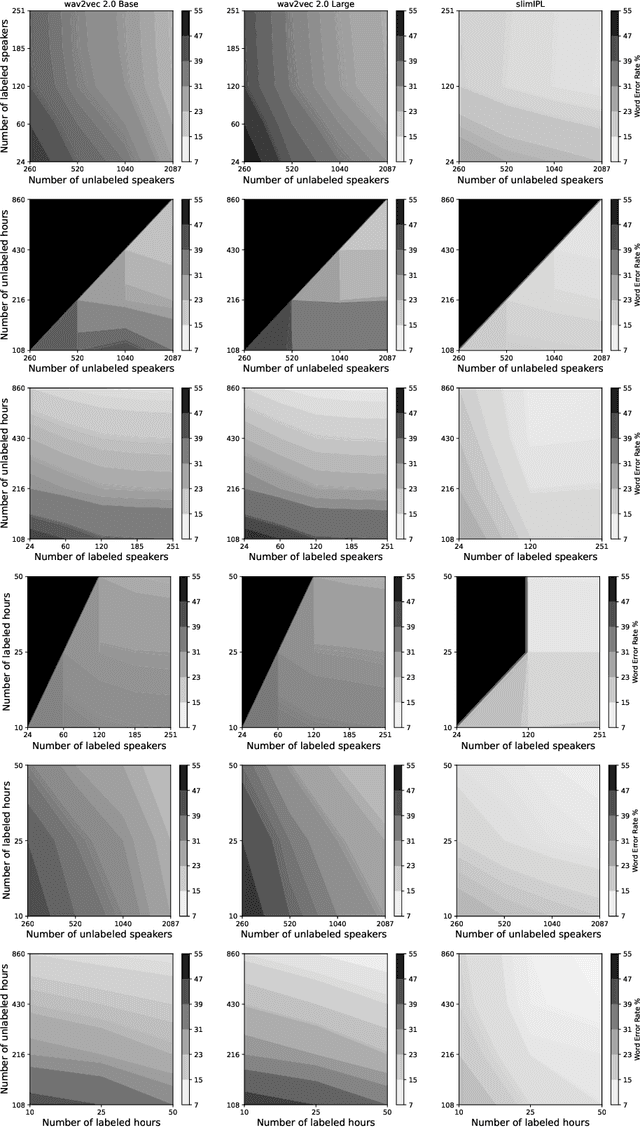
Self-training (ST) and self-supervised learning (SSL) methods have demonstrated strong improvements in automatic speech recognition (ASR). In spite of these advances, to the best of our knowledge, there is no analysis of how the composition of the labelled and unlabelled datasets used in these methods affects the results. In this work we aim to analyse the effect of numbers of speakers in the training data on a recent SSL algorithm (wav2vec 2.0), and a recent ST algorithm (slimIPL). We perform a systematic analysis on both labeled and unlabeled data by varying the number of speakers while keeping the number of hours fixed and vice versa. Our findings suggest that SSL requires a large amount of unlabeled data to produce high accuracy results, while ST requires a sufficient number of speakers in the labelled data, especially in the low-regime setting. In this manner these two approaches improve supervised learning in different regimes of dataset composition.
Continuous Pseudo-Labeling from the Start
Oct 17, 2022
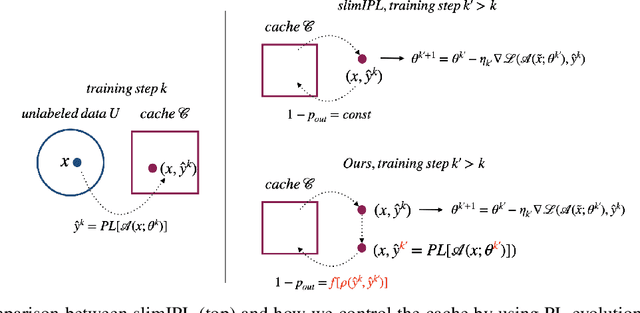
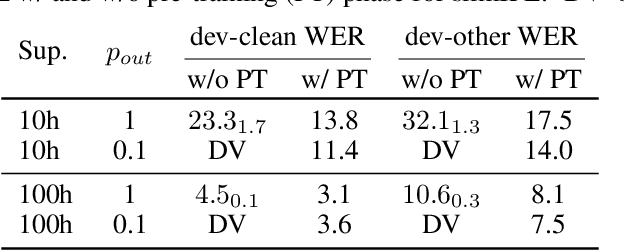
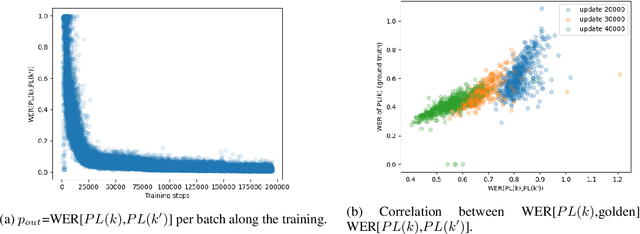
Self-training (ST), or pseudo-labeling has sparked significant interest in the automatic speech recognition (ASR) community recently because of its success in harnessing unlabeled data. Unlike prior semi-supervised learning approaches that relied on iteratively regenerating pseudo-labels (PLs) from a trained model and using them to train a new model, recent state-of-the-art methods perform `continuous training' where PLs are generated using a very recent version of the model being trained. Nevertheless, these approaches still rely on bootstrapping the ST using an initial supervised learning phase where the model is trained on labeled data alone. We believe this has the potential for over-fitting to the labeled dataset in low resource settings and that ST from the start of training should reduce over-fitting. In this paper we show how we can do this by dynamically controlling the evolution of PLs during the training process in ASR. To the best of our knowledge, this is the first study that shows the feasibility of generating PLs from the very start of the training. We are able to achieve this using two techniques that avoid instabilities which lead to degenerate models that do not generalize. Firstly, we control the evolution of PLs through a curriculum that uses the online changes in PLs to control the membership of the cache of PLs and improve generalization. Secondly, we find that by sampling transcriptions from the predictive distribution, rather than only using the best transcription, we can stabilize training further. With these techniques, our ST models match prior works without an external language model.
Flashlight: Enabling Innovation in Tools for Machine Learning
Jan 29, 2022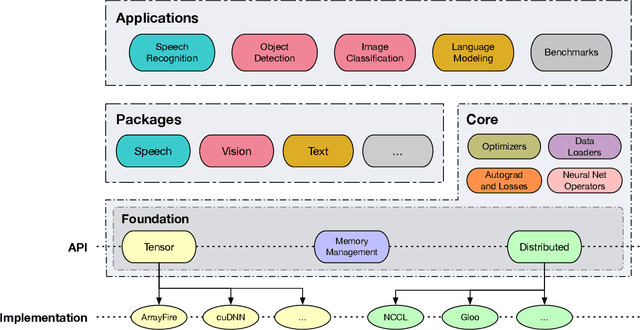
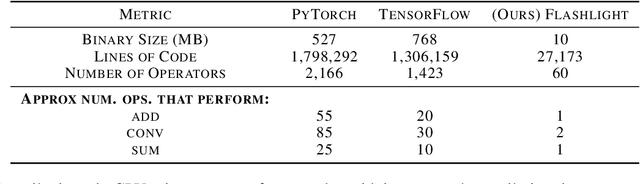
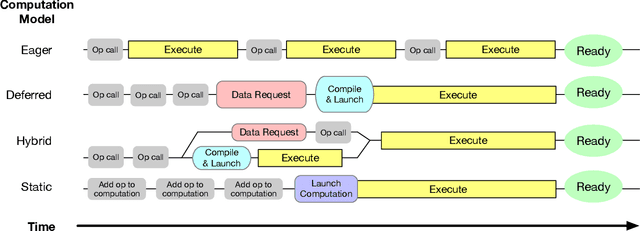
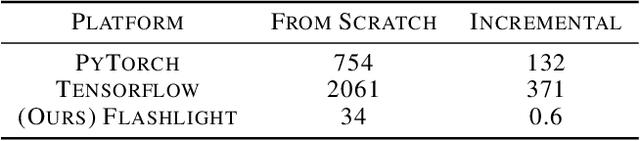
As the computational requirements for machine learning systems and the size and complexity of machine learning frameworks increases, essential framework innovation has become challenging. While computational needs have driven recent compiler, networking, and hardware advancements, utilization of those advancements by machine learning tools is occurring at a slower pace. This is in part due to the difficulties involved in prototyping new computational paradigms with existing frameworks. Large frameworks prioritize machine learning researchers and practitioners as end users and pay comparatively little attention to systems researchers who can push frameworks forward -- we argue that both are equally important stakeholders. We introduce Flashlight, an open-source library built to spur innovation in machine learning tools and systems by prioritizing open, modular, customizable internals and state-of-the-art, research-ready models and training setups across a variety of domains. Flashlight allows systems researchers to rapidly prototype and experiment with novel ideas in machine learning computation and has low overhead, competing with and often outperforming other popular machine learning frameworks. We see Flashlight as a tool enabling research that can benefit widely used libraries downstream and bring machine learning and systems researchers closer together.