 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMore Speaking or More Speakers?
Paper and Code

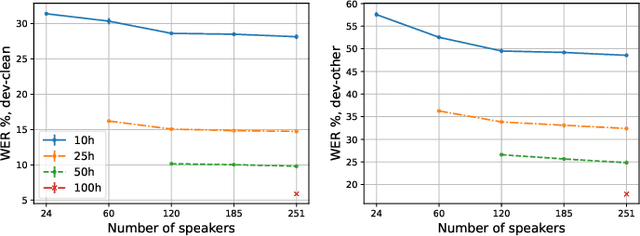
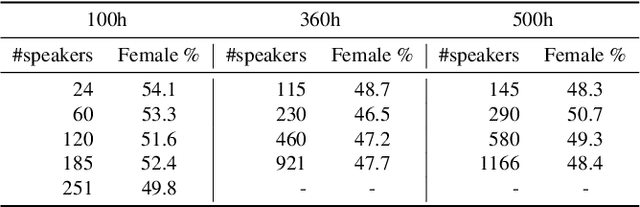
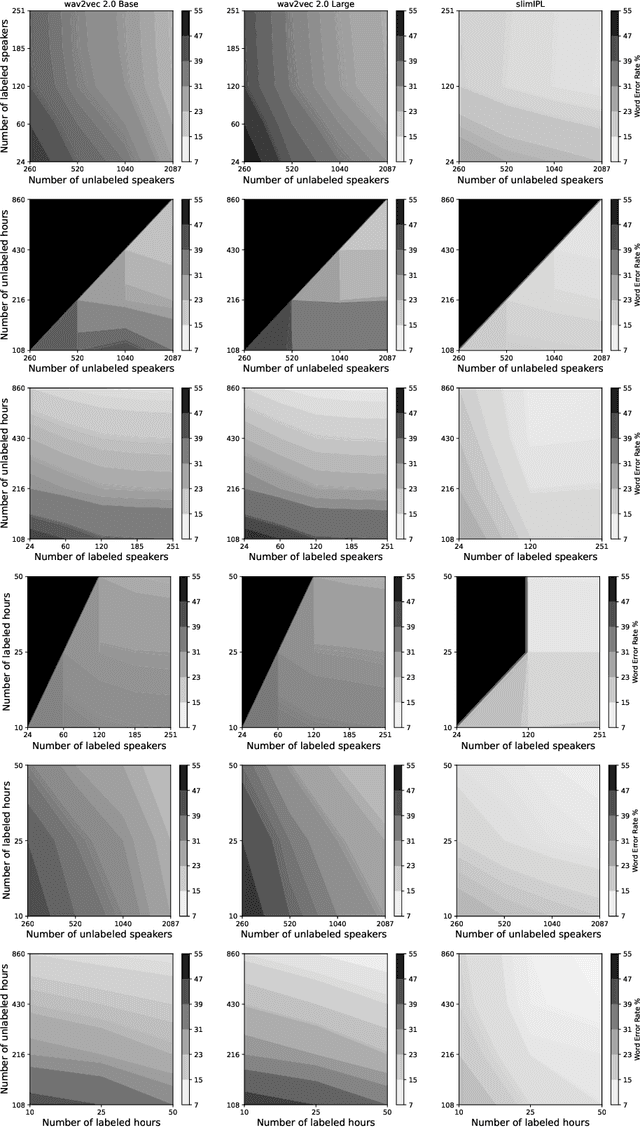
Self-training (ST) and self-supervised learning (SSL) methods have demonstrated strong improvements in automatic speech recognition (ASR). In spite of these advances, to the best of our knowledge, there is no analysis of how the composition of the labelled and unlabelled datasets used in these methods affects the results. In this work we aim to analyse the effect of numbers of speakers in the training data on a recent SSL algorithm (wav2vec 2.0), and a recent ST algorithm (slimIPL). We perform a systematic analysis on both labeled and unlabeled data by varying the number of speakers while keeping the number of hours fixed and vice versa. Our findings suggest that SSL requires a large amount of unlabeled data to produce high accuracy results, while ST requires a sufficient number of speakers in the labelled data, especially in the low-regime setting. In this manner these two approaches improve supervised learning in different regimes of dataset composition.