 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDelayed Fusion: Integrating Large Language Models into First-Pass Decoding in End-to-end Speech Recognition
Jan 16, 2025

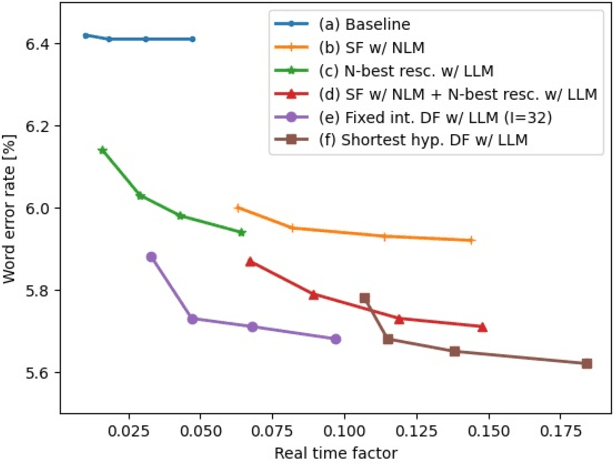

This paper presents an efficient decoding approach for end-to-end automatic speech recognition (E2E-ASR) with large language models (LLMs). Although shallow fusion is the most common approach to incorporate language models into E2E-ASR decoding, we face two practical problems with LLMs. (1) LLM inference is computationally costly. (2) There may be a vocabulary mismatch between the ASR model and the LLM. To resolve this mismatch, we need to retrain the ASR model and/or the LLM, which is at best time-consuming and in many cases not feasible. We propose "delayed fusion," which applies LLM scores to ASR hypotheses with a delay during decoding and enables easier use of pre-trained LLMs in ASR tasks. This method can reduce not only the number of hypotheses scored by the LLM but also the number of LLM inference calls. It also allows re-tokenizion of ASR hypotheses during decoding if ASR and LLM employ different tokenizations. We demonstrate that delayed fusion provides improved decoding speed and accuracy compared to shallow fusion and N-best rescoring using the LibriHeavy ASR corpus and three public LLMs, OpenLLaMA 3B & 7B and Mistral 7B.
Focused Discriminative Training For Streaming CTC-Trained Automatic Speech Recognition Models
Aug 23, 2024This paper introduces a novel training framework called Focused Discriminative Training (FDT) to further improve streaming word-piece end-to-end (E2E) automatic speech recognition (ASR) models trained using either CTC or an interpolation of CTC and attention-based encoder-decoder (AED) loss. The proposed approach presents a novel framework to identify and improve a model's recognition on challenging segments of an audio. Notably, this training framework is independent of hidden Markov models (HMMs) and lattices, eliminating the need for substantial decision-making regarding HMM topology, lexicon, and graph generation, as typically required in standard discriminative training approaches. Compared to additional fine-tuning with MMI or MWER loss on the encoder, FDT is shown to be more effective in achieving greater reductions in Word Error Rate (WER) on streaming models trained on LibriSpeech. Additionally, this method is shown to be effective in further improving a converged word-piece streaming E2E model trained on 600k hours of assistant and dictation dataset.
Optimizing Byte-level Representation for End-to-end ASR
Jun 14, 2024We propose a novel approach to optimizing a byte-level representation for end-to-end automatic speech recognition (ASR). Byte-level representation is often used by large scale multilingual ASR systems when the character set of the supported languages is large. The compactness and universality of byte-level representation allow the ASR models to use smaller output vocabularies and therefore, provide more flexibility. UTF-8 is a commonly used byte-level representation for multilingual ASR, but it is not designed to optimize machine learning tasks directly. By using auto-encoder and vector quantization, we show that we can optimize a byte-level representation for ASR and achieve better accuracy. Our proposed framework can incorporate information from different modalities, and provides an error correction mechanism. In an English/Mandarin dictation task, we show that a bilingual ASR model built with this approach can outperform UTF-8 representation by 5% relative in error rate.
Denoising LM: Pushing the Limits of Error Correction Models for Speech Recognition
May 24, 2024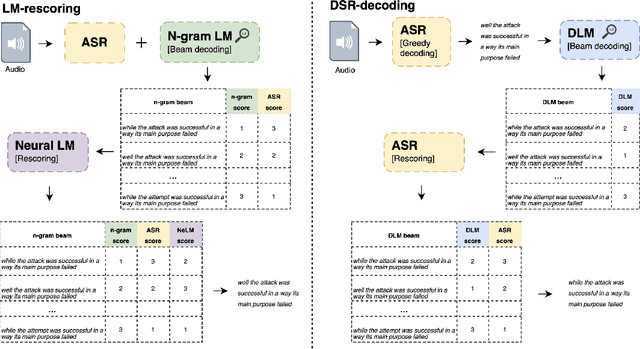
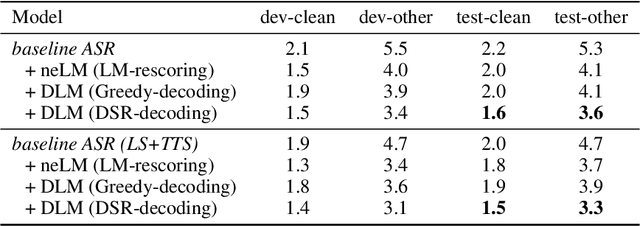

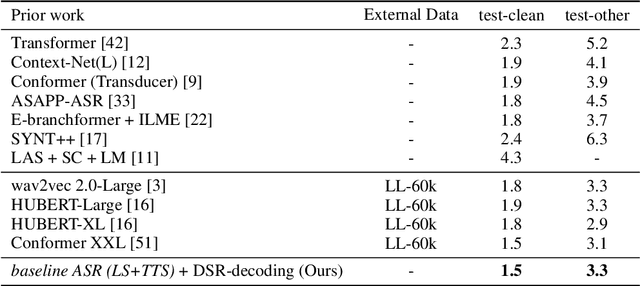
Language models (LMs) have long been used to improve results of automatic speech recognition (ASR) systems, but they are unaware of the errors that ASR systems make. Error correction models are designed to fix ASR errors, however, they showed little improvement over traditional LMs mainly due to the lack of supervised training data. In this paper, we present Denoising LM (DLM), which is a $\textit{scaled}$ error correction model trained with vast amounts of synthetic data, significantly exceeding prior attempts meanwhile achieving new state-of-the-art ASR performance. We use text-to-speech (TTS) systems to synthesize audio, which is fed into an ASR system to produce noisy hypotheses, which are then paired with the original texts to train the DLM. DLM has several $\textit{key ingredients}$: (i) up-scaled model and data; (ii) usage of multi-speaker TTS systems; (iii) combination of multiple noise augmentation strategies; and (iv) new decoding techniques. With a Transformer-CTC ASR, DLM achieves 1.5% word error rate (WER) on $\textit{test-clean}$ and 3.3% WER on $\textit{test-other}$ on Librispeech, which to our knowledge are the best reported numbers in the setting where no external audio data are used and even match self-supervised methods which use external audio data. Furthermore, a single DLM is applicable to different ASRs, and greatly surpassing the performance of conventional LM based beam-search rescoring. These results indicate that properly investigated error correction models have the potential to replace conventional LMs, holding the key to a new level of accuracy in ASR systems.
Neural Transducer Training: Reduced Memory Consumption with Sample-wise Computation
Nov 29, 2022The neural transducer is an end-to-end model for automatic speech recognition (ASR). While the model is well-suited for streaming ASR, the training process remains challenging. During training, the memory requirements may quickly exceed the capacity of state-of-the-art GPUs, limiting batch size and sequence lengths. In this work, we analyze the time and space complexity of a typical transducer training setup. We propose a memory-efficient training method that computes the transducer loss and gradients sample by sample. We present optimizations to increase the efficiency and parallelism of the sample-wise method. In a set of thorough benchmarks, we show that our sample-wise method significantly reduces memory usage, and performs at competitive speed when compared to the default batched computation. As a highlight, we manage to compute the transducer loss and gradients for a batch size of 1024, and audio length of 40 seconds, using only 6 GB of memory.
Variable Attention Masking for Configurable Transformer Transducer Speech Recognition
Nov 02, 2022



This work studies the use of attention masking in transformer transducer based speech recognition for building a single configurable model for different deployment scenarios. We present a comprehensive set of experiments comparing fixed masking, where the same attention mask is applied at every frame, with chunked masking, where the attention mask for each frame is determined by chunk boundaries, in terms of recognition accuracy and latency. We then explore the use of variable masking, where the attention masks are sampled from a target distribution at training time, to build models that can work in different configurations. Finally, we investigate how a single configurable model can be used to perform both first pass streaming recognition and second pass acoustic rescoring. Experiments show that chunked masking achieves a better accuracy vs latency trade-off compared to fixed masking, both with and without FastEmit. We also show that variable masking improves the accuracy by up to 8% relative in the acoustic re-scoring scenario.
A Density Ratio Approach to Language Model Fusion in End-To-End Automatic Speech Recognition
Feb 28, 2020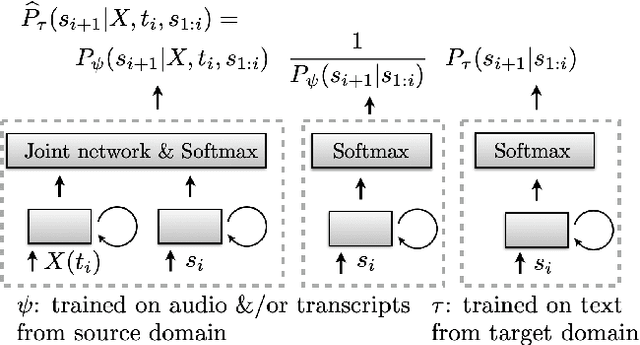
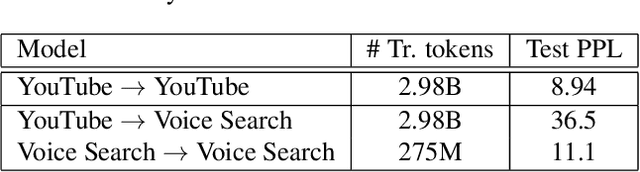
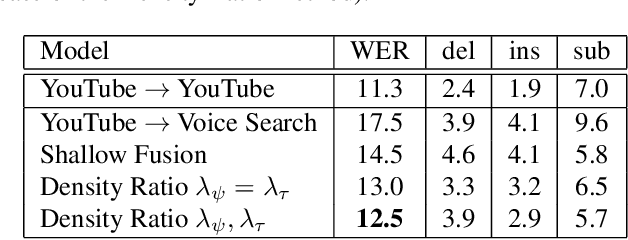
This article describes a density ratio approach to integrating external Language Models (LMs) into end-to-end models for Automatic Speech Recognition (ASR). Applied to a Recurrent Neural Network Transducer (RNN-T) ASR model trained on a given domain, a matched in-domain RNN-LM, and a target domain RNN-LM, the proposed method uses Bayes' Rule to define RNN-T posteriors for the target domain, in a manner directly analogous to the classic hybrid model for ASR based on Deep Neural Networks (DNNs) or LSTMs in the Hidden Markov Model (HMM) framework (Bourlard & Morgan, 1994). The proposed approach is evaluated in cross-domain and limited-data scenarios, for which a significant amount of target domain text data is used for LM training, but only limited (or no) {audio, transcript} training data pairs are used to train the RNN-T. Specifically, an RNN-T model trained on paired audio & transcript data from YouTube is evaluated for its ability to generalize to Voice Search data. The Density Ratio method was found to consistently outperform the dominant approach to LM and end-to-end ASR integration, Shallow Fusion.
Transformer Transducer: A Streamable Speech Recognition Model with Transformer Encoders and RNN-T Loss
Feb 14, 2020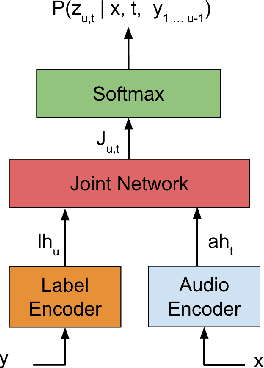

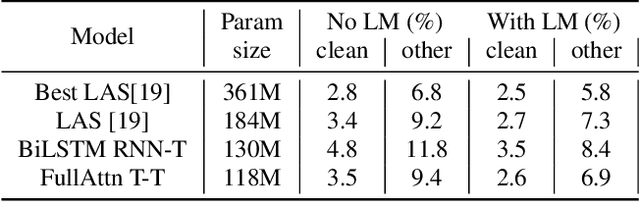
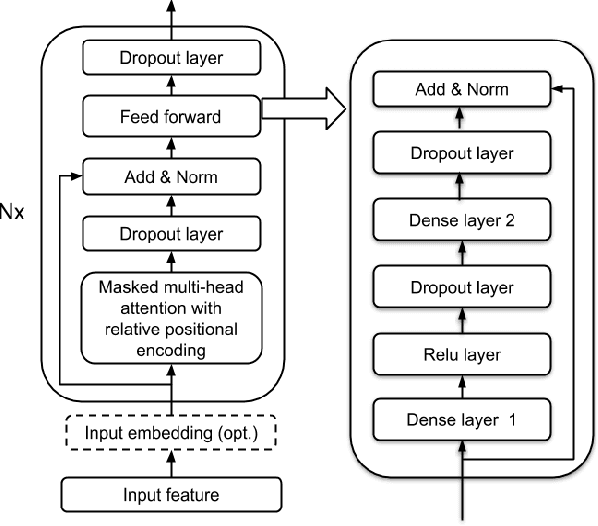
In this paper we present an end-to-end speech recognition model with Transformer encoders that can be used in a streaming speech recognition system. Transformer computation blocks based on self-attention are used to encode both audio and label sequences independently. The activations from both audio and label encoders are combined with a feed-forward layer to compute a probability distribution over the label space for every combination of acoustic frame position and label history. This is similar to the Recurrent Neural Network Transducer (RNN-T) model, which uses RNNs for information encoding instead of Transformer encoders. The model is trained with the RNN-T loss well-suited to streaming decoding. We present results on the LibriSpeech dataset showing that limiting the left context for self-attention in the Transformer layers makes decoding computationally tractable for streaming, with only a slight degradation in accuracy. We also show that the full attention version of our model beats the-state-of-the art accuracy on the LibriSpeech benchmarks. Our results also show that we can bridge the gap between full attention and limited attention versions of our model by attending to a limited number of future frames.