 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegmental Attention Decoding With Long Form Acoustic Encodings
Dec 16, 2025

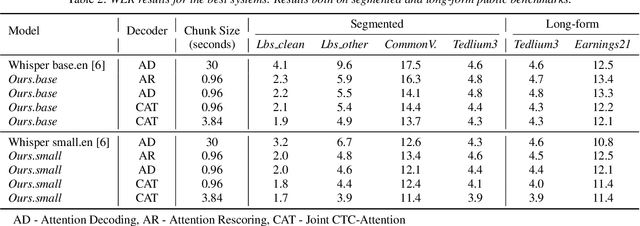
We address the fundamental incompatibility of attention-based encoder-decoder (AED) models with long-form acoustic encodings. AED models trained on segmented utterances learn to encode absolute frame positions by exploiting limited acoustic context beyond segment boundaries, but fail to generalize when decoding long-form segments where these cues vanish. The model loses ability to order acoustic encodings due to permutation invariance of keys and values in cross-attention. We propose four modifications: (1) injecting explicit absolute positional encodings into cross-attention for each decoded segment, (2) long-form training with extended acoustic context to eliminate implicit absolute position encoding, (3) segment concatenation to cover diverse segmentations needed during training, and (4) semantic segmentation to align AED-decoded segments with training segments. We show these modifications close the accuracy gap between continuous and segmented acoustic encodings, enabling auto-regressive use of the attention decoder.
Delayed Fusion: Integrating Large Language Models into First-Pass Decoding in End-to-end Speech Recognition
Jan 16, 2025

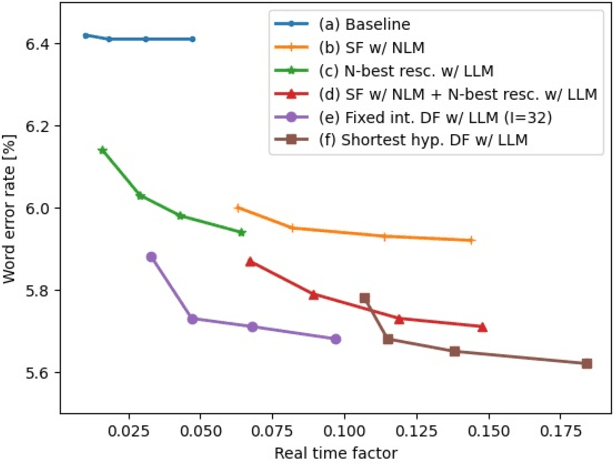

This paper presents an efficient decoding approach for end-to-end automatic speech recognition (E2E-ASR) with large language models (LLMs). Although shallow fusion is the most common approach to incorporate language models into E2E-ASR decoding, we face two practical problems with LLMs. (1) LLM inference is computationally costly. (2) There may be a vocabulary mismatch between the ASR model and the LLM. To resolve this mismatch, we need to retrain the ASR model and/or the LLM, which is at best time-consuming and in many cases not feasible. We propose "delayed fusion," which applies LLM scores to ASR hypotheses with a delay during decoding and enables easier use of pre-trained LLMs in ASR tasks. This method can reduce not only the number of hypotheses scored by the LLM but also the number of LLM inference calls. It also allows re-tokenizion of ASR hypotheses during decoding if ASR and LLM employ different tokenizations. We demonstrate that delayed fusion provides improved decoding speed and accuracy compared to shallow fusion and N-best rescoring using the LibriHeavy ASR corpus and three public LLMs, OpenLLaMA 3B & 7B and Mistral 7B.
Optimizing Contextual Speech Recognition Using Vector Quantization for Efficient Retrieval
Nov 04, 2024Neural contextual biasing allows speech recognition models to leverage contextually relevant information, leading to improved transcription accuracy. However, the biasing mechanism is typically based on a cross-attention module between the audio and a catalogue of biasing entries, which means computational complexity can pose severe practical limitations on the size of the biasing catalogue and consequently on accuracy improvements. This work proposes an approximation to cross-attention scoring based on vector quantization and enables compute- and memory-efficient use of large biasing catalogues. We propose to use this technique jointly with a retrieval based contextual biasing approach. First, we use an efficient quantized retrieval module to shortlist biasing entries by grounding them on audio. Then we use retrieved entries for biasing. Since the proposed approach is agnostic to the biasing method, we investigate using full cross-attention, LLM prompting, and a combination of the two. We show that retrieval based shortlisting allows the system to efficiently leverage biasing catalogues of several thousands of entries, resulting in up to 71% relative error rate reduction in personal entity recognition. At the same time, the proposed approximation algorithm reduces compute time by 20% and memory usage by 85-95%, for lists of up to one million entries, when compared to standard dot-product cross-attention.
Focused Discriminative Training For Streaming CTC-Trained Automatic Speech Recognition Models
Aug 23, 2024This paper introduces a novel training framework called Focused Discriminative Training (FDT) to further improve streaming word-piece end-to-end (E2E) automatic speech recognition (ASR) models trained using either CTC or an interpolation of CTC and attention-based encoder-decoder (AED) loss. The proposed approach presents a novel framework to identify and improve a model's recognition on challenging segments of an audio. Notably, this training framework is independent of hidden Markov models (HMMs) and lattices, eliminating the need for substantial decision-making regarding HMM topology, lexicon, and graph generation, as typically required in standard discriminative training approaches. Compared to additional fine-tuning with MMI or MWER loss on the encoder, FDT is shown to be more effective in achieving greater reductions in Word Error Rate (WER) on streaming models trained on LibriSpeech. Additionally, this method is shown to be effective in further improving a converged word-piece streaming E2E model trained on 600k hours of assistant and dictation dataset.
Optimizing Byte-level Representation for End-to-end ASR
Jun 14, 2024We propose a novel approach to optimizing a byte-level representation for end-to-end automatic speech recognition (ASR). Byte-level representation is often used by large scale multilingual ASR systems when the character set of the supported languages is large. The compactness and universality of byte-level representation allow the ASR models to use smaller output vocabularies and therefore, provide more flexibility. UTF-8 is a commonly used byte-level representation for multilingual ASR, but it is not designed to optimize machine learning tasks directly. By using auto-encoder and vector quantization, we show that we can optimize a byte-level representation for ASR and achieve better accuracy. Our proposed framework can incorporate information from different modalities, and provides an error correction mechanism. In an English/Mandarin dictation task, we show that a bilingual ASR model built with this approach can outperform UTF-8 representation by 5% relative in error rate.
Approximate Nearest Neighbour Phrase Mining for Contextual Speech Recognition
Apr 18, 2023


This paper presents an extension to train end-to-end Context-Aware Transformer Transducer ( CATT ) models by using a simple, yet efficient method of mining hard negative phrases from the latent space of the context encoder. During training, given a reference query, we mine a number of similar phrases using approximate nearest neighbour search. These sampled phrases are then used as negative examples in the context list alongside random and ground truth contextual information. By including approximate nearest neighbour phrases (ANN-P) in the context list, we encourage the learned representation to disambiguate between similar, but not identical, biasing phrases. This improves biasing accuracy when there are several similar phrases in the biasing inventory. We carry out experiments in a large-scale data regime obtaining up to 7% relative word error rate reductions for the contextual portion of test data. We also extend and evaluate CATT approach in streaming applications.
Variable Attention Masking for Configurable Transformer Transducer Speech Recognition
Nov 02, 2022



This work studies the use of attention masking in transformer transducer based speech recognition for building a single configurable model for different deployment scenarios. We present a comprehensive set of experiments comparing fixed masking, where the same attention mask is applied at every frame, with chunked masking, where the attention mask for each frame is determined by chunk boundaries, in terms of recognition accuracy and latency. We then explore the use of variable masking, where the attention masks are sampled from a target distribution at training time, to build models that can work in different configurations. Finally, we investigate how a single configurable model can be used to perform both first pass streaming recognition and second pass acoustic rescoring. Experiments show that chunked masking achieves a better accuracy vs latency trade-off compared to fixed masking, both with and without FastEmit. We also show that variable masking improves the accuracy by up to 8% relative in the acoustic re-scoring scenario.
Exploring Retraining-Free Speech Recognition for Intra-sentential Code-Switching
Aug 27, 2021
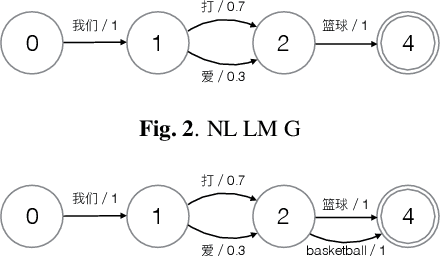
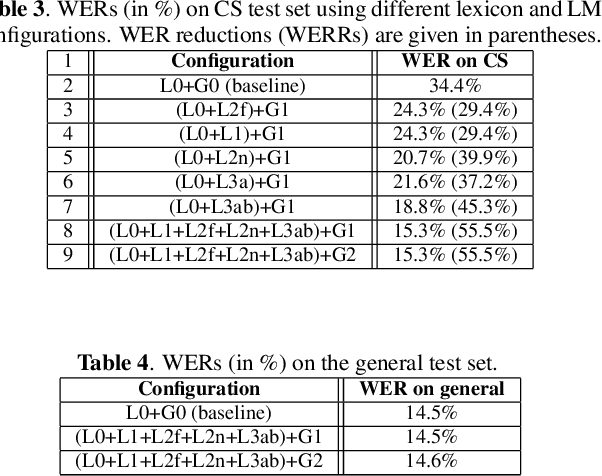
In this paper, we present our initial efforts for building a code-switching (CS) speech recognition system leveraging existing acoustic models (AMs) and language models (LMs), i.e., no training required, and specifically targeting intra-sentential switching. To achieve such an ambitious goal, new mechanisms for foreign pronunciation generation and language model (LM) enrichment have been devised. Specifically, we have designed an automatic approach to obtain high quality pronunciation of foreign language (FL) words in the native language (NL) phoneme set using existing acoustic phone decoders and an LSTM-based grapheme-to-phoneme (G2P) model. Improved accented pronunciations have thus been obtained by learning foreign pronunciations directly from data. Furthermore, a code-switching LM was deployed by converting the original NL LM into a CS LM using translated word pairs and borrowing statistics for the NL LM. Experimental evidence clearly demonstrates that our approach better deals with accented foreign pronunciations than techniques based on human labeling. Moreover, our best system achieves a 55.5% relative word error rate reduction from 34.4%, obtained with a conventional monolingual ASR system, to 15.3% on an intra-sentential CS task without harming the monolingual recognition accuracy.
Frame-level SpecAugment for Deep Convolutional Neural Networks in Hybrid ASR Systems
Dec 07, 2020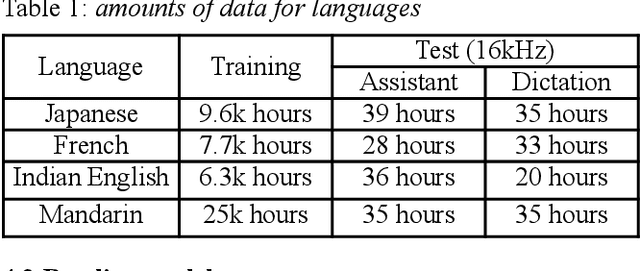
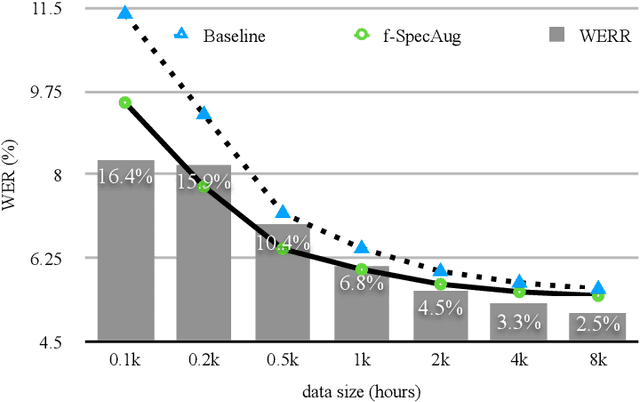
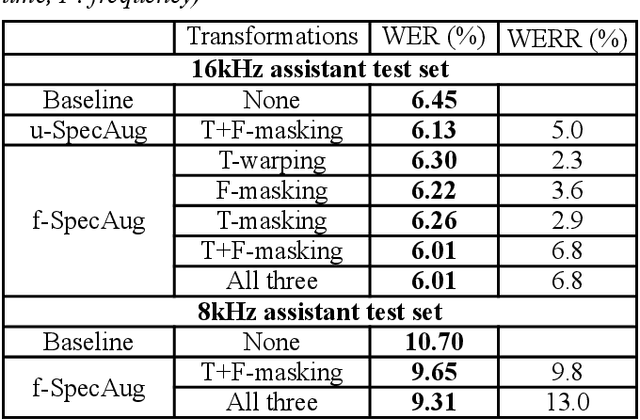
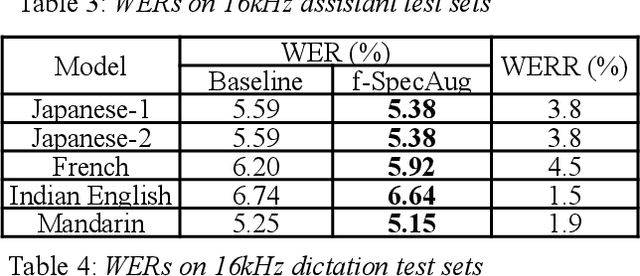
Inspired by SpecAugment -- a data augmentation method for end-to-end ASR systems, we propose a frame-level SpecAugment method (f-SpecAugment) to improve the performance of deep convolutional neural networks (CNN) for hybrid HMM based ASR systems. Similar to the utterance level SpecAugment, f-SpecAugment performs three transformations: time warping, frequency masking, and time masking. Instead of applying the transformations at the utterance level, f-SpecAugment applies them to each convolution window independently during training. We demonstrate that f-SpecAugment is more effective than the utterance level SpecAugment for deep CNN based hybrid models. We evaluate the proposed f-SpecAugment on 50-layer Self-Normalizing Deep CNN (SNDCNN) acoustic models trained with up to 25000 hours of training data. We observe f-SpecAugment reduces WER by 0.5-4.5% relatively across different ASR tasks for four languages. As the benefits of augmentation techniques tend to diminish as training data size increases, the large scale training reported is important in understanding the effectiveness of f-SpecAugment. Our experiments demonstrate that even with 25k training data, f-SpecAugment is still effective. We also demonstrate that f-SpecAugment has benefits approximately equivalent to doubling the amount of training data for deep CNNs.
SNDCNN: Self-normalizing deep CNNs with scaled exponential linear units for speech recognition
Oct 09, 2019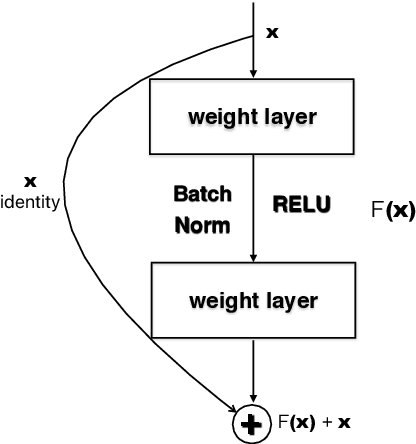

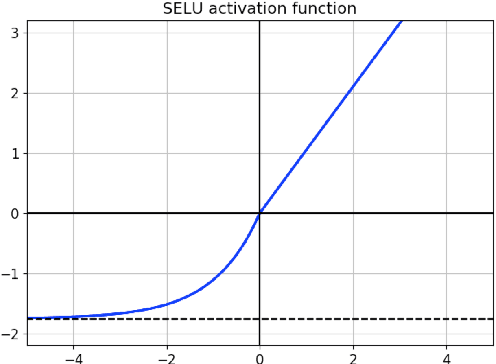

Very deep CNNs achieve state-of-the-art results in both computer vision and speech recognition, but are difficult to train. The most popular way to train very deep CNNs is to use shortcut connections (SC) together with batch normalization (BN). Inspired by Self-Normalizing Neural Networks, we propose the self-normalizing deep CNN (SNDCNN) based acoustic model topology, by removing the SC/BN and replacing the typical RELU activations with scaled exponential linear unit (SELU) in ResNet-50. SELU activations make the network self-normalizing and remove the need for both shortcut connections and batch normalization. Compared to ResNet-50, we can achieve the same or lower word error rate (WER) while at the same time improving both training and inference speed by 60%-80%. We also explore other model inference optimizations to further reduce latency for production use.