 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSNDCNN: Self-normalizing deep CNNs with scaled exponential linear units for speech recognition
Paper and Code
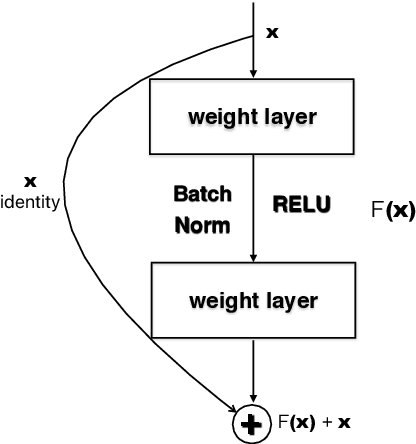

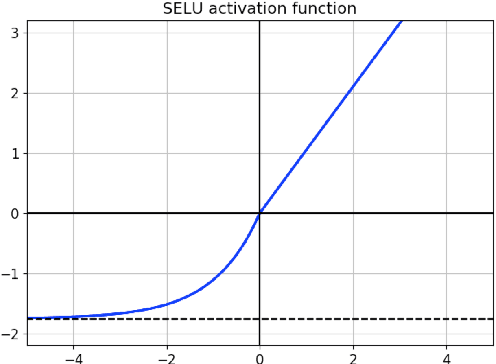

Very deep CNNs achieve state-of-the-art results in both computer vision and speech recognition, but are difficult to train. The most popular way to train very deep CNNs is to use shortcut connections (SC) together with batch normalization (BN). Inspired by Self-Normalizing Neural Networks, we propose the self-normalizing deep CNN (SNDCNN) based acoustic model topology, by removing the SC/BN and replacing the typical RELU activations with scaled exponential linear unit (SELU) in ResNet-50. SELU activations make the network self-normalizing and remove the need for both shortcut connections and batch normalization. Compared to ResNet-50, we can achieve the same or lower word error rate (WER) while at the same time improving both training and inference speed by 60%-80%. We also explore other model inference optimizations to further reduce latency for production use.