 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFocused Discriminative Training For Streaming CTC-Trained Automatic Speech Recognition Models
Aug 23, 2024This paper introduces a novel training framework called Focused Discriminative Training (FDT) to further improve streaming word-piece end-to-end (E2E) automatic speech recognition (ASR) models trained using either CTC or an interpolation of CTC and attention-based encoder-decoder (AED) loss. The proposed approach presents a novel framework to identify and improve a model's recognition on challenging segments of an audio. Notably, this training framework is independent of hidden Markov models (HMMs) and lattices, eliminating the need for substantial decision-making regarding HMM topology, lexicon, and graph generation, as typically required in standard discriminative training approaches. Compared to additional fine-tuning with MMI or MWER loss on the encoder, FDT is shown to be more effective in achieving greater reductions in Word Error Rate (WER) on streaming models trained on LibriSpeech. Additionally, this method is shown to be effective in further improving a converged word-piece streaming E2E model trained on 600k hours of assistant and dictation dataset.
Conformer-Based Speech Recognition On Extreme Edge-Computing Devices
Dec 16, 2023


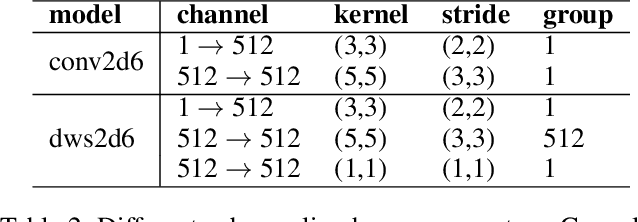
With increasingly more powerful compute capabilities and resources in today's devices, traditionally compute-intensive automatic speech recognition (ASR) has been moving from the cloud to devices to better protect user privacy. However, it is still challenging to implement on-device ASR on resource-constrained devices, such as smartphones, smart wearables, and other small home automation devices. In this paper, we propose a series of model architecture adaptions, neural network graph transformations, and numerical optimizations to fit an advanced Conformer based end-to-end streaming ASR system on resource-constrained devices without accuracy degradation. We achieve over 5.26 times faster than realtime (0.19 RTF) speech recognition on small wearables while minimizing energy consumption and achieving state-of-the-art accuracy. The proposed methods are widely applicable to other transformer-based server-free AI applications. In addition, we provide a complete theory on optimal pre-normalizers that numerically stabilize layer normalization in any Lp-norm using any floating point precision.
Towards Real-World Streaming Speech Translation for Code-Switched Speech
Oct 23, 2023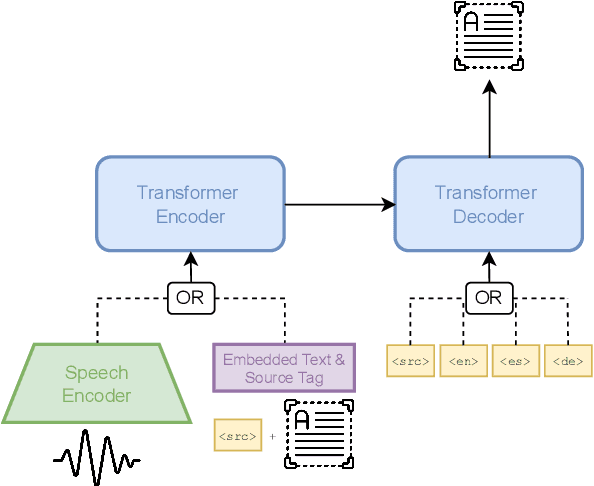
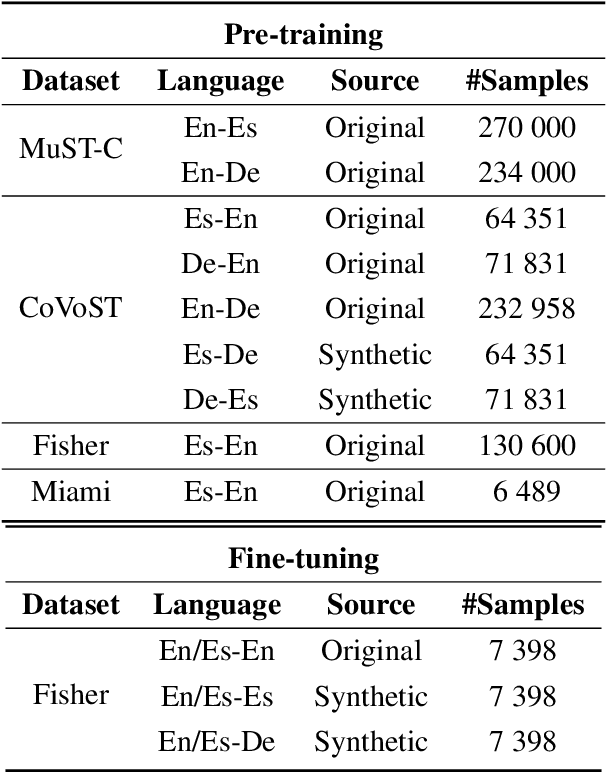
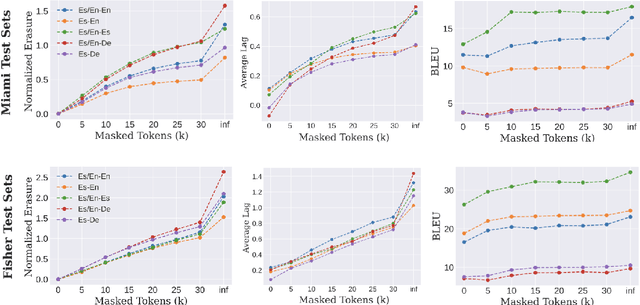
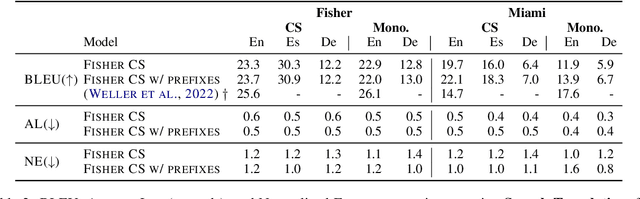
Code-switching (CS), i.e. mixing different languages in a single sentence, is a common phenomenon in communication and can be challenging in many Natural Language Processing (NLP) settings. Previous studies on CS speech have shown promising results for end-to-end speech translation (ST), but have been limited to offline scenarios and to translation to one of the languages present in the source (\textit{monolingual transcription}). In this paper, we focus on two essential yet unexplored areas for real-world CS speech translation: streaming settings, and translation to a third language (i.e., a language not included in the source). To this end, we extend the Fisher and Miami test and validation datasets to include new targets in Spanish and German. Using this data, we train a model for both offline and streaming ST and we establish baseline results for the two settings mentioned earlier.
Personalization of CTC-based End-to-End Speech Recognition Using Pronunciation-Driven Subword Tokenization
Oct 16, 2023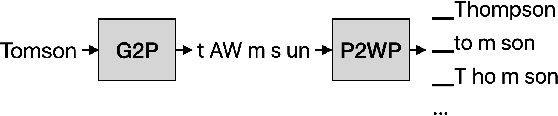


Recent advances in deep learning and automatic speech recognition have improved the accuracy of end-to-end speech recognition systems, but recognition of personal content such as contact names remains a challenge. In this work, we describe our personalization solution for an end-to-end speech recognition system based on connectionist temporal classification. Building on previous work, we present a novel method for generating additional subword tokenizations for personal entities from their pronunciations. We show that using this technique in combination with two established techniques, contextual biasing and wordpiece prior normalization, we are able to achieve personal named entity accuracy on par with a competitive hybrid system.
Acoustic Model Fusion for End-to-end Speech Recognition
Oct 10, 2023

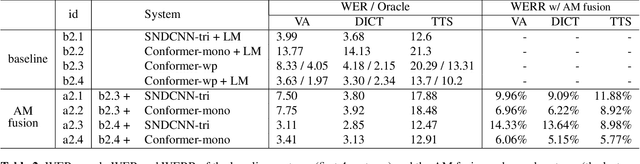
Recent advances in deep learning and automatic speech recognition (ASR) have enabled the end-to-end (E2E) ASR system and boosted the accuracy to a new level. The E2E systems implicitly model all conventional ASR components, such as the acoustic model (AM) and the language model (LM), in a single network trained on audio-text pairs. Despite this simpler system architecture, fusing a separate LM, trained exclusively on text corpora, into the E2E system has proven to be beneficial. However, the application of LM fusion presents certain drawbacks, such as its inability to address the domain mismatch issue inherent to the internal AM. Drawing inspiration from the concept of LM fusion, we propose the integration of an external AM into the E2E system to better address the domain mismatch. By implementing this novel approach, we have achieved a significant reduction in the word error rate, with an impressive drop of up to 14.3% across varied test sets. We also discovered that this AM fusion approach is particularly beneficial in enhancing named entity recognition.
A Treatise On FST Lattice Based MMI Training
Oct 17, 2022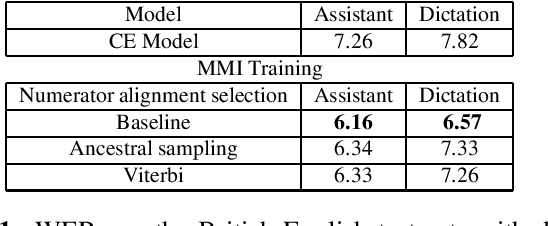
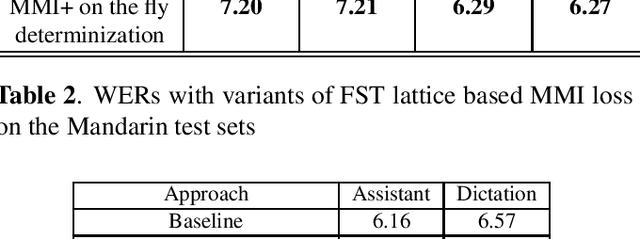
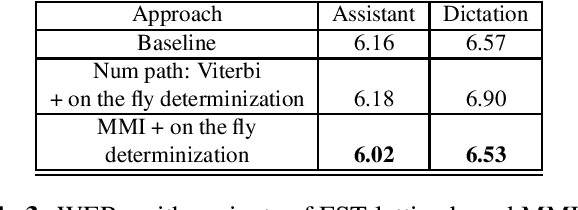
Maximum mutual information (MMI) has become one of the two de facto methods for sequence-level training of speech recognition acoustic models. This paper aims to isolate, identify and bring forward the implicit modelling decisions induced by the design implementation of standard finite state transducer (FST) lattice based MMI training framework. The paper particularly investigates the necessity to maintain a preselected numerator alignment and raises the importance of determinizing FST denominator lattices on the fly. The efficacy of employing on the fly FST lattice determinization is mathematically shown to guarantee discrimination at the hypothesis level and is empirically shown through training deep CNN models on a 18K hours Mandarin dataset and on a 2.8K hours English dataset. On assistant and dictation tasks, the approach achieves between 2.3-4.6% relative WER reduction (WERR) over the standard FST lattice based approach.
Online Automatic Speech Recognition with Listen, Attend and Spell Model
Aug 12, 2020

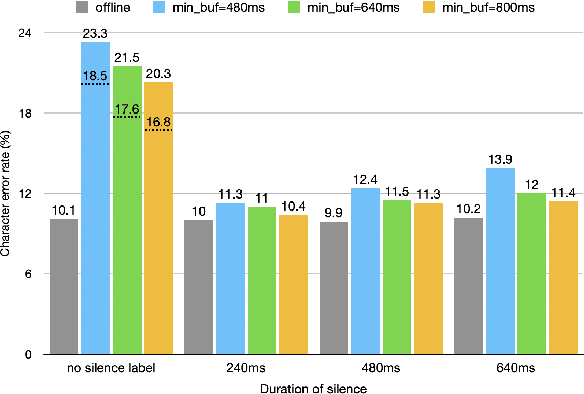
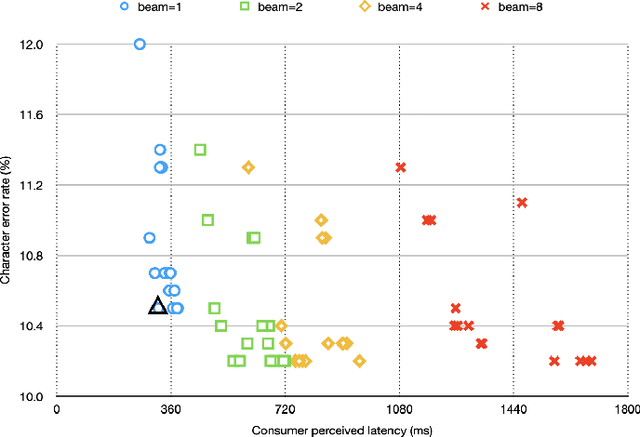
The Listen, Attend and Spell (LAS) model and other attention-based automatic speech recognition (ASR) models have known limitations when operated in a fully online mode. In this paper, we analyze the online operation of LAS models to demonstrate that these limitations stem from the handling of silence regions and the reliability of online attention mechanism at the edge of input buffers. We propose a novel and simple technique that can achieve fully online recognition while meeting accuracy and latency targets. For the Mandarin dictation task, our proposed approach can achieve a character error rate in online operation that is within 4% relative to an offline LAS model. The proposed online LAS model operates at 12% lower latency relative to a conventional neural network hidden Markov model hybrid of comparable accuracy. We have validated the proposed method through a production scale deployment, which, to the best of our knowledge, is the first such deployment of a fully online LAS model.
SNDCNN: Self-normalizing deep CNNs with scaled exponential linear units for speech recognition
Oct 09, 2019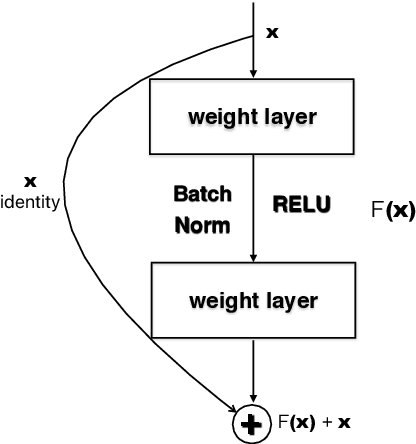

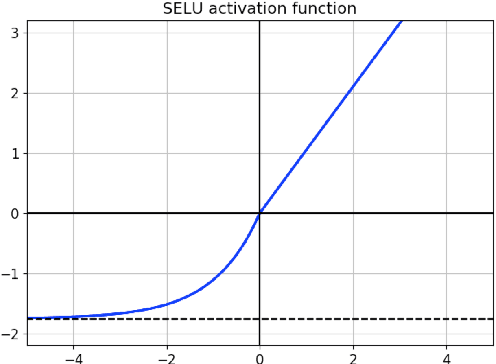

Very deep CNNs achieve state-of-the-art results in both computer vision and speech recognition, but are difficult to train. The most popular way to train very deep CNNs is to use shortcut connections (SC) together with batch normalization (BN). Inspired by Self-Normalizing Neural Networks, we propose the self-normalizing deep CNN (SNDCNN) based acoustic model topology, by removing the SC/BN and replacing the typical RELU activations with scaled exponential linear unit (SELU) in ResNet-50. SELU activations make the network self-normalizing and remove the need for both shortcut connections and batch normalization. Compared to ResNet-50, we can achieve the same or lower word error rate (WER) while at the same time improving both training and inference speed by 60%-80%. We also explore other model inference optimizations to further reduce latency for production use.