 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDelayed Fusion: Integrating Large Language Models into First-Pass Decoding in End-to-end Speech Recognition
Jan 16, 2025

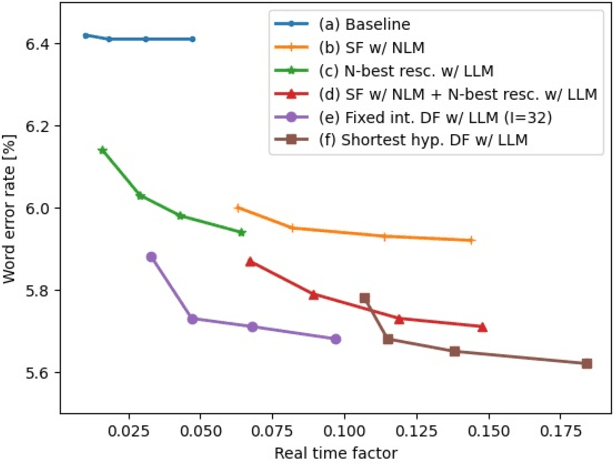

This paper presents an efficient decoding approach for end-to-end automatic speech recognition (E2E-ASR) with large language models (LLMs). Although shallow fusion is the most common approach to incorporate language models into E2E-ASR decoding, we face two practical problems with LLMs. (1) LLM inference is computationally costly. (2) There may be a vocabulary mismatch between the ASR model and the LLM. To resolve this mismatch, we need to retrain the ASR model and/or the LLM, which is at best time-consuming and in many cases not feasible. We propose "delayed fusion," which applies LLM scores to ASR hypotheses with a delay during decoding and enables easier use of pre-trained LLMs in ASR tasks. This method can reduce not only the number of hypotheses scored by the LLM but also the number of LLM inference calls. It also allows re-tokenizion of ASR hypotheses during decoding if ASR and LLM employ different tokenizations. We demonstrate that delayed fusion provides improved decoding speed and accuracy compared to shallow fusion and N-best rescoring using the LibriHeavy ASR corpus and three public LLMs, OpenLLaMA 3B & 7B and Mistral 7B.
Focused Discriminative Training For Streaming CTC-Trained Automatic Speech Recognition Models
Aug 23, 2024This paper introduces a novel training framework called Focused Discriminative Training (FDT) to further improve streaming word-piece end-to-end (E2E) automatic speech recognition (ASR) models trained using either CTC or an interpolation of CTC and attention-based encoder-decoder (AED) loss. The proposed approach presents a novel framework to identify and improve a model's recognition on challenging segments of an audio. Notably, this training framework is independent of hidden Markov models (HMMs) and lattices, eliminating the need for substantial decision-making regarding HMM topology, lexicon, and graph generation, as typically required in standard discriminative training approaches. Compared to additional fine-tuning with MMI or MWER loss on the encoder, FDT is shown to be more effective in achieving greater reductions in Word Error Rate (WER) on streaming models trained on LibriSpeech. Additionally, this method is shown to be effective in further improving a converged word-piece streaming E2E model trained on 600k hours of assistant and dictation dataset.
A Treatise On FST Lattice Based MMI Training
Oct 17, 2022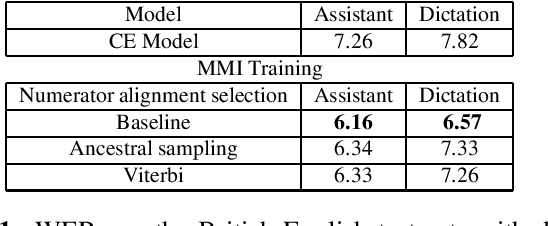
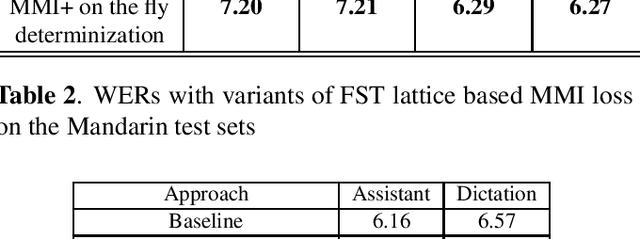
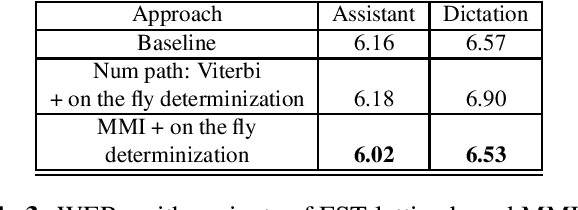
Maximum mutual information (MMI) has become one of the two de facto methods for sequence-level training of speech recognition acoustic models. This paper aims to isolate, identify and bring forward the implicit modelling decisions induced by the design implementation of standard finite state transducer (FST) lattice based MMI training framework. The paper particularly investigates the necessity to maintain a preselected numerator alignment and raises the importance of determinizing FST denominator lattices on the fly. The efficacy of employing on the fly FST lattice determinization is mathematically shown to guarantee discrimination at the hypothesis level and is empirically shown through training deep CNN models on a 18K hours Mandarin dataset and on a 2.8K hours English dataset. On assistant and dictation tasks, the approach achieves between 2.3-4.6% relative WER reduction (WERR) over the standard FST lattice based approach.
A Distributed Optimisation Framework Combining Natural Gradient with Hessian-Free for Discriminative Sequence Training
Mar 12, 2021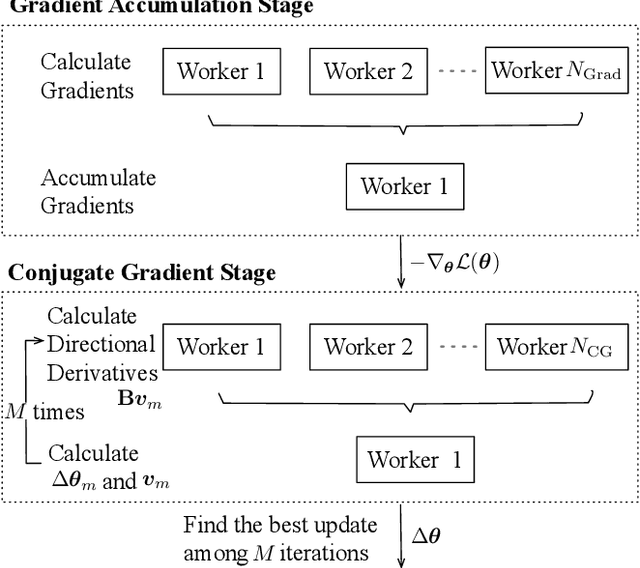

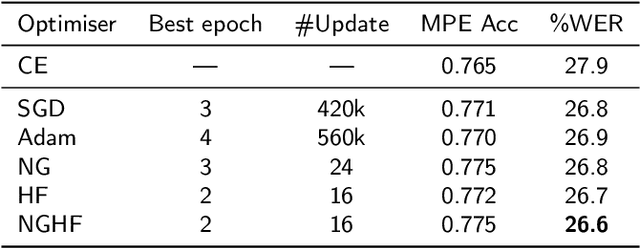
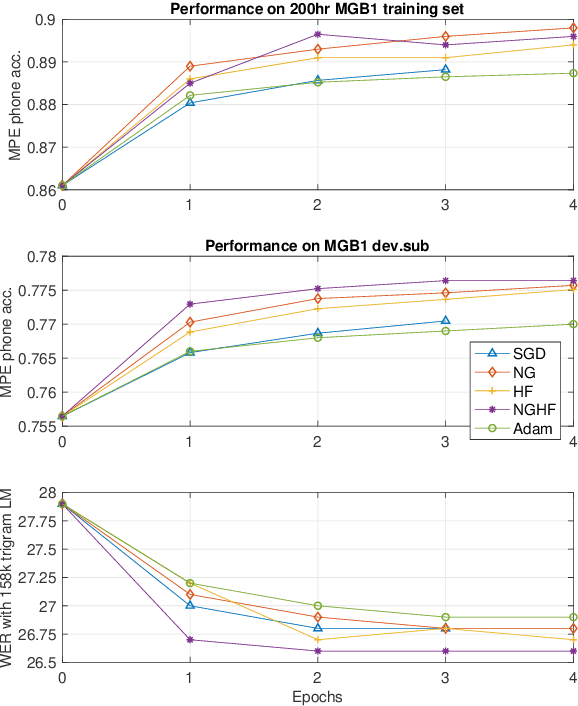
This paper presents a novel natural gradient and Hessian-free (NGHF) optimisation framework for neural network training that can operate efficiently in a distributed manner. It relies on the linear conjugate gradient (CG) algorithm to combine the natural gradient (NG) method with local curvature information from Hessian-free (HF) or other second-order methods. A solution to a numerical issue in CG allows effective parameter updates to be generated with far fewer CG iterations than usually used (e.g. 5-8 instead of 200). This work also presents a novel preconditioning approach to improve the progress made by individual CG iterations for models with shared parameters. Although applicable to other training losses and model structures, NGHF is investigated in this paper for lattice-based discriminative sequence training for hybrid hidden Markov model acoustic models using a standard recurrent neural network, long short-term memory, and time delay neural network models for output probability calculation. Automatic speech recognition experiments are reported on the multi-genre broadcast data set for a range of different acoustic model types. These experiments show that NGHF achieves larger word error rate reductions than standard stochastic gradient descent or Adam, while requiring orders of magnitude fewer parameter updates.
Combining Natural Gradient with Hessian Free Methods for Sequence Training
Oct 03, 2018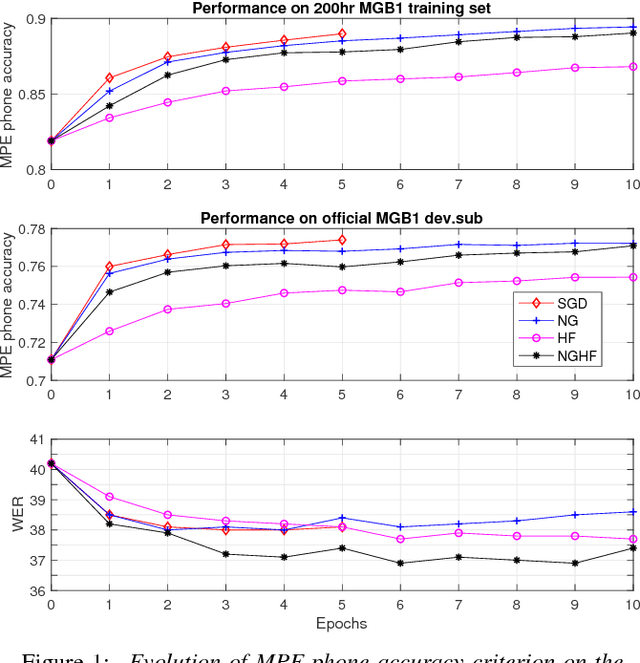
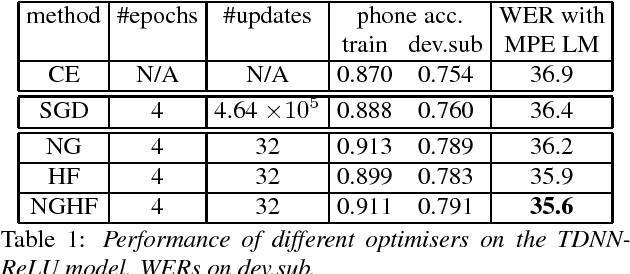
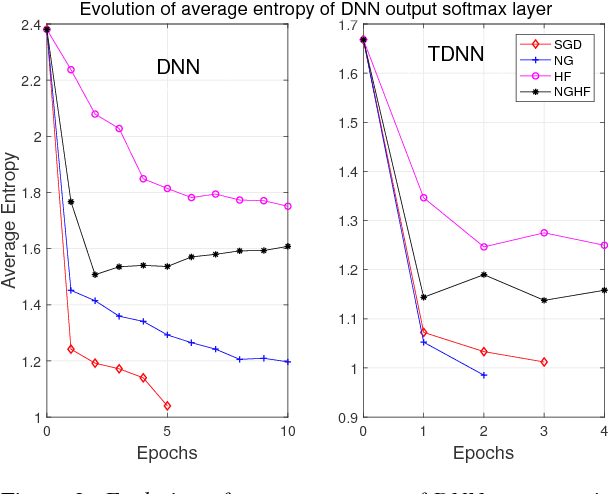
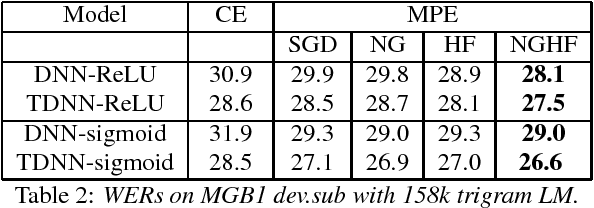
This paper presents a new optimisation approach to train Deep Neural Networks (DNNs) with discriminative sequence criteria. At each iteration, the method combines information from the Natural Gradient (NG) direction with local curvature information of the error surface that enables better paths on the parameter manifold to be traversed. The method is derived using an alternative derivation of Taylor's theorem using the concepts of manifolds, tangent vectors and directional derivatives from the perspective of Information Geometry. The efficacy of the method is shown within a Hessian Free (HF) style optimisation framework to sequence train both standard fully-connected DNNs and Time Delay Neural Networks as speech recognition acoustic models. It is shown that for the same number of updates the proposed approach achieves larger reductions in the word error rate (WER) than both NG and HF, and also leads to a lower WER than standard stochastic gradient descent. The paper also addresses the issue of over-fitting due to mismatch between training criterion and Word Error Rate (WER) that primarily arises during sequence training of ReLU-DNN models.
A Common Framework for Natural Gradient and Taylor based Optimisation using Manifold Theory
Oct 03, 2018This technical report constructs a theoretical framework to relate standard Taylor approximation based optimisation methods with Natural Gradient (NG), a method which is Fisher efficient with probabilistic models. Such a framework will be shown to also provide mathematical justification to combine higher order methods with the method of NG.
Sequence Training of DNN Acoustic Models With Natural Gradient
Apr 06, 2018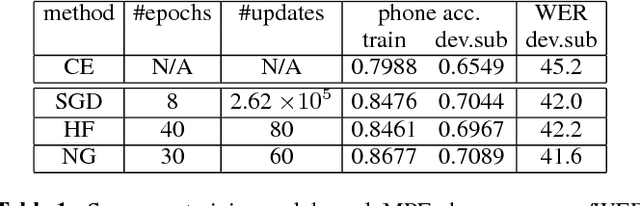
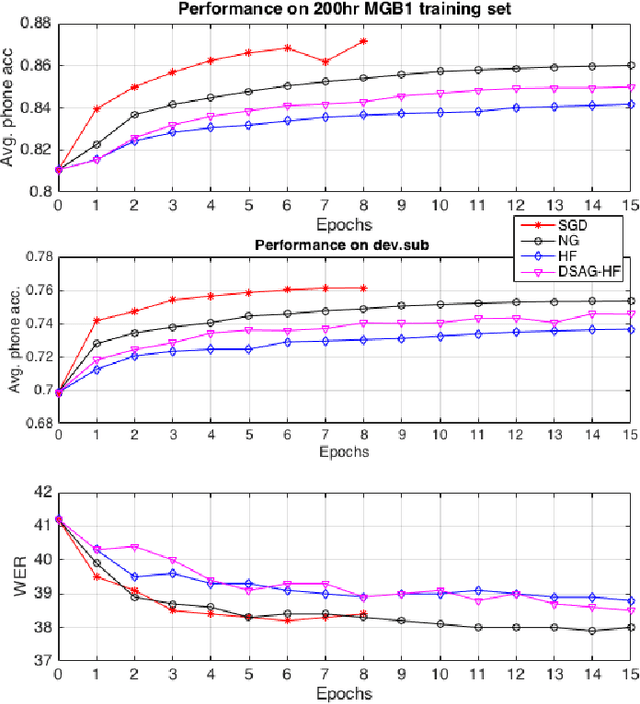
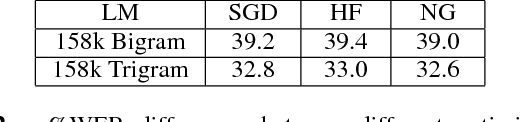
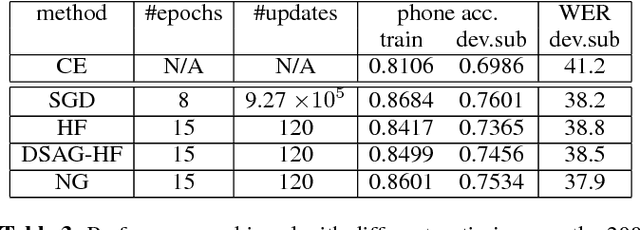
Deep Neural Network (DNN) acoustic models often use discriminative sequence training that optimises an objective function that better approximates the word error rate (WER) than frame-based training. Sequence training is normally implemented using Stochastic Gradient Descent (SGD) or Hessian Free (HF) training. This paper proposes an alternative batch style optimisation framework that employs a Natural Gradient (NG) approach to traverse through the parameter space. By correcting the gradient according to the local curvature of the KL-divergence, the NG optimisation process converges more quickly than HF. Furthermore, the proposed NG approach can be applied to any sequence discriminative training criterion. The efficacy of the NG method is shown using experiments on a Multi-Genre Broadcast (MGB) transcription task that demonstrates both the computational efficiency and the accuracy of the resulting DNN models.