 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDelayed Fusion: Integrating Large Language Models into First-Pass Decoding in End-to-end Speech Recognition
Jan 16, 2025This paper presents an efficient decoding approach for end-to-end automatic speech recognition (E2E-ASR) with large language models (LLMs). Although shallow fusion is the most common approach to incorporate language models into E2E-ASR decoding, we face two practical problems with LLMs. (1) LLM inference is computationally costly. (2) There may be a vocabulary mismatch between the ASR model and the LLM. To resolve this mismatch, we need to retrain the ASR model and/or the LLM, which is at best time-consuming and in many cases not feasible. We propose "delayed fusion," which applies LLM scores to ASR hypotheses with a delay during decoding and enables easier use of pre-trained LLMs in ASR tasks. This method can reduce not only the number of hypotheses scored by the LLM but also the number of LLM inference calls. It also allows re-tokenizion of ASR hypotheses during decoding if ASR and LLM employ different tokenizations. We demonstrate that delayed fusion provides improved decoding speed and accuracy compared to shallow fusion and N-best rescoring using the LibriHeavy ASR corpus and three public LLMs, OpenLLaMA 3B & 7B and Mistral 7B.
DiCoW: Diarization-Conditioned Whisper for Target Speaker Automatic Speech Recognition
Dec 30, 2024Speaker-attributed automatic speech recognition (ASR) in multi-speaker environments remains a significant challenge, particularly when systems conditioned on speaker embeddings fail to generalize to unseen speakers. In this work, we propose Diarization-Conditioned Whisper (DiCoW), a novel approach to target-speaker ASR that leverages speaker diarization outputs as conditioning information. DiCoW extends the pre-trained Whisper model by integrating diarization labels directly, eliminating reliance on speaker embeddings and reducing the need for extensive speaker-specific training data. Our method introduces frame-level diarization-dependent transformations (FDDT) and query-key biasing (QKb) techniques to refine the model's focus on target speakers while effectively handling overlapping speech. By leveraging diarization outputs as conditioning signals, DiCoW simplifies the workflow for multi-speaker ASR, improves generalization to unseen speakers and enables more reliable transcription in real-world multi-speaker recordings. Additionally, we explore the integration of a connectionist temporal classification (CTC) head to Whisper and demonstrate its ability to improve transcription efficiency through hybrid decoding. Notably, we show that our approach is not limited to Whisper; it also provides similar benefits when applied to the Branchformer model. We validate DiCoW on real-world datasets, including AMI and NOTSOFAR-1 from CHiME-8 challenge, as well as synthetic benchmarks such as Libri2Mix and LibriCSS, enabling direct comparisons with previous methods. Results demonstrate that DiCoW enhances the model's target-speaker ASR capabilities while maintaining Whisper's accuracy and robustness on single-speaker data.
Hystoc: Obtaining word confidences for fusion of end-to-end ASR systems
May 21, 2023End-to-end (e2e) systems have recently gained wide popularity in automatic speech recognition. However, these systems do generally not provide well-calibrated word-level confidences. In this paper, we propose Hystoc, a simple method for obtaining word-level confidences from hypothesis-level scores. Hystoc is an iterative alignment procedure which turns hypotheses from an n-best output of the ASR system into a confusion network. Eventually, word-level confidences are obtained as posterior probabilities in the individual bins of the confusion network. We show that Hystoc provides confidences that correlate well with the accuracy of the ASR hypothesis. Furthermore, we show that utilizing Hystoc in fusion of multiple e2e ASR systems increases the gains from the fusion by up to 1\,\% WER absolute on Spanish RTVE2020 dataset. Finally, we experiment with using Hystoc for direct fusion of n-best outputs from multiple systems, but we only achieve minor gains when fusing very similar systems.
ATCO2 corpus: A Large-Scale Dataset for Research on Automatic Speech Recognition and Natural Language Understanding of Air Traffic Control Communications
Nov 08, 2022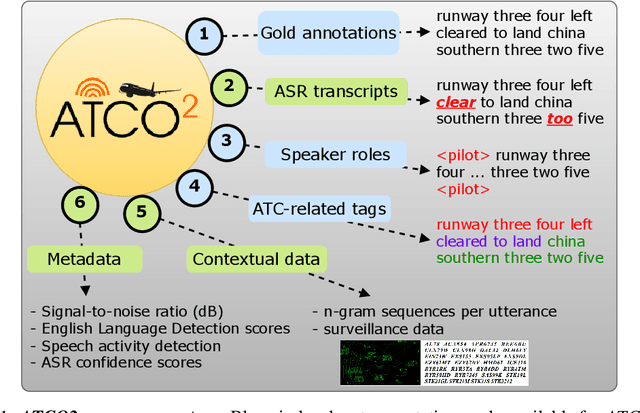
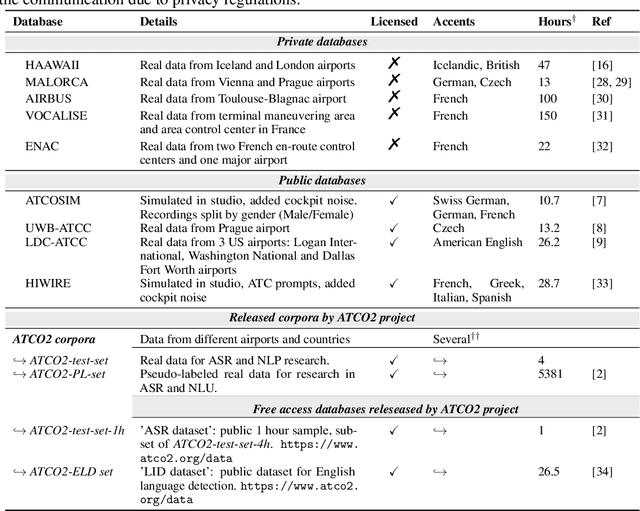
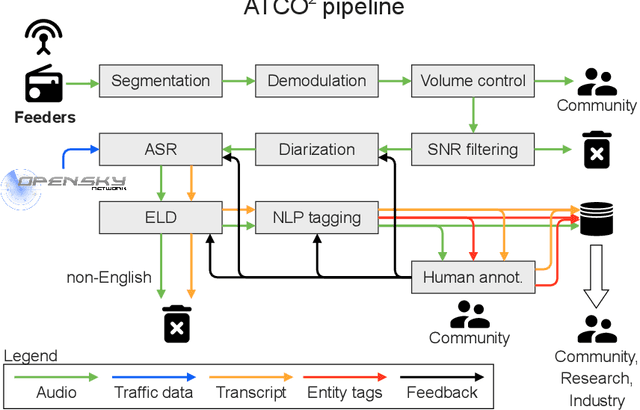

Personal assistants, automatic speech recognizers and dialogue understanding systems are becoming more critical in our interconnected digital world. A clear example is air traffic control (ATC) communications. ATC aims at guiding aircraft and controlling the airspace in a safe and optimal manner. These voice-based dialogues are carried between an air traffic controller (ATCO) and pilots via very-high frequency radio channels. In order to incorporate these novel technologies into ATC (low-resource domain), large-scale annotated datasets are required to develop the data-driven AI systems. Two examples are automatic speech recognition (ASR) and natural language understanding (NLU). In this paper, we introduce the ATCO2 corpus, a dataset that aims at fostering research on the challenging ATC field, which has lagged behind due to lack of annotated data. The ATCO2 corpus covers 1) data collection and pre-processing, 2) pseudo-annotations of speech data, and 3) extraction of ATC-related named entities. The ATCO2 corpus is split into three subsets. 1) ATCO2-test-set corpus contains 4 hours of ATC speech with manual transcripts and a subset with gold annotations for named-entity recognition (callsign, command, value). 2) The ATCO2-PL-set corpus consists of 5281 hours of unlabeled ATC data enriched with automatic transcripts from an in-domain speech recognizer, contextual information, speaker turn information, signal-to-noise ratio estimate and English language detection score per sample. Both available for purchase through ELDA at http://catalog.elra.info/en-us/repository/browse/ELRA-S0484. 3) The ATCO2-test-set-1h corpus is a one-hour subset from the original test set corpus, that we are offering for free at https://www.atco2.org/data. We expect the ATCO2 corpus will foster research on robust ASR and NLU not only in the field of ATC communications but also in the general research community.
Analysis of impact of emotions on target speech extraction and speech separation
Aug 15, 2022
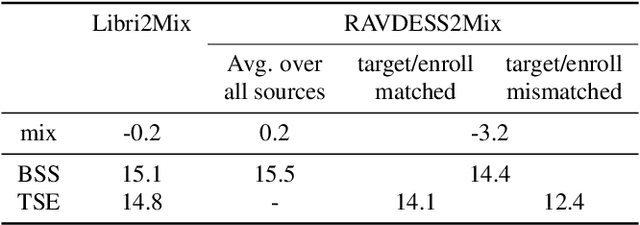

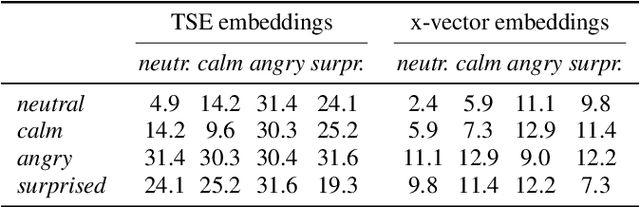
Recently, the performance of blind speech separation (BSS) and target speech extraction (TSE) has greatly progressed. Most works, however, focus on relatively well-controlled conditions using, e.g., read speech. The performance may degrade in more realistic situations. One of the factors causing such degradation may be intrinsic speaker variability, such as emotions, occurring commonly in realistic speech. In this paper, we investigate the influence of emotions on TSE and BSS. We create a new test dataset of emotional mixtures for the evaluation of TSE and BSS. This dataset combines LibriSpeech and Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS). Through controlled experiments, we can analyze the impact of different emotions on the performance of BSS and TSE. We observe that BSS is relatively robust to emotions, while TSE, which requires identifying and extracting the speech of a target speaker, is much more sensitive to emotions. On comparative speaker verification experiments we show that identifying the target speaker may be particularly challenging when dealing with emotional speech. Using our findings, we outline potential future directions that could improve the robustness of BSS and TSE systems toward emotional speech.
Call-sign recognition and understanding for noisy air-traffic transcripts using surveillance information
Apr 13, 2022

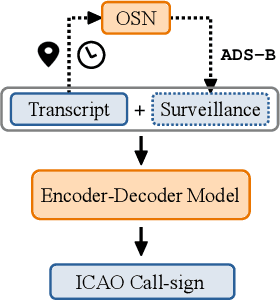
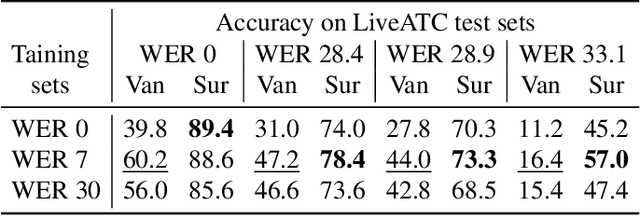
Air traffic control (ATC) relies on communication via speech between pilot and air-traffic controller (ATCO). The call-sign, as unique identifier for each flight, is used to address a specific pilot by the ATCO. Extracting the call-sign from the communication is a challenge because of the noisy ATC voice channel and the additional noise introduced by the receiver. A low signal-to-noise ratio (SNR) in the speech leads to high word error rate (WER) transcripts. We propose a new call-sign recognition and understanding (CRU) system that addresses this issue. The recognizer is trained to identify call-signs in noisy ATC transcripts and convert them into the standard International Civil Aviation Organization (ICAO) format. By incorporating surveillance information, we can multiply the call-sign accuracy (CSA) up to a factor of four. The introduced data augmentation adds additional performance on high WER transcripts and allows the adaptation of the model to unseen airspaces.
Revisiting joint decoding based multi-talker speech recognition with DNN acoustic model
Oct 31, 2021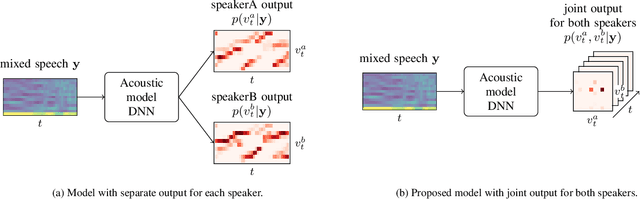
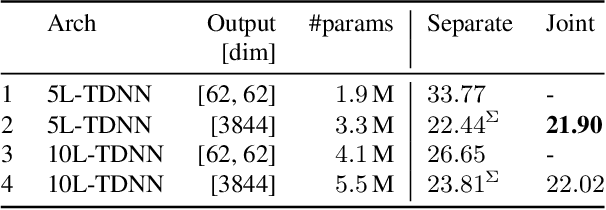
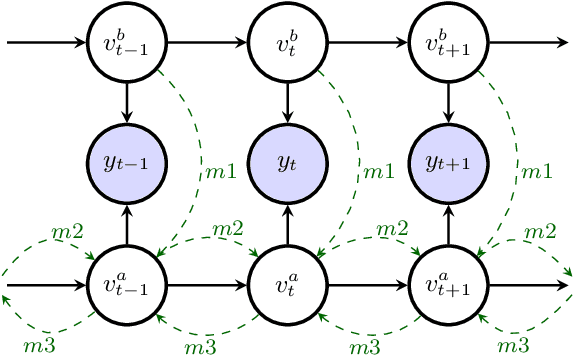
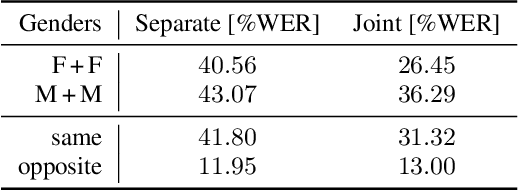
In typical multi-talker speech recognition systems, a neural network-based acoustic model predicts senone state posteriors for each speaker. These are later used by a single-talker decoder which is applied on each speaker-specific output stream separately. In this work, we argue that such a scheme is sub-optimal and propose a principled solution that decodes all speakers jointly. We modify the acoustic model to predict joint state posteriors for all speakers, enabling the network to express uncertainty about the attribution of parts of the speech signal to the speakers. We employ a joint decoder that can make use of this uncertainty together with higher-level language information. For this, we revisit decoding algorithms used in factorial generative models in early multi-talker speech recognition systems. In contrast with these early works, we replace the GMM acoustic model with DNN, which provides greater modeling power and simplifies part of the inference. We demonstrate the advantage of joint decoding in proof of concept experiments on a mixed-TIDIGITS dataset.
Contextual Semi-Supervised Learning: An Approach To Leverage Air-Surveillance and Untranscribed ATC Data in ASR Systems
Apr 08, 2021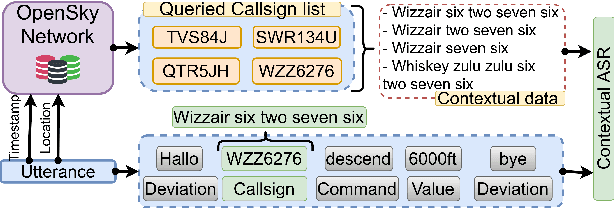
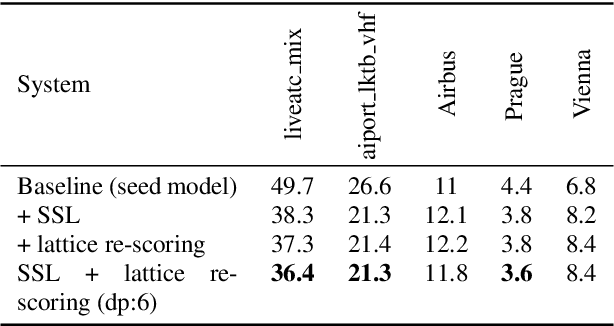


Air traffic management and specifically air-traffic control (ATC) rely mostly on voice communications between Air Traffic Controllers (ATCos) and pilots. In most cases, these voice communications follow a well-defined grammar that could be leveraged in Automatic Speech Recognition (ASR) technologies. The callsign used to address an airplane is an essential part of all ATCo-pilot communications. We propose a two-steps approach to add contextual knowledge during semi-supervised training to reduce the ASR system error rates at recognizing the part of the utterance that contains the callsign. Initially, we represent in a WFST the contextual knowledge (i.e. air-surveillance data) of an ATCo-pilot communication. Then, during Semi-Supervised Learning (SSL) the contextual knowledge is added by second-pass decoding (i.e. lattice re-scoring). Results show that `unseen domains' (e.g. data from airports not present in the supervised training data) are further aided by contextual SSL when compared to standalone SSL. For this task, we introduce the Callsign Word Error Rate (CA-WER) as an evaluation metric, which only assesses ASR performance of the spoken callsign in an utterance. We obtained a 32.1% CA-WER relative improvement applying SSL with an additional 17.5% CA-WER improvement by adding contextual knowledge during SSL on a challenging ATC-based test set gathered from LiveATC.
Detecting English Speech in the Air Traffic Control Voice Communication
Apr 06, 2021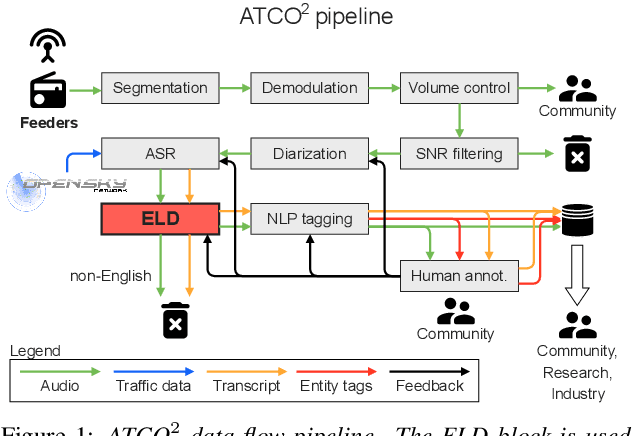
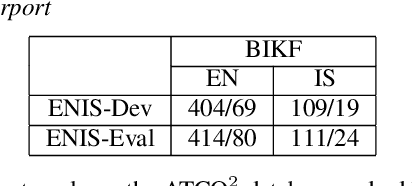

We launched a community platform for collecting the ATC speech world-wide in the ATCO2 project. Filtering out unseen non-English speech is one of the main components in the data processing pipeline. The proposed English Language Detection (ELD) system is based on the embeddings from Bayesian subspace multinomial model. It is trained on the word confusion network from an ASR system. It is robust, easy to train, and light weighted. We achieved 0.0439 equal-error-rate (EER), a 50% relative reduction as compared to the state-of-the-art acoustic ELD system based on x-vectors, in the in-domain scenario. Further, we achieved an EER of 0.1352, a 33% relative reduction as compared to the acoustic ELD, in the unseen language (out-of-domain) condition. We plan to publish the evaluation dataset from the ATCO2 project.
BCN2BRNO: ASR System Fusion for Albayzin 2020 Speech to Text Challenge
Jan 29, 2021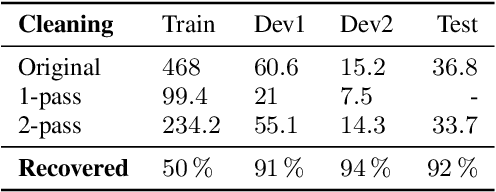
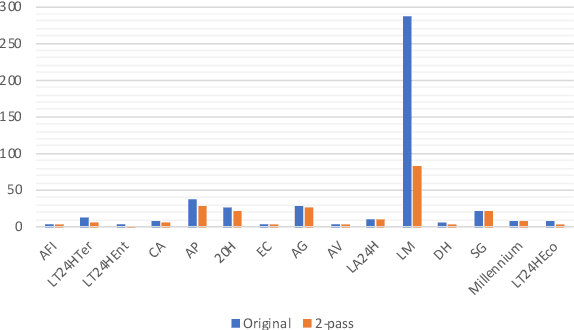
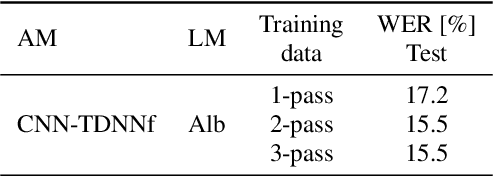
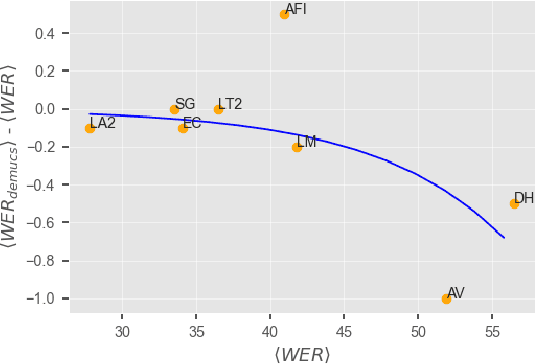
This paper describes joint effort of BUT and Telef\'onica Research on development of Automatic Speech Recognition systems for Albayzin 2020 Challenge. We compare approaches based on either hybrid or end-to-end models. In hybrid modelling, we explore the impact of SpecAugment layer on performance. For end-to-end modelling, we used a convolutional neural network with gated linear units (GLUs). The performance of such model is also evaluated with an additional n-gram language model to improve word error rates. We further inspect source separation methods to extract speech from noisy environment (i.e. TV shows). More precisely, we assess the effect of using a neural-based music separator named Demucs. A fusion of our best systems achieved 23.33% WER in official Albayzin 2020 evaluations. Aside from techniques used in our final submitted systems, we also describe our efforts in retrieving high quality transcripts for training.