 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGSRM: Generative Speech Reward Model for Speech RLHF
Feb 14, 2026Recent advances in speech language models, such as GPT-4o Voice Mode and Gemini Live, have demonstrated promising speech generation capabilities. Nevertheless, the aesthetic naturalness of the synthesized audio still lags behind that of human speech. Enhancing generation quality requires a reliable evaluator of speech naturalness. However, existing naturalness evaluators typically regress raw audio to scalar scores, offering limited interpretability of the evaluation and moreover fail to generalize to speech across different taxonomies. Inspired by recent advances in generative reward modeling, we propose the Generative Speech Reward Model (GSRM), a reasoning-centric reward model tailored for speech. The GSRM is trained to decompose speech naturalness evaluation into an interpretable acoustic feature extraction stage followed by feature-grounded chain-of-thought reasoning, enabling explainable judgments. To achieve this, we curated a large-scale human feedback dataset comprising 31k expert ratings and an out-of-domain benchmark of real-world user-assistant speech interactions. Experiments show that GSRM substantially outperforms existing speech naturalness predictors, achieving model-human correlation of naturalness score prediction that approaches human inter-rater consistency. We further show how GSRM can improve the naturalness of speech LLM generations by serving as an effective verifier for online RLHF.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Analysis of impact of emotions on target speech extraction and speech separation
Aug 15, 2022
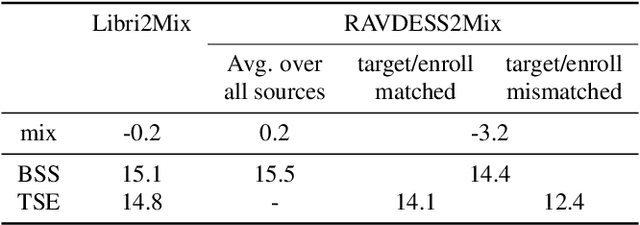

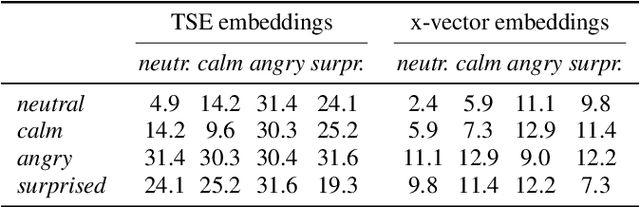
Recently, the performance of blind speech separation (BSS) and target speech extraction (TSE) has greatly progressed. Most works, however, focus on relatively well-controlled conditions using, e.g., read speech. The performance may degrade in more realistic situations. One of the factors causing such degradation may be intrinsic speaker variability, such as emotions, occurring commonly in realistic speech. In this paper, we investigate the influence of emotions on TSE and BSS. We create a new test dataset of emotional mixtures for the evaluation of TSE and BSS. This dataset combines LibriSpeech and Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS). Through controlled experiments, we can analyze the impact of different emotions on the performance of BSS and TSE. We observe that BSS is relatively robust to emotions, while TSE, which requires identifying and extracting the speech of a target speaker, is much more sensitive to emotions. On comparative speaker verification experiments we show that identifying the target speaker may be particularly challenging when dealing with emotional speech. Using our findings, we outline potential future directions that could improve the robustness of BSS and TSE systems toward emotional speech.
Revisiting joint decoding based multi-talker speech recognition with DNN acoustic model
Oct 31, 2021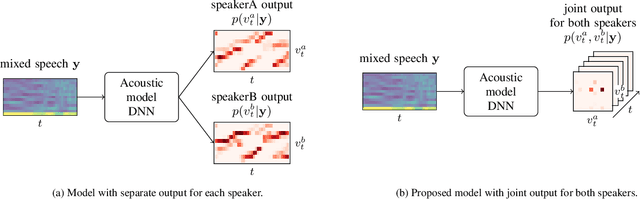
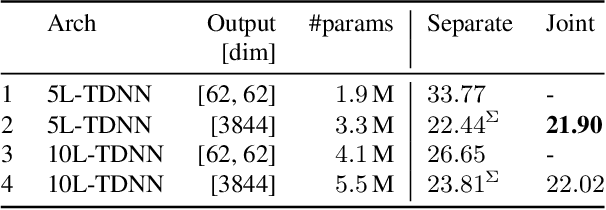
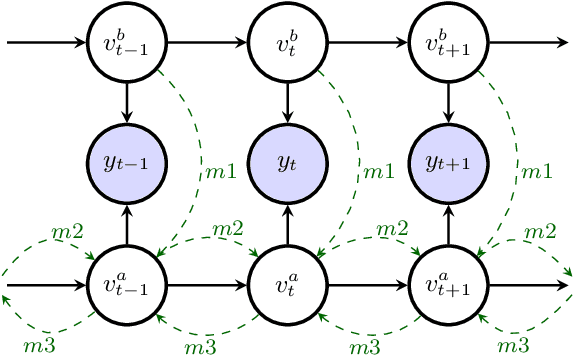
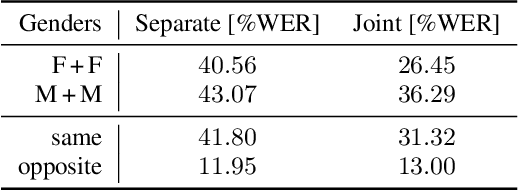
In typical multi-talker speech recognition systems, a neural network-based acoustic model predicts senone state posteriors for each speaker. These are later used by a single-talker decoder which is applied on each speaker-specific output stream separately. In this work, we argue that such a scheme is sub-optimal and propose a principled solution that decodes all speakers jointly. We modify the acoustic model to predict joint state posteriors for all speakers, enabling the network to express uncertainty about the attribution of parts of the speech signal to the speakers. We employ a joint decoder that can make use of this uncertainty together with higher-level language information. For this, we revisit decoding algorithms used in factorial generative models in early multi-talker speech recognition systems. In contrast with these early works, we replace the GMM acoustic model with DNN, which provides greater modeling power and simplifies part of the inference. We demonstrate the advantage of joint decoding in proof of concept experiments on a mixed-TIDIGITS dataset.