 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproaching Dialogue State Tracking via Aligning Speech Encoders and LLMs
Jun 10, 2025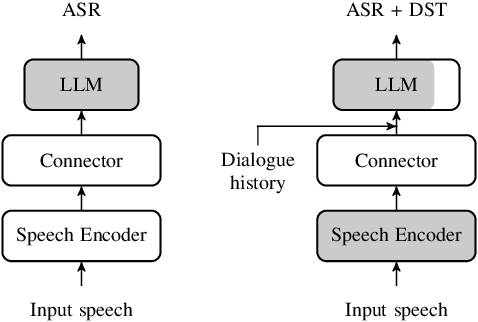
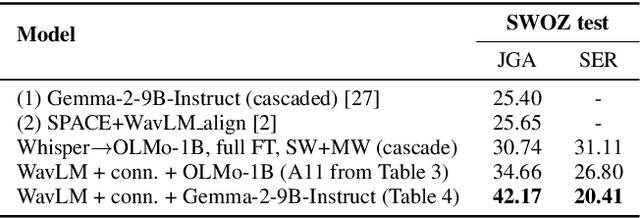
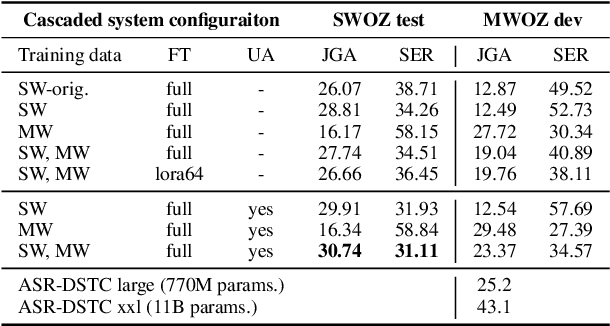
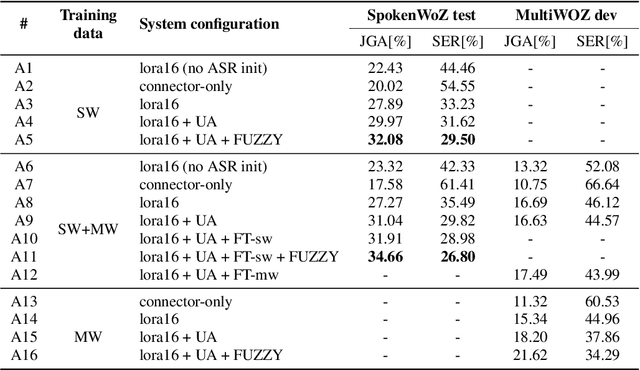
In this work, we approach spoken Dialogue State Tracking (DST) by bridging the representation spaces of speech encoders and LLMs via a small connector module, with a focus on fully open-sourced and open-data components (WavLM-large, OLMo). We focus on ablating different aspects of such systems including full/LoRA adapter fine-tuning, the effect of agent turns in the dialogue history, as well as fuzzy matching-based output post-processing, which greatly improves performance of our systems on named entities in the dialogue slot values. We conduct our experiments on the SpokenWOZ dataset, and additionally utilize the Speech-Aware MultiWOZ dataset to augment our training data. Ultimately, our best-performing WavLM + connector + OLMo-1B aligned models achieve state of the art on the SpokenWOZ test set (34.66% JGA), and our system with Gemma-2-9B-instruct further surpasses this result, reaching 42.17% JGA on SpokenWOZ test.
Analysis of impact of emotions on target speech extraction and speech separation
Aug 15, 2022
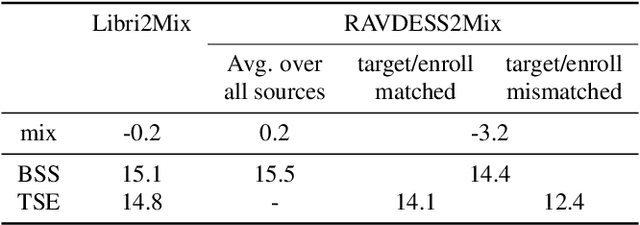

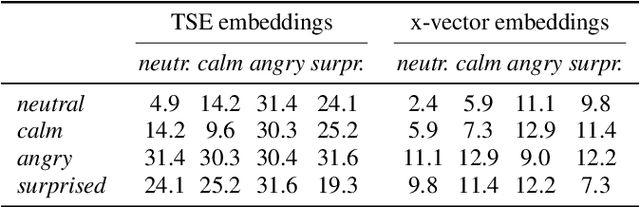
Recently, the performance of blind speech separation (BSS) and target speech extraction (TSE) has greatly progressed. Most works, however, focus on relatively well-controlled conditions using, e.g., read speech. The performance may degrade in more realistic situations. One of the factors causing such degradation may be intrinsic speaker variability, such as emotions, occurring commonly in realistic speech. In this paper, we investigate the influence of emotions on TSE and BSS. We create a new test dataset of emotional mixtures for the evaluation of TSE and BSS. This dataset combines LibriSpeech and Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS). Through controlled experiments, we can analyze the impact of different emotions on the performance of BSS and TSE. We observe that BSS is relatively robust to emotions, while TSE, which requires identifying and extracting the speech of a target speaker, is much more sensitive to emotions. On comparative speaker verification experiments we show that identifying the target speaker may be particularly challenging when dealing with emotional speech. Using our findings, we outline potential future directions that could improve the robustness of BSS and TSE systems toward emotional speech.
Revisiting joint decoding based multi-talker speech recognition with DNN acoustic model
Oct 31, 2021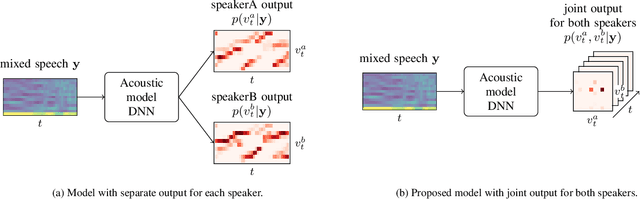
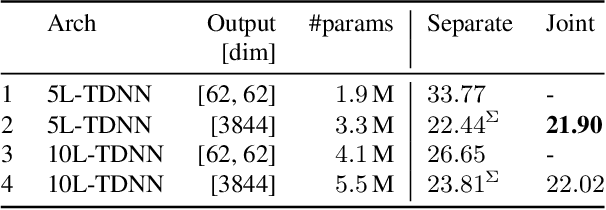
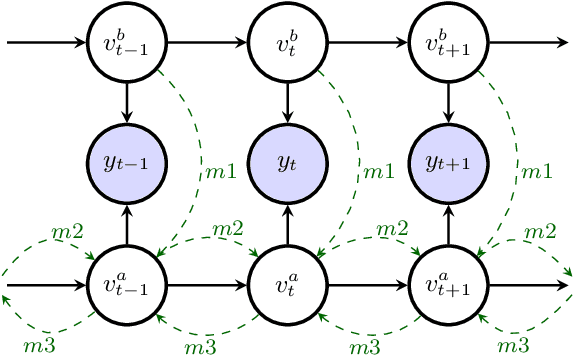
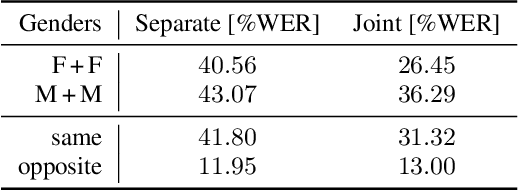
In typical multi-talker speech recognition systems, a neural network-based acoustic model predicts senone state posteriors for each speaker. These are later used by a single-talker decoder which is applied on each speaker-specific output stream separately. In this work, we argue that such a scheme is sub-optimal and propose a principled solution that decodes all speakers jointly. We modify the acoustic model to predict joint state posteriors for all speakers, enabling the network to express uncertainty about the attribution of parts of the speech signal to the speakers. We employ a joint decoder that can make use of this uncertainty together with higher-level language information. For this, we revisit decoding algorithms used in factorial generative models in early multi-talker speech recognition systems. In contrast with these early works, we replace the GMM acoustic model with DNN, which provides greater modeling power and simplifies part of the inference. We demonstrate the advantage of joint decoding in proof of concept experiments on a mixed-TIDIGITS dataset.