 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
ICQuant: Index Coding enables Low-bit LLM Quantization
May 01, 2025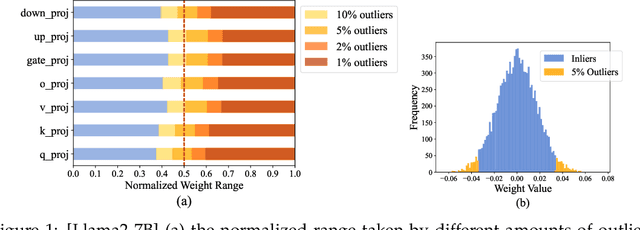

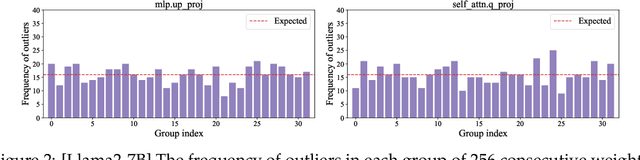
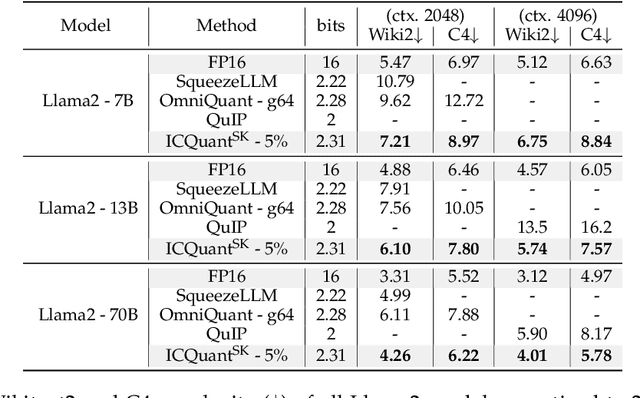
The rapid deployment of Large Language Models (LLMs) highlights the need for efficient low-bit post-training quantization (PTQ), due to their high memory costs. A key challenge in weight quantization is the presence of outliers, which inflate quantization ranges and lead to large errors. While a number of outlier suppression techniques have been proposed, they either: fail to effectively shrink the quantization range, or incur (relatively) high bit overhead. In this paper, we present ICQuant, a novel framework that leverages outlier statistics to design an efficient index coding scheme for outlier-aware weight-only quantization. Compared to existing outlier suppression techniques requiring $\approx 1$ bit overhead to halve the quantization range, ICQuant requires only $\approx 0.3$ bits; a significant saving in extreme compression regimes (e.g., 2-3 bits per weight). ICQuant can be used on top of any existing quantizers to eliminate outliers, improving the quantization quality. Using just 2.3 bits per weight and simple scalar quantizers, ICQuant improves the zero-shot accuracy of the 2-bit Llama3-70B model by up to 130% and 150% relative to QTIP and QuIP#; and it achieves comparable performance to the best-known fine-tuned quantizer (PV-tuning) without fine-tuning.
Does Feedback Help in Bandits with Arm Erasures?
Apr 29, 2025We study a distributed multi-armed bandit (MAB) problem over arm erasure channels, motivated by the increasing adoption of MAB algorithms over communication-constrained networks. In this setup, the learner communicates the chosen arm to play to an agent over an erasure channel with probability $\epsilon \in [0,1)$; if an erasure occurs, the agent continues pulling the last successfully received arm; the learner always observes the reward of the arm pulled. In past work, we considered the case where the agent cannot convey feedback to the learner, and thus the learner does not know whether the arm played is the requested or the last successfully received one. In this paper, we instead consider the case where the agent can send feedback to the learner on whether the arm request was received, and thus the learner exactly knows which arm was played. Surprisingly, we prove that erasure feedback does not improve the worst-case regret upper bound order over the previously studied no-feedback setting. In particular, we prove a regret lower bound of $\Omega(\sqrt{KT} + K / (1 - \epsilon))$, where $K$ is the number of arms and $T$ the time horizon, that matches no-feedback upper bounds up to logarithmic factors. We note however that the availability of feedback enables simpler algorithm designs that may achieve better constants (albeit not better order) regret bounds; we design one such algorithm and evaluate its performance numerically.
InfoMAE: Pair-Efficient Cross-Modal Alignment for Multimodal Time-Series Sensing Signals
Apr 13, 2025Standard multimodal self-supervised learning (SSL) algorithms regard cross-modal synchronization as implicit supervisory labels during pretraining, thus posing high requirements on the scale and quality of multimodal samples. These constraints significantly limit the performance of sensing intelligence in IoT applications, as the heterogeneity and the non-interpretability of time-series signals result in abundant unimodal data but scarce high-quality multimodal pairs. This paper proposes InfoMAE, a cross-modal alignment framework that tackles the challenge of multimodal pair efficiency under the SSL setting by facilitating efficient cross-modal alignment of pretrained unimodal representations. InfoMAE achieves \textit{efficient cross-modal alignment} with \textit{limited data pairs} through a novel information theory-inspired formulation that simultaneously addresses distribution-level and instance-level alignment. Extensive experiments on two real-world IoT applications are performed to evaluate InfoMAE's pairing efficiency to bridge pretrained unimodal models into a cohesive joint multimodal model. InfoMAE enhances downstream multimodal tasks by over 60% with significantly improved multimodal pairing efficiency. It also improves unimodal task accuracy by an average of 22%.
Learning for Bandits under Action Erasures
Jun 26, 2024We consider a novel multi-arm bandit (MAB) setup, where a learner needs to communicate the actions to distributed agents over erasure channels, while the rewards for the actions are directly available to the learner through external sensors. In our model, while the distributed agents know if an action is erased, the central learner does not (there is no feedback), and thus does not know whether the observed reward resulted from the desired action or not. We propose a scheme that can work on top of any (existing or future) MAB algorithm and make it robust to action erasures. Our scheme results in a worst-case regret over action-erasure channels that is at most a factor of $O(1/\sqrt{1-\epsilon})$ away from the no-erasure worst-case regret of the underlying MAB algorithm, where $\epsilon$ is the erasure probability. We also propose a modification of the successive arm elimination algorithm and prove that its worst-case regret is $\Tilde{O}(\sqrt{KT}+K/(1-\epsilon))$, which we prove is optimal by providing a matching lower bound.