 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-ResNets for Subspace Preconditioning in Constrained Optimization
Jun 04, 2026We propose MResOpt, a staged residual neural network architecture for constrained optimization problems. Our architecture fits within predict-complete-correct pipelines and decomposes constraint satisfaction by priority through intermediate re-completion and stage-aware losses. The framework enables domain-informed ordered constraint satisfaction which allows the network to utilize ordinal structure when present. Under an idealized infinite-width regime, we show that our design behaves as sequential Gaussian Process regression. On synthetic QP, QCQP, and SOCP benchmarks, the staged architecture improves high-priority constraint satisfaction across convex and non-convex settings. On line-flow-constrained AC optimal power flow, we introduce a physics-motivated constraint ordering and show that MResOpt supports a learned division of labor that keeps iterates on the equality manifold, achieving substantially lower high-priority violation than reprojected baselines while remaining computationally efficient.
Best-Arm Identification with Noisy Actuation
Apr 02, 2026In this paper, we consider a multi-armed bandit (MAB) instance and study how to identify the best arm when arm commands are conveyed from a central learner to a distributed agent over a discrete memoryless channel (DMC). Depending on the agent capabilities, we provide communication schemes along with their analysis, which interestingly relate to the zero-error capacity of the underlying DMC.
Does Feedback Help in Bandits with Arm Erasures?
Apr 29, 2025We study a distributed multi-armed bandit (MAB) problem over arm erasure channels, motivated by the increasing adoption of MAB algorithms over communication-constrained networks. In this setup, the learner communicates the chosen arm to play to an agent over an erasure channel with probability $\epsilon \in [0,1)$; if an erasure occurs, the agent continues pulling the last successfully received arm; the learner always observes the reward of the arm pulled. In past work, we considered the case where the agent cannot convey feedback to the learner, and thus the learner does not know whether the arm played is the requested or the last successfully received one. In this paper, we instead consider the case where the agent can send feedback to the learner on whether the arm request was received, and thus the learner exactly knows which arm was played. Surprisingly, we prove that erasure feedback does not improve the worst-case regret upper bound order over the previously studied no-feedback setting. In particular, we prove a regret lower bound of $\Omega(\sqrt{KT} + K / (1 - \epsilon))$, where $K$ is the number of arms and $T$ the time horizon, that matches no-feedback upper bounds up to logarithmic factors. We note however that the availability of feedback enables simpler algorithm designs that may achieve better constants (albeit not better order) regret bounds; we design one such algorithm and evaluate its performance numerically.
Learning for Bandits under Action Erasures
Jun 26, 2024We consider a novel multi-arm bandit (MAB) setup, where a learner needs to communicate the actions to distributed agents over erasure channels, while the rewards for the actions are directly available to the learner through external sensors. In our model, while the distributed agents know if an action is erased, the central learner does not (there is no feedback), and thus does not know whether the observed reward resulted from the desired action or not. We propose a scheme that can work on top of any (existing or future) MAB algorithm and make it robust to action erasures. Our scheme results in a worst-case regret over action-erasure channels that is at most a factor of $O(1/\sqrt{1-\epsilon})$ away from the no-erasure worst-case regret of the underlying MAB algorithm, where $\epsilon$ is the erasure probability. We also propose a modification of the successive arm elimination algorithm and prove that its worst-case regret is $\Tilde{O}(\sqrt{KT}+K/(1-\epsilon))$, which we prove is optimal by providing a matching lower bound.
Multi-Agent Bandit Learning through Heterogeneous Action Erasure Channels
Dec 21, 2023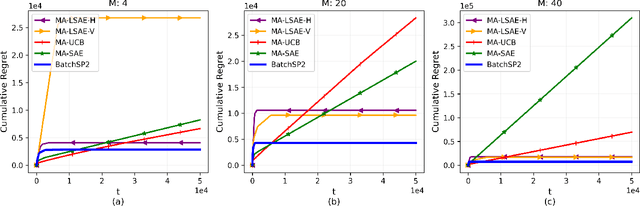
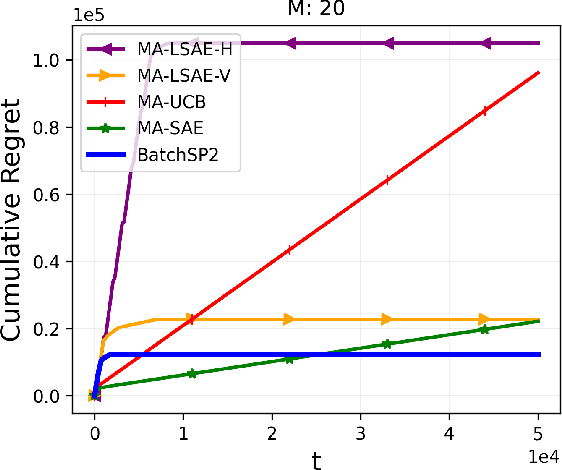


Multi-Armed Bandit (MAB) systems are witnessing an upswing in applications within multi-agent distributed environments, leading to the advancement of collaborative MAB algorithms. In such settings, communication between agents executing actions and the primary learner making decisions can hinder the learning process. A prevalent challenge in distributed learning is action erasure, often induced by communication delays and/or channel noise. This results in agents possibly not receiving the intended action from the learner, subsequently leading to misguided feedback. In this paper, we introduce novel algorithms that enable learners to interact concurrently with distributed agents across heterogeneous action erasure channels with different action erasure probabilities. We illustrate that, in contrast to existing bandit algorithms, which experience linear regret, our algorithms assure sub-linear regret guarantees. Our proposed solutions are founded on a meticulously crafted repetition protocol and scheduling of learning across heterogeneous channels. To our knowledge, these are the first algorithms capable of effectively learning through heterogeneous action erasure channels. We substantiate the superior performance of our algorithm through numerical experiments, emphasizing their practical significance in addressing issues related to communication constraints and delays in multi-agent environments.