 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLM: Removing the GPU Memory Barrier for 3D Gaussian Splatting
Nov 07, 20253D Gaussian Splatting (3DGS) is an increasingly popular novel view synthesis approach due to its fast rendering time, and high-quality output. However, scaling 3DGS to large (or intricate) scenes is challenging due to its large memory requirement, which exceed most GPU's memory capacity. In this paper, we describe CLM, a system that allows 3DGS to render large scenes using a single consumer-grade GPU, e.g., RTX4090. It does so by offloading Gaussians to CPU memory, and loading them into GPU memory only when necessary. To reduce performance and communication overheads, CLM uses a novel offloading strategy that exploits observations about 3DGS's memory access pattern for pipelining, and thus overlap GPU-to-CPU communication, GPU computation and CPU computation. Furthermore, we also exploit observation about the access pattern to reduce communication volume. Our evaluation shows that the resulting implementation can render a large scene that requires 100 million Gaussians on a single RTX4090 and achieve state-of-the-art reconstruction quality.
Computational Performance Bounds Prediction in Quantum Computing with Unstable Noise
Jul 22, 2025Quantum computing has significantly advanced in recent years, boasting devices with hundreds of quantum bits (qubits), hinting at its potential quantum advantage over classical computing. Yet, noise in quantum devices poses significant barriers to realizing this supremacy. Understanding noise's impact is crucial for reproducibility and application reuse; moreover, the next-generation quantum-centric supercomputing essentially requires efficient and accurate noise characterization to support system management (e.g., job scheduling), where ensuring correct functional performance (i.e., fidelity) of jobs on available quantum devices can even be higher-priority than traditional objectives. However, noise fluctuates over time, even on the same quantum device, which makes predicting the computational bounds for on-the-fly noise is vital. Noisy quantum simulation can offer insights but faces efficiency and scalability issues. In this work, we propose a data-driven workflow, namely QuBound, to predict computational performance bounds. It decomposes historical performance traces to isolate noise sources and devises a novel encoder to embed circuit and noise information processed by a Long Short-Term Memory (LSTM) network. For evaluation, we compare QuBound with a state-of-the-art learning-based predictor, which only generates a single performance value instead of a bound. Experimental results show that the result of the existing approach falls outside of performance bounds, while all predictions from our QuBound with the assistance of performance decomposition better fit the bounds. Moreover, QuBound can efficiently produce practical bounds for various circuits with over 106 speedup over simulation; in addition, the range from QuBound is over 10x narrower than the state-of-the-art analytical approach.
TTrace: Lightweight Error Checking and Diagnosis for Distributed Training
Jun 10, 2025Distributed training is essential for scaling the training of large neural network models, such as large language models (LLMs), across thousands of GPUs. However, the complexity of distributed training programs makes them particularly prone to silent bugs, which do not produce explicit error signal but lead to incorrect training outcome. Effectively detecting and localizing such silent bugs in distributed training is challenging. Common debugging practice using metrics like training loss or gradient norm curves can be inefficient and ineffective. Additionally, obtaining intermediate tensor values and determining whether they are correct during silent bug localization is difficult, particularly in the context of low-precision training. To address those challenges, we design and implement TTrace, the first system capable of detecting and localizing silent bugs in distributed training. TTrace collects intermediate tensors from distributing training in a fine-grained manner and compares them against those from a trusted single-device reference implementation. To properly compare the floating-point values in the tensors, we propose novel mathematical analysis that provides a guideline for setting thresholds, enabling TTrace to distinguish bug-induced errors from floating-point round-off errors. Experimental results demonstrate that TTrace effectively detects 11 existing bugs and 3 new bugs in the widely used Megatron-LM framework, while requiring fewer than 10 lines of code change. TTrace is effective in various training recipes, including low-precision recipes involving BF16 and FP8.
Micro-Act: Mitigate Knowledge Conflict in Question Answering via Actionable Self-Reasoning
Jun 05, 2025Retrieval-Augmented Generation (RAG) systems commonly suffer from Knowledge Conflicts, where retrieved external knowledge contradicts the inherent, parametric knowledge of large language models (LLMs). It adversely affects performance on downstream tasks such as question answering (QA). Existing approaches often attempt to mitigate conflicts by directly comparing two knowledge sources in a side-by-side manner, but this can overwhelm LLMs with extraneous or lengthy contexts, ultimately hindering their ability to identify and mitigate inconsistencies. To address this issue, we propose Micro-Act a framework with a hierarchical action space that automatically perceives context complexity and adaptively decomposes each knowledge source into a sequence of fine-grained comparisons. These comparisons are represented as actionable steps, enabling reasoning beyond the superficial context. Through extensive experiments on five benchmark datasets, Micro-Act consistently achieves significant increase in QA accuracy over state-of-the-art baselines across all 5 datasets and 3 conflict types, especially in temporal and semantic types where all baselines fail significantly. More importantly, Micro-Act exhibits robust performance on non-conflict questions simultaneously, highlighting its practical value in real-world RAG applications.
Joint Transmit and Receive Beamforming for Tri-directional Coil-Based Magnetic Induction Communications
May 30, 2025In this paper, we enhance the omnidirectional coverage performance of tri-directional coil-based magnetic induction communication (TC-MIC) and reduce the pathloss with a joint transmit and receive magnetic beamforming method. An iterative optimization algorithm incorporating the transmit current vector and receive weight matrix is developed to minimize the pathloss under constant transmit power constraints. We formulate the mathematical models for the mutual inductance of tri-directional coils, receive power, and pathloss. The optimization problem is decomposed into Rayleigh quotient extremum optimization for transmit currents and Cauchy-Schwarz inequality-constrained optimization for receive weights, with an alternating iterative algorithm to approach the global optimum. Numerical results demonstrate that the proposed algorithm converges within an average of 13.6 iterations, achieving up to 54% pathloss reduction compared with equal power allocation schemes. The joint optimization approach exhibits superior angular robustness, maintaining pathloss fluctuation smaller than 2 dB, and reducing fluctuation of pathloss by approximately 45% compared with single-parameter optimization methods.
SPAR: Self-supervised Placement-Aware Representation Learning for Multi-Node IoT Systems
May 22, 2025This work develops the underpinnings of self-supervised placement-aware representation learning given spatially-distributed (multi-view and multimodal) sensor observations, motivated by the need to represent external environmental state in multi-sensor IoT systems in a manner that correctly distills spatial phenomena from the distributed multi-vantage observations. The objective of sensing in IoT systems is, in general, to collectively represent an externally observed environment given multiple vantage points from which sensory observations occur. Pretraining of models that help interpret sensor data must therefore encode the relation between signals observed by sensors and the observers' vantage points in order to attain a representation that encodes the observed spatial phenomena in a manner informed by the specific placement of the measuring instruments, while allowing arbitrary placement. The work significantly advances self-supervised model pretraining from IoT signals beyond current solutions that often overlook the distinctive spatial nature of IoT data. Our framework explicitly learns the dependencies between measurements and geometric observer layouts and structural characteristics, guided by a core design principle: the duality between signals and observer positions. We further provide theoretical analyses from the perspectives of information theory and occlusion-invariant representation learning to offer insight into the rationale behind our design. Experiments on three real-world datasets--covering vehicle monitoring, human activity recognition, and earthquake localization--demonstrate the superior generalizability and robustness of our method across diverse modalities, sensor placements, application-level inference tasks, and spatial scales.
Understanding Stragglers in Large Model Training Using What-if Analysis
May 09, 2025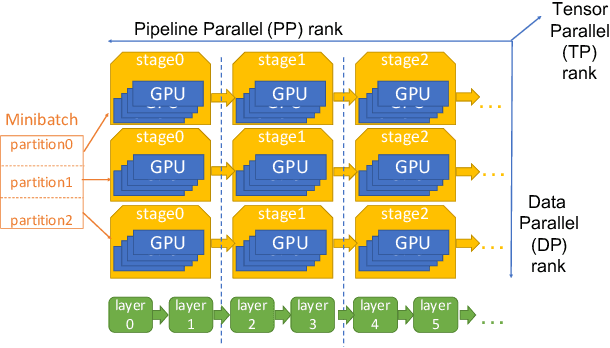

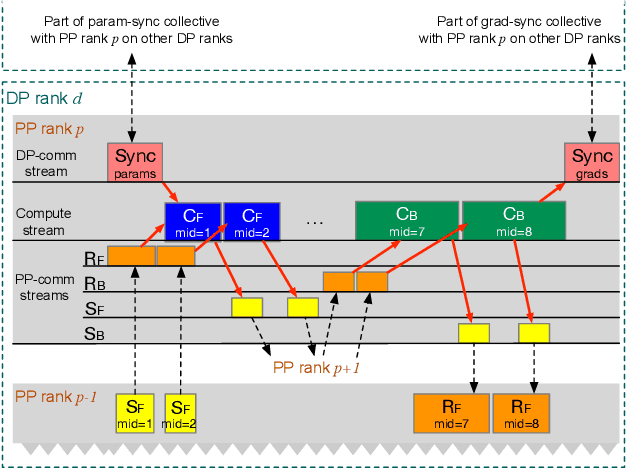
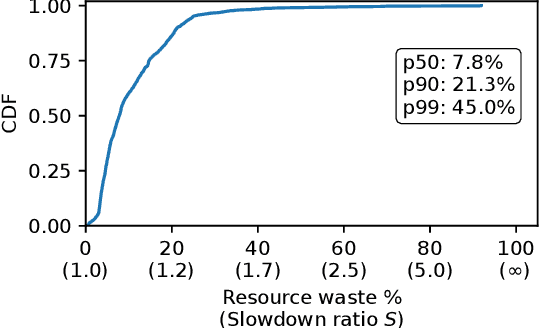
Large language model (LLM) training is one of the most demanding distributed computations today, often requiring thousands of GPUs with frequent synchronization across machines. Such a workload pattern makes it susceptible to stragglers, where the training can be stalled by few slow workers. At ByteDance we find stragglers are not trivially always caused by hardware failures, but can arise from multiple complex factors. This work aims to present a comprehensive study on the straggler issues in LLM training, using a five-month trace collected from our ByteDance LLM training cluster. The core methodology is what-if analysis that simulates the scenario without any stragglers and contrasts with the actual case. We use this method to study the following questions: (1) how often do stragglers affect training jobs, and what effect do they have on job performance; (2) do stragglers exhibit temporal or spatial patterns; and (3) what are the potential root causes for stragglers?
InfoMAE: Pair-Efficient Cross-Modal Alignment for Multimodal Time-Series Sensing Signals
Apr 13, 2025Standard multimodal self-supervised learning (SSL) algorithms regard cross-modal synchronization as implicit supervisory labels during pretraining, thus posing high requirements on the scale and quality of multimodal samples. These constraints significantly limit the performance of sensing intelligence in IoT applications, as the heterogeneity and the non-interpretability of time-series signals result in abundant unimodal data but scarce high-quality multimodal pairs. This paper proposes InfoMAE, a cross-modal alignment framework that tackles the challenge of multimodal pair efficiency under the SSL setting by facilitating efficient cross-modal alignment of pretrained unimodal representations. InfoMAE achieves \textit{efficient cross-modal alignment} with \textit{limited data pairs} through a novel information theory-inspired formulation that simultaneously addresses distribution-level and instance-level alignment. Extensive experiments on two real-world IoT applications are performed to evaluate InfoMAE's pairing efficiency to bridge pretrained unimodal models into a cohesive joint multimodal model. InfoMAE enhances downstream multimodal tasks by over 60% with significantly improved multimodal pairing efficiency. It also improves unimodal task accuracy by an average of 22%.
Reasoning Models Know When They're Right: Probing Hidden States for Self-Verification
Apr 07, 2025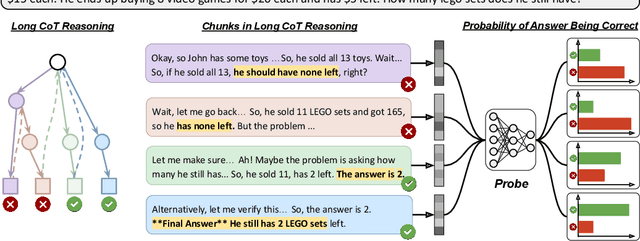
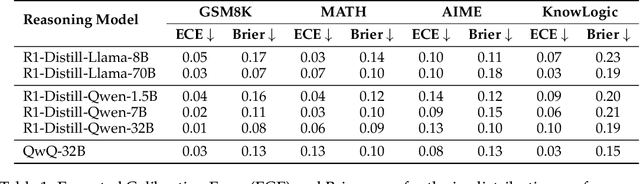
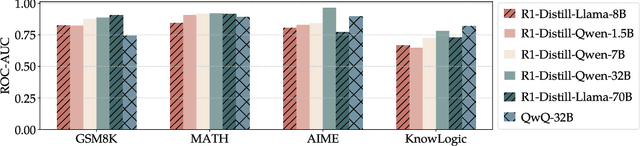
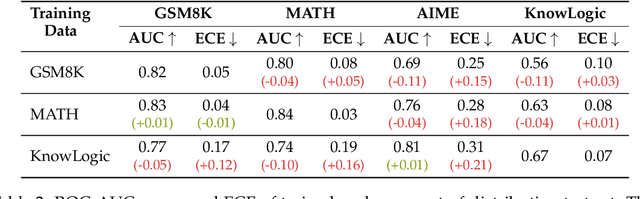
Reasoning models have achieved remarkable performance on tasks like math and logical reasoning thanks to their ability to search during reasoning. However, they still suffer from overthinking, often performing unnecessary reasoning steps even after reaching the correct answer. This raises the question: can models evaluate the correctness of their intermediate answers during reasoning? In this work, we study whether reasoning models encode information about answer correctness through probing the model's hidden states. The resulting probe can verify intermediate answers with high accuracy and produces highly calibrated scores. Additionally, we find models' hidden states encode correctness of future answers, enabling early prediction of the correctness before the intermediate answer is fully formulated. We then use the probe as a verifier to decide whether to exit reasoning at intermediate answers during inference, reducing the number of inference tokens by 24\% without compromising performance. These findings confirm that reasoning models do encode a notion of correctness yet fail to exploit it, revealing substantial untapped potential to enhance their efficiency.
DDPT: Diffusion-Driven Prompt Tuning for Large Language Model Code Generation
Apr 06, 2025Large Language Models (LLMs) have demonstrated remarkable capabilities in code generation. However, the quality of the generated code is heavily dependent on the structure and composition of the prompts used. Crafting high-quality prompts is a challenging task that requires significant knowledge and skills of prompt engineering. To advance the automation support for the prompt engineering for LLM-based code generation, we propose a novel solution Diffusion-Driven Prompt Tuning (DDPT) that learns how to generate optimal prompt embedding from Gaussian Noise to automate the prompt engineering for code generation. We evaluate the feasibility of diffusion-based optimization and abstract the optimal prompt embedding as a directional vector toward the optimal embedding. We use the code generation loss given by the LLMs to help the diffusion model capture the distribution of optimal prompt embedding during training. The trained diffusion model can build a path from the noise distribution to the optimal distribution at the sampling phrase, the evaluation result demonstrates that DDPT helps improve the prompt optimization for code generation.