 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPAR: Self-supervised Placement-Aware Representation Learning for Multi-Node IoT Systems
May 22, 2025This work develops the underpinnings of self-supervised placement-aware representation learning given spatially-distributed (multi-view and multimodal) sensor observations, motivated by the need to represent external environmental state in multi-sensor IoT systems in a manner that correctly distills spatial phenomena from the distributed multi-vantage observations. The objective of sensing in IoT systems is, in general, to collectively represent an externally observed environment given multiple vantage points from which sensory observations occur. Pretraining of models that help interpret sensor data must therefore encode the relation between signals observed by sensors and the observers' vantage points in order to attain a representation that encodes the observed spatial phenomena in a manner informed by the specific placement of the measuring instruments, while allowing arbitrary placement. The work significantly advances self-supervised model pretraining from IoT signals beyond current solutions that often overlook the distinctive spatial nature of IoT data. Our framework explicitly learns the dependencies between measurements and geometric observer layouts and structural characteristics, guided by a core design principle: the duality between signals and observer positions. We further provide theoretical analyses from the perspectives of information theory and occlusion-invariant representation learning to offer insight into the rationale behind our design. Experiments on three real-world datasets--covering vehicle monitoring, human activity recognition, and earthquake localization--demonstrate the superior generalizability and robustness of our method across diverse modalities, sensor placements, application-level inference tasks, and spatial scales.
InfoMAE: Pair-Efficient Cross-Modal Alignment for Multimodal Time-Series Sensing Signals
Apr 13, 2025Standard multimodal self-supervised learning (SSL) algorithms regard cross-modal synchronization as implicit supervisory labels during pretraining, thus posing high requirements on the scale and quality of multimodal samples. These constraints significantly limit the performance of sensing intelligence in IoT applications, as the heterogeneity and the non-interpretability of time-series signals result in abundant unimodal data but scarce high-quality multimodal pairs. This paper proposes InfoMAE, a cross-modal alignment framework that tackles the challenge of multimodal pair efficiency under the SSL setting by facilitating efficient cross-modal alignment of pretrained unimodal representations. InfoMAE achieves \textit{efficient cross-modal alignment} with \textit{limited data pairs} through a novel information theory-inspired formulation that simultaneously addresses distribution-level and instance-level alignment. Extensive experiments on two real-world IoT applications are performed to evaluate InfoMAE's pairing efficiency to bridge pretrained unimodal models into a cohesive joint multimodal model. InfoMAE enhances downstream multimodal tasks by over 60% with significantly improved multimodal pairing efficiency. It also improves unimodal task accuracy by an average of 22%.
On the Efficiency and Robustness of Vibration-based Foundation Models for IoT Sensing: A Case Study
Apr 03, 2024



This paper demonstrates the potential of vibration-based Foundation Models (FMs), pre-trained with unlabeled sensing data, to improve the robustness of run-time inference in (a class of) IoT applications. A case study is presented featuring a vehicle classification application using acoustic and seismic sensing. The work is motivated by the success of foundation models in the areas of natural language processing and computer vision, leading to generalizations of the FM concept to other domains as well, where significant amounts of unlabeled data exist that can be used for self-supervised pre-training. One such domain is IoT applications. Foundation models for selected sensing modalities in the IoT domain can be pre-trained in an environment-agnostic fashion using available unlabeled sensor data and then fine-tuned to the deployment at hand using a small amount of labeled data. The paper shows that the pre-training/fine-tuning approach improves the robustness of downstream inference and facilitates adaptation to different environmental conditions. More specifically, we present a case study in a real-world setting to evaluate a simple (vibration-based) FM-like model, called FOCAL, demonstrating its superior robustness and adaptation, compared to conventional supervised deep neural networks (DNNs). We also demonstrate its superior convergence over supervised solutions. Our findings highlight the advantages of vibration-based FMs (and FM-inspired selfsupervised models in general) in terms of inference robustness, runtime efficiency, and model adaptation (via fine-tuning) in resource-limited IoT settings.
SudokuSens: Enhancing Deep Learning Robustness for IoT Sensing Applications using a Generative Approach
Feb 08, 2024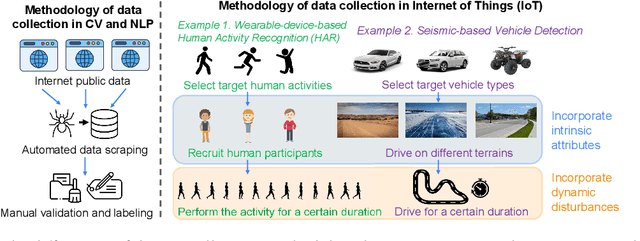
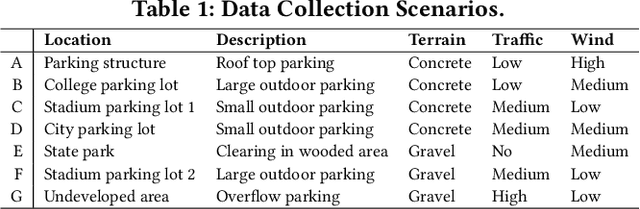
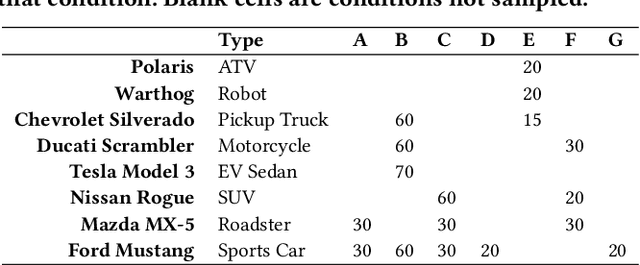
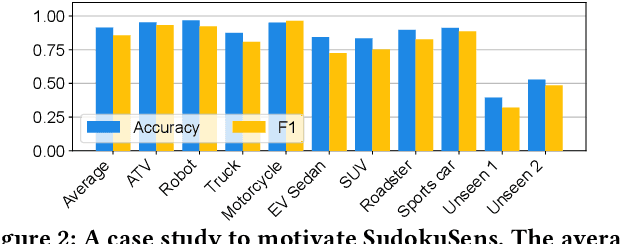
This paper introduces SudokuSens, a generative framework for automated generation of training data in machine-learning-based Internet-of-Things (IoT) applications, such that the generated synthetic data mimic experimental configurations not encountered during actual sensor data collection. The framework improves the robustness of resulting deep learning models, and is intended for IoT applications where data collection is expensive. The work is motivated by the fact that IoT time-series data entangle the signatures of observed objects with the confounding intrinsic properties of the surrounding environment and the dynamic environmental disturbances experienced. To incorporate sufficient diversity into the IoT training data, one therefore needs to consider a combinatorial explosion of training cases that are multiplicative in the number of objects considered and the possible environmental conditions in which such objects may be encountered. Our framework substantially reduces these multiplicative training needs. To decouple object signatures from environmental conditions, we employ a Conditional Variational Autoencoder (CVAE) that allows us to reduce data collection needs from multiplicative to (nearly) linear, while synthetically generating (data for) the missing conditions. To obtain robustness with respect to dynamic disturbances, a session-aware temporal contrastive learning approach is taken. Integrating the aforementioned two approaches, SudokuSens significantly improves the robustness of deep learning for IoT applications. We explore the degree to which SudokuSens benefits downstream inference tasks in different data sets and discuss conditions under which the approach is particularly effective.