 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHadaCore: Tensor Core Accelerated Hadamard Transform Kernel
Dec 12, 2024We present HadaCore, a modified Fast Walsh-Hadamard Transform (FWHT) algorithm optimized for the Tensor Cores present in modern GPU hardware. HadaCore follows the recursive structure of the original FWHT algorithm, achieving the same asymptotic runtime complexity but leveraging a hardware-aware work decomposition that benefits from Tensor Core acceleration. This reduces bottlenecks from compute and data exchange. On Nvidia A100 and H100 GPUs, HadaCore achieves speedups of 1.1-1.4x and 1.0-1.3x, with a peak gain of 3.5x and 3.6x respectively, when compared to the existing state-of-the-art implementation of the original algorithm. We also show that when using FP16 or BF16, our implementation is numerically accurate, enabling comparable accuracy on MMLU benchmarks when used in an end-to-end Llama3 inference run with quantized (FP8) attention.
Transforming the Hybrid Cloud for Emerging AI Workloads
Nov 20, 2024



This white paper, developed through close collaboration between IBM Research and UIUC researchers within the IIDAI Institute, envisions transforming hybrid cloud systems to meet the growing complexity of AI workloads through innovative, full-stack co-design approaches, emphasizing usability, manageability, affordability, adaptability, efficiency, and scalability. By integrating cutting-edge technologies such as generative and agentic AI, cross-layer automation and optimization, unified control plane, and composable and adaptive system architecture, the proposed framework addresses critical challenges in energy efficiency, performance, and cost-effectiveness. Incorporating quantum computing as it matures will enable quantum-accelerated simulations for materials science, climate modeling, and other high-impact domains. Collaborative efforts between academia and industry are central to this vision, driving advancements in foundation models for material design and climate solutions, scalable multimodal data processing, and enhanced physics-based AI emulators for applications like weather forecasting and carbon sequestration. Research priorities include advancing AI agentic systems, LLM as an Abstraction (LLMaaA), AI model optimization and unified abstractions across heterogeneous infrastructure, end-to-end edge-cloud transformation, efficient programming model, middleware and platform, secure infrastructure, application-adaptive cloud systems, and new quantum-classical collaborative workflows. These ideas and solutions encompass both theoretical and practical research questions, requiring coordinated input and support from the research community. This joint initiative aims to establish hybrid clouds as secure, efficient, and sustainable platforms, fostering breakthroughs in AI-driven applications and scientific discovery across academia, industry, and society.
CaloChallenge 2022: A Community Challenge for Fast Calorimeter Simulation
Oct 28, 2024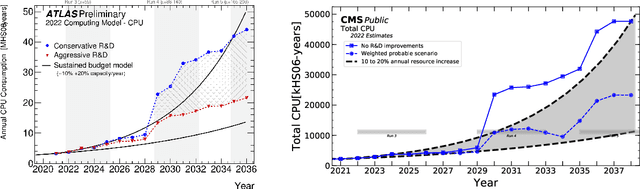
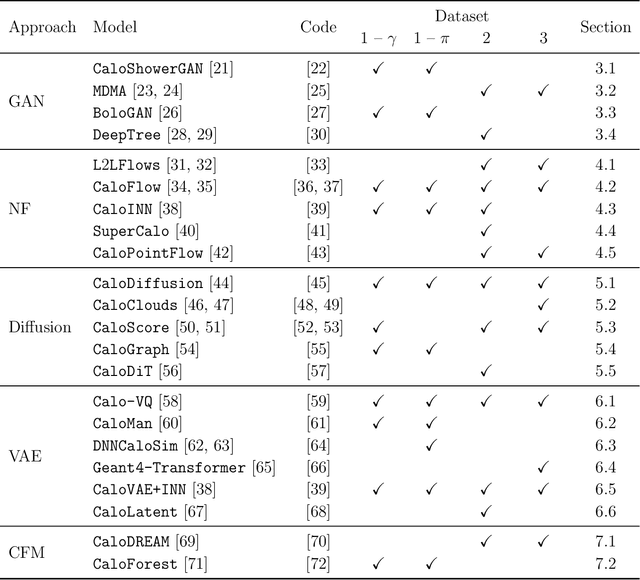
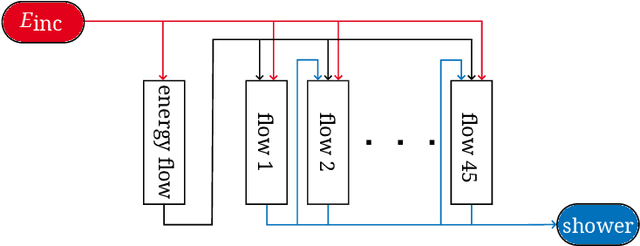
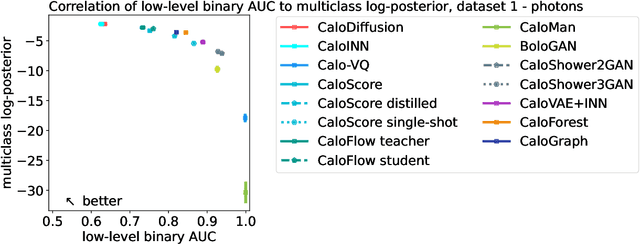
We present the results of the "Fast Calorimeter Simulation Challenge 2022" - the CaloChallenge. We study state-of-the-art generative models on four calorimeter shower datasets of increasing dimensionality, ranging from a few hundred voxels to a few tens of thousand voxels. The 31 individual submissions span a wide range of current popular generative architectures, including Variational AutoEncoders (VAEs), Generative Adversarial Networks (GANs), Normalizing Flows, Diffusion models, and models based on Conditional Flow Matching. We compare all submissions in terms of quality of generated calorimeter showers, as well as shower generation time and model size. To assess the quality we use a broad range of different metrics including differences in 1-dimensional histograms of observables, KPD/FPD scores, AUCs of binary classifiers, and the log-posterior of a multiclass classifier. The results of the CaloChallenge provide the most complete and comprehensive survey of cutting-edge approaches to calorimeter fast simulation to date. In addition, our work provides a uniquely detailed perspective on the important problem of how to evaluate generative models. As such, the results presented here should be applicable for other domains that use generative AI and require fast and faithful generation of samples in a large phase space.
Accelerating Production LLMs with Combined Token/Embedding Speculators
Apr 29, 2024This technical report describes the design and training of novel speculative decoding draft models, for accelerating the inference speeds of large language models in a production environment. By conditioning draft predictions on both context vectors and sampled tokens, we can train our speculators to efficiently predict high-quality n-grams, which the base model then accepts or rejects. This allows us to effectively predict multiple tokens per inference forward pass, accelerating wall-clock inference speeds of highly optimized base model implementations by a factor of 2-3x. We explore these initial results and describe next steps for further improvements.
SudokuSens: Enhancing Deep Learning Robustness for IoT Sensing Applications using a Generative Approach
Feb 08, 2024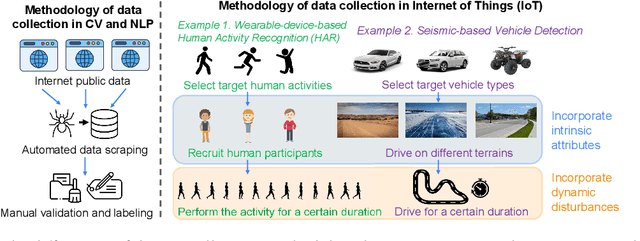
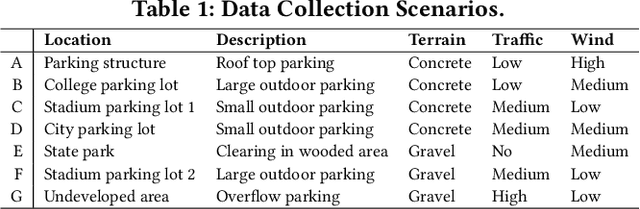
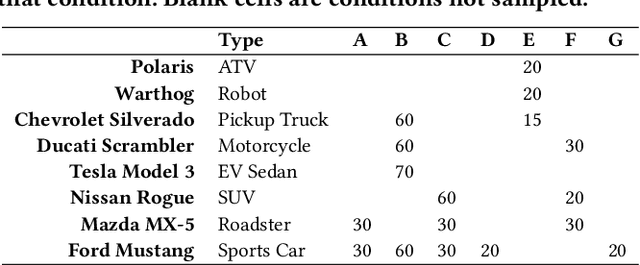
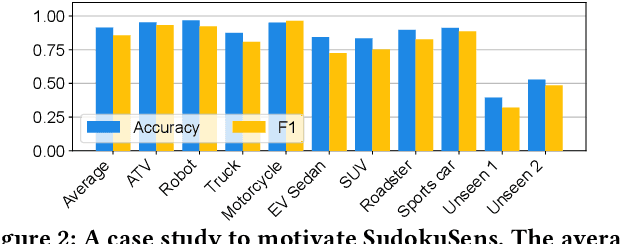
This paper introduces SudokuSens, a generative framework for automated generation of training data in machine-learning-based Internet-of-Things (IoT) applications, such that the generated synthetic data mimic experimental configurations not encountered during actual sensor data collection. The framework improves the robustness of resulting deep learning models, and is intended for IoT applications where data collection is expensive. The work is motivated by the fact that IoT time-series data entangle the signatures of observed objects with the confounding intrinsic properties of the surrounding environment and the dynamic environmental disturbances experienced. To incorporate sufficient diversity into the IoT training data, one therefore needs to consider a combinatorial explosion of training cases that are multiplicative in the number of objects considered and the possible environmental conditions in which such objects may be encountered. Our framework substantially reduces these multiplicative training needs. To decouple object signatures from environmental conditions, we employ a Conditional Variational Autoencoder (CVAE) that allows us to reduce data collection needs from multiplicative to (nearly) linear, while synthetically generating (data for) the missing conditions. To obtain robustness with respect to dynamic disturbances, a session-aware temporal contrastive learning approach is taken. Integrating the aforementioned two approaches, SudokuSens significantly improves the robustness of deep learning for IoT applications. We explore the degree to which SudokuSens benefits downstream inference tasks in different data sets and discuss conditions under which the approach is particularly effective.
State Action Separable Reinforcement Learning
Jun 05, 2020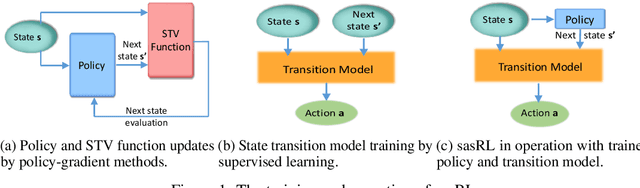
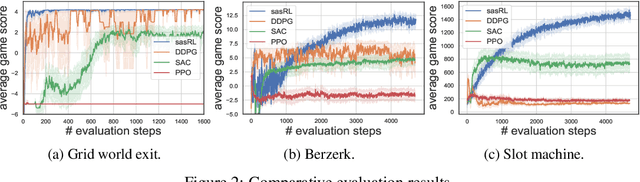
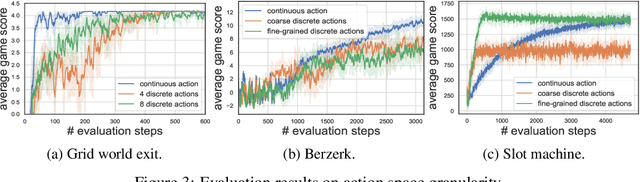
Reinforcement Learning (RL) based methods have seen their paramount successes in solving serial decision-making and control problems in recent years. For conventional RL formulations, Markov Decision Process (MDP) and state-action-value function are the basis for the problem modeling and policy evaluation. However, several challenging issues still remain. Among most cited issues, the enormity of state/action space is an important factor that causes inefficiency in accurately approximating the state-action-value function. We observe that although actions directly define the agents' behaviors, for many problems the next state after a state transition matters more than the action taken, in determining the return of such a state transition. In this regard, we propose a new learning paradigm, State Action Separable Reinforcement Learning (sasRL), wherein the action space is decoupled from the value function learning process for higher efficiency. Then, a light-weight transition model is learned to assist the agent to determine the action that triggers the associated state transition. In addition, our convergence analysis reveals that under certain conditions, the convergence time of sasRL is $O(T^{1/k})$, where $T$ is the convergence time for updating the value function in the MDP-based formulation and $k$ is a weighting factor. Experiments on several gaming scenarios show that sasRL outperforms state-of-the-art MDP-based RL algorithms by up to $75\%$.
Neural Network Tomography
Jan 09, 2020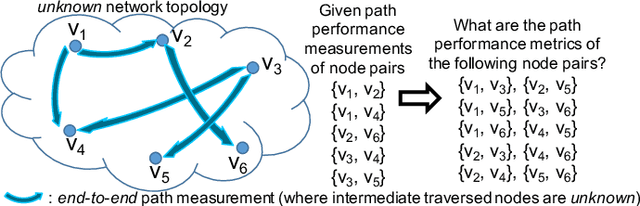
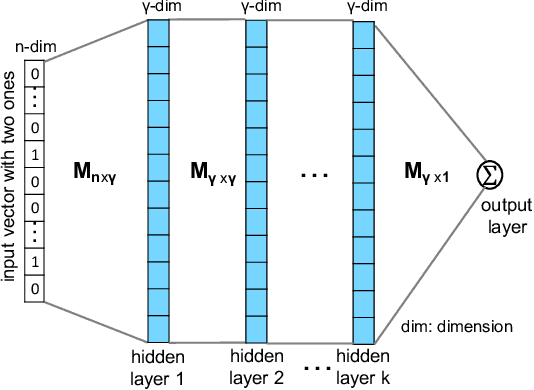
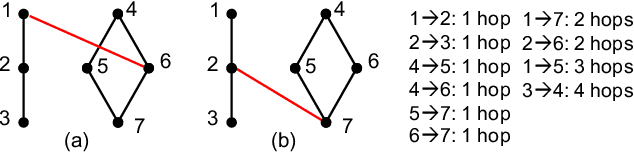
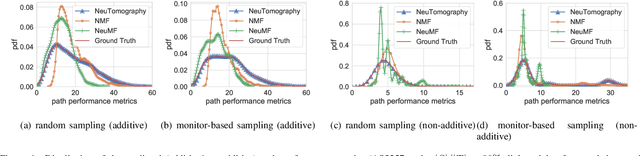
Network tomography, a classic research problem in the realm of network monitoring, refers to the methodology of inferring unmeasured network attributes using selected end-to-end path measurements. In the research community, network tomography is generally investigated under the assumptions of known network topology, correlated path measurements, bounded number of faulty nodes/links, or even special network protocol support. The applicability of network tomography is considerably constrained by these strong assumptions, which therefore frequently position it in the theoretical world. In this regard, we revisit network tomography from the practical perspective by establishing a generic framework that does not rely on any of these assumptions or the types of performance metrics. Given only the end-to-end path performance metrics of sampled node pairs, the proposed framework, NeuTomography, utilizes deep neural network and data augmentation to predict the unmeasured performance metrics via learning non-linear relationships between node pairs and underlying unknown topological/routing properties. In addition, NeuTomography can be employed to reconstruct the original network topology, which is critical to most network planning tasks. Extensive experiments using real network data show that comparing to baseline solutions, NeuTomography can predict network characteristics and reconstruct network topologies with significantly higher accuracy and robustness using only limited measurement data.
SENSE: Semantically Enhanced Node Sequence Embedding
Nov 07, 2019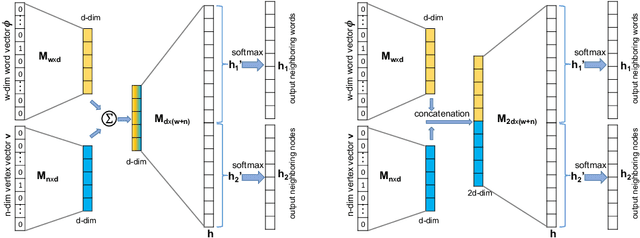
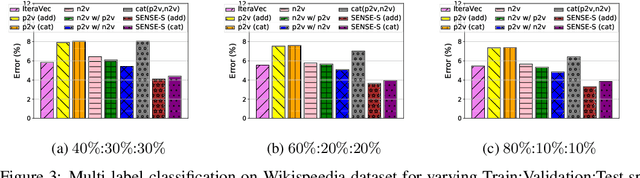
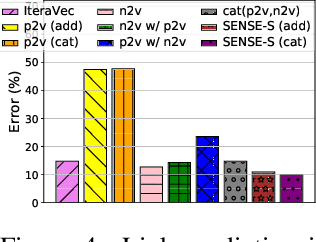
Effectively capturing graph node sequences in the form of vector embeddings is critical to many applications. We achieve this by (i) first learning vector embeddings of single graph nodes and (ii) then composing them to compactly represent node sequences. Specifically, we propose SENSE-S (Semantically Enhanced Node Sequence Embedding - for Single nodes), a skip-gram based novel embedding mechanism, for single graph nodes that co-learns graph structure as well as their textual descriptions. We demonstrate that SENSE-S vectors increase the accuracy of multi-label classification tasks by up to 50% and link-prediction tasks by up to 78% under a variety of scenarios using real datasets. Based on SENSE-S, we next propose generic SENSE to compute composite vectors that represent a sequence of nodes, where preserving the node order is important. We prove that this approach is efficient in embedding node sequences, and our experiments on real data confirm its high accuracy in node order decoding.
neuralRank: Searching and ranking ANN-based model repositories
Mar 02, 2019
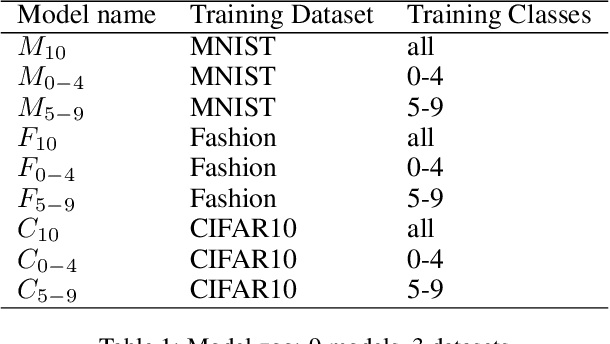
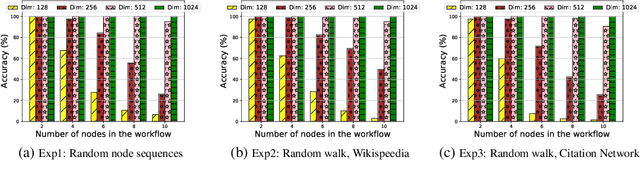
Widespread applications of deep learning have led to a plethora of pre-trained neural network models for common tasks. Such models are often adapted from other models via transfer learning. The models may have varying training sets, training algorithms, network architectures, and hyper-parameters. For a given application, what isthe most suitable model in a model repository? This is a critical question for practical deployments but it has not received much attention. This paper introduces the novel problem of searching and ranking models based on suitability relative to a target dataset and proposes a ranking algorithm called \textit{neuralRank}. The key idea behind this algorithm is to base model suitability on the discriminating power of a model, using a novel metric to measure it. With experimental results on the MNIST, Fashion, and CIFAR10 datasets, we demonstrate that (1) neuralRank is independent of the domain, the training set, or the network architecture and (2) that the models ranked highly by neuralRank ranking tend to have higher model accuracy in practice.
Actor Conditioned Attention Maps for Video Action Detection
Dec 30, 2018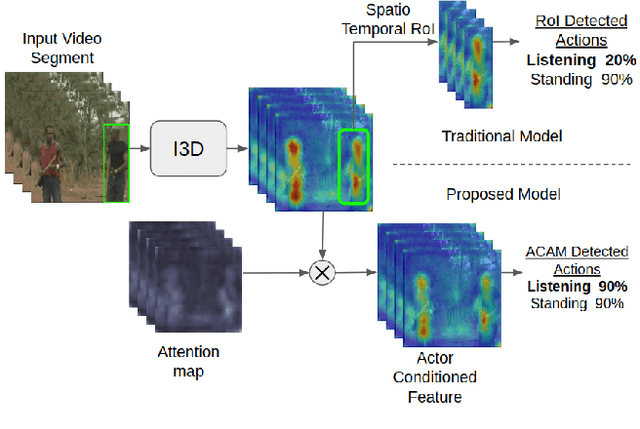
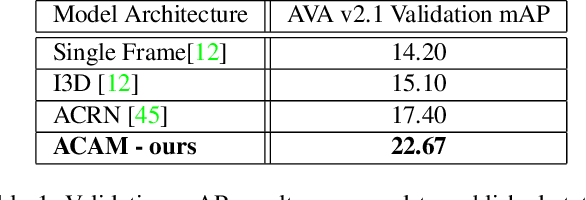

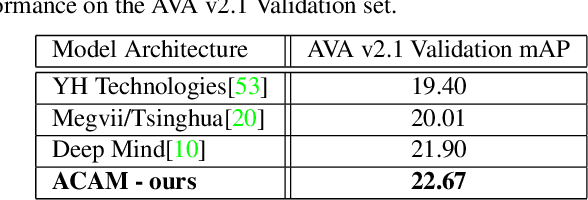
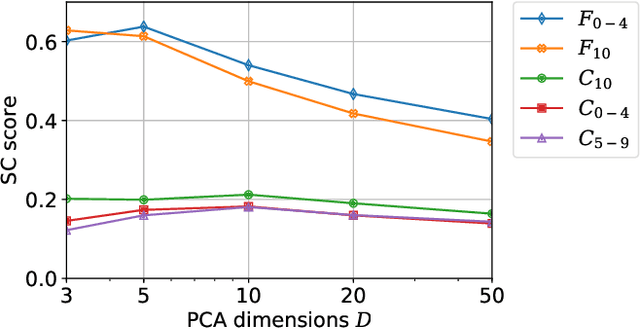
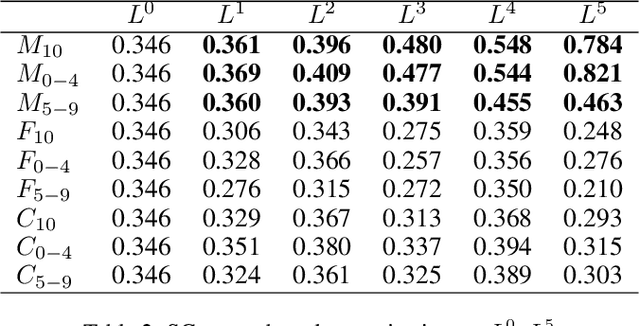
Interactions with surrounding objects and people contain important information towards understanding human actions. In order to model such interactions explicitly, we propose to generate attention maps that rank each spatio-temporal region's importance to a detected actor. We refer to these as Actor-Conditioned Attention Maps (ACAM), and these maps serve as weights to the features extracted from the whole scene. These resulting actor-conditioned features help focus the learned model on regions that are important/relevant to the conditioned actor. Another novelty of our approach is in the use of pre-trained object detectors, instead of region proposals, that generalize better to videos from different sources. Detailed experimental results on the AVA 2.1 datasets demonstrate the importance of interactions, with a performance improvement of 5 mAP with respect to state of the art published results.