 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCaloChallenge 2022: A Community Challenge for Fast Calorimeter Simulation
Oct 28, 2024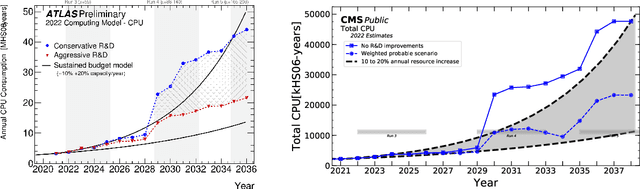
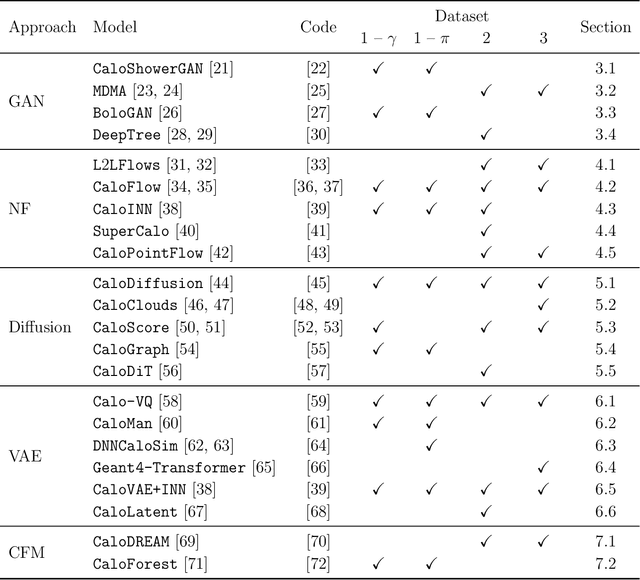
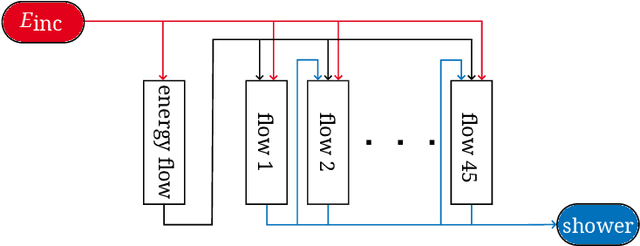
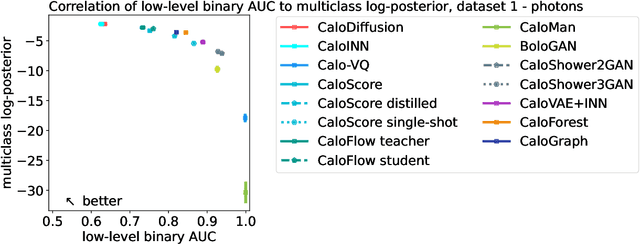
We present the results of the "Fast Calorimeter Simulation Challenge 2022" - the CaloChallenge. We study state-of-the-art generative models on four calorimeter shower datasets of increasing dimensionality, ranging from a few hundred voxels to a few tens of thousand voxels. The 31 individual submissions span a wide range of current popular generative architectures, including Variational AutoEncoders (VAEs), Generative Adversarial Networks (GANs), Normalizing Flows, Diffusion models, and models based on Conditional Flow Matching. We compare all submissions in terms of quality of generated calorimeter showers, as well as shower generation time and model size. To assess the quality we use a broad range of different metrics including differences in 1-dimensional histograms of observables, KPD/FPD scores, AUCs of binary classifiers, and the log-posterior of a multiclass classifier. The results of the CaloChallenge provide the most complete and comprehensive survey of cutting-edge approaches to calorimeter fast simulation to date. In addition, our work provides a uniquely detailed perspective on the important problem of how to evaluate generative models. As such, the results presented here should be applicable for other domains that use generative AI and require fast and faithful generation of samples in a large phase space.
Supervised machine learning techniques for data matching based on similarity metrics
Jul 08, 2020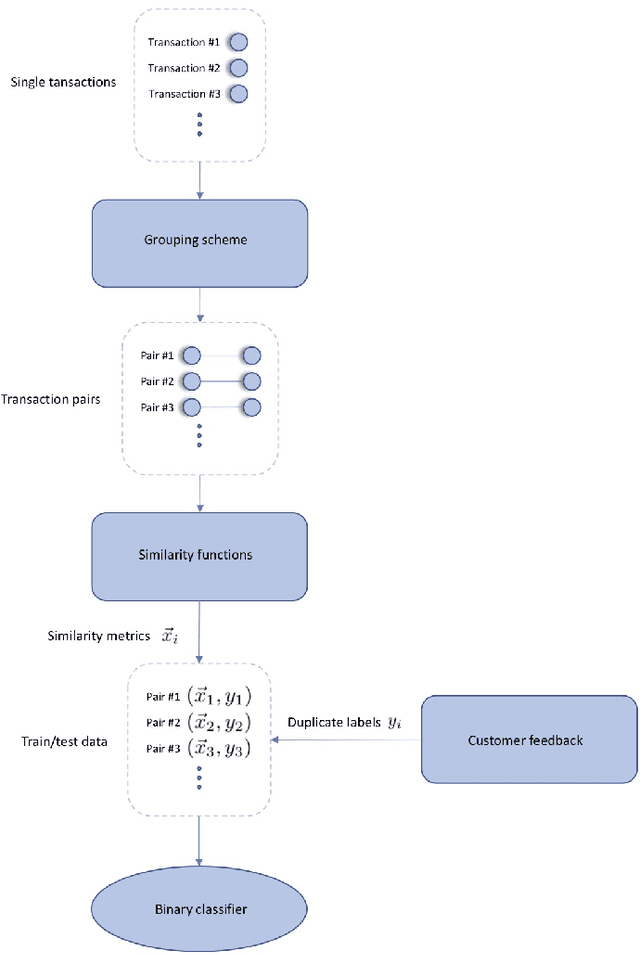


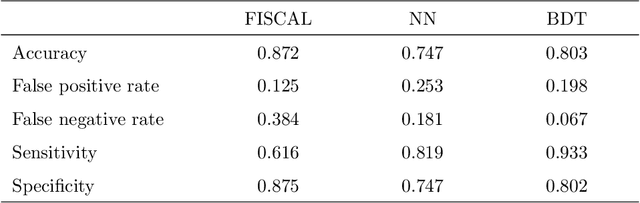
Businesses, governmental bodies and NGO's have an ever-increasing amount of data at their disposal from which they try to extract valuable information. Often, this needs to be done not only accurately but also within a short time frame. Clean and consistent data is therefore crucial. Data matching is the field that tries to identify instances in data that refer to the same real-world entity. In this study, machine learning techniques are combined with string similarity functions to the field of data matching. A dataset of invoices from a variety of businesses and organizations was preprocessed with a grouping scheme to reduce pair dimensionality and a set of similarity functions was used to quantify similarity between invoice pairs. The resulting invoice pair dataset was then used to train and validate a neural network and a boosted decision tree. The performance was compared with a solution from FISCAL Technologies as a benchmark against currently available deduplication solutions. Both the neural network and boosted decision tree showed equal to better performance.