 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Driven High-Dimensional Statistical Inference with Generative Models
Jun 06, 2025Crucial to many measurements at the LHC is the use of correlated multi-dimensional information to distinguish rare processes from large backgrounds, which is complicated by the poor modeling of many of the crucial backgrounds in Monte Carlo simulations. In this work, we introduce HI-SIGMA, a method to perform unbinned high-dimensional statistical inference with data-driven background distributions. In contradistinction to many applications of Simulation Based Inference in High Energy Physics, HI-SIGMA relies on generative ML models, rather than classifiers, to learn the signal and background distributions in the high-dimensional space. These ML models allow for efficient, interpretable inference while also incorporating model errors and other sources of systematic uncertainties. We showcase this methodology on a simplified version of a di-Higgs measurement in the $bb\gamma\gamma$ final state, where the di-photon resonance allows for efficient background interpolation from sidebands into the signal region. We demonstrate that HI-SIGMA provides improved sensitivity as compared to standard classifier-based methods, and that systematic uncertainties can be straightforwardly incorporated by extending methods which have been used for histogram based analyses.
Aspen Open Jets: Unlocking LHC Data for Foundation Models in Particle Physics
Dec 13, 2024Foundation models are deep learning models pre-trained on large amounts of data which are capable of generalizing to multiple datasets and/or downstream tasks. This work demonstrates how data collected by the CMS experiment at the Large Hadron Collider can be useful in pre-training foundation models for HEP. Specifically, we introduce the AspenOpenJets dataset, consisting of approximately 180M high $p_T$ jets derived from CMS 2016 Open Data. We show how pre-training the OmniJet-$\alpha$ foundation model on AspenOpenJets improves performance on generative tasks with significant domain shift: generating boosted top and QCD jets from the simulated JetClass dataset. In addition to demonstrating the power of pre-training of a jet-based foundation model on actual proton-proton collision data, we provide the ML-ready derived AspenOpenJets dataset for further public use.
CaloChallenge 2022: A Community Challenge for Fast Calorimeter Simulation
Oct 28, 2024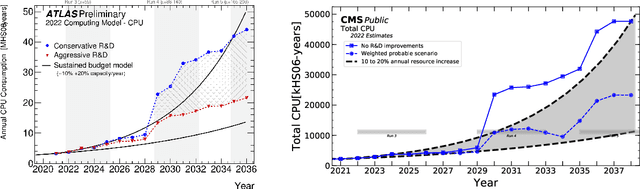
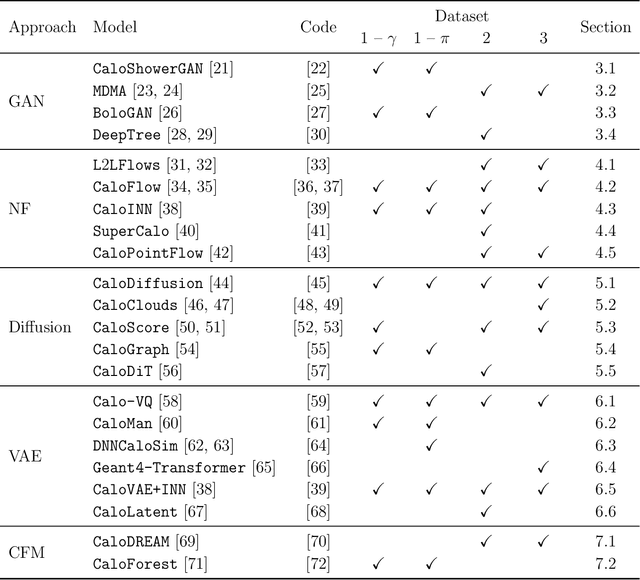
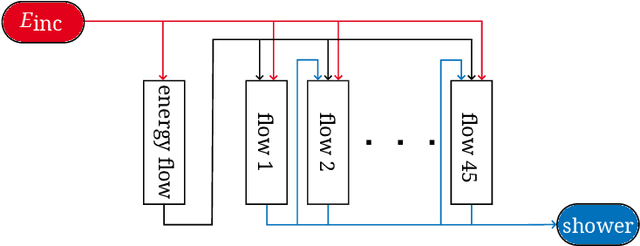
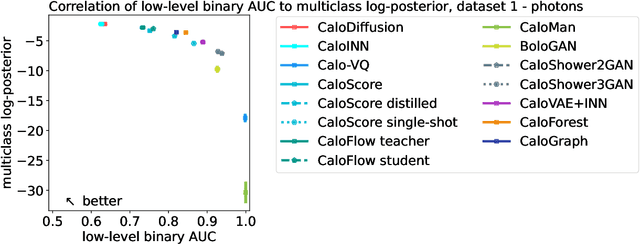
We present the results of the "Fast Calorimeter Simulation Challenge 2022" - the CaloChallenge. We study state-of-the-art generative models on four calorimeter shower datasets of increasing dimensionality, ranging from a few hundred voxels to a few tens of thousand voxels. The 31 individual submissions span a wide range of current popular generative architectures, including Variational AutoEncoders (VAEs), Generative Adversarial Networks (GANs), Normalizing Flows, Diffusion models, and models based on Conditional Flow Matching. We compare all submissions in terms of quality of generated calorimeter showers, as well as shower generation time and model size. To assess the quality we use a broad range of different metrics including differences in 1-dimensional histograms of observables, KPD/FPD scores, AUCs of binary classifiers, and the log-posterior of a multiclass classifier. The results of the CaloChallenge provide the most complete and comprehensive survey of cutting-edge approaches to calorimeter fast simulation to date. In addition, our work provides a uniquely detailed perspective on the important problem of how to evaluate generative models. As such, the results presented here should be applicable for other domains that use generative AI and require fast and faithful generation of samples in a large phase space.