 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Driven High-Dimensional Statistical Inference with Generative Models
Jun 06, 2025Crucial to many measurements at the LHC is the use of correlated multi-dimensional information to distinguish rare processes from large backgrounds, which is complicated by the poor modeling of many of the crucial backgrounds in Monte Carlo simulations. In this work, we introduce HI-SIGMA, a method to perform unbinned high-dimensional statistical inference with data-driven background distributions. In contradistinction to many applications of Simulation Based Inference in High Energy Physics, HI-SIGMA relies on generative ML models, rather than classifiers, to learn the signal and background distributions in the high-dimensional space. These ML models allow for efficient, interpretable inference while also incorporating model errors and other sources of systematic uncertainties. We showcase this methodology on a simplified version of a di-Higgs measurement in the $bb\gamma\gamma$ final state, where the di-photon resonance allows for efficient background interpolation from sidebands into the signal region. We demonstrate that HI-SIGMA provides improved sensitivity as compared to standard classifier-based methods, and that systematic uncertainties can be straightforwardly incorporated by extending methods which have been used for histogram based analyses.
Improvement and generalization of ABCD method with Bayesian inference
Feb 12, 2024To find New Physics or to refine our knowledge of the Standard Model at the LHC is an enterprise that involves many factors. We focus on taking advantage of available information and pour our effort in re-thinking the usual data-driven ABCD method to improve it and to generalize it using Bayesian Machine Learning tools. We propose that a dataset consisting of a signal and many backgrounds is well described through a mixture model. Signal, backgrounds and their relative fractions in the sample can be well extracted by exploiting the prior knowledge and the dependence between the different observables at the event-by-event level with Bayesian tools. We show how, in contrast to the ABCD method, one can take advantage of understanding some properties of the different backgrounds and of having more than two independent observables to measure in each event. In addition, instead of regions defined through hard cuts, the Bayesian framework uses the information of continuous distribution to obtain soft-assignments of the events which are statistically more robust. To compare both methods we use a toy problem inspired by $pp\to hh\to b\bar b b \bar b$, selecting a reduced and simplified number of processes and analysing the flavor of the four jets and the invariant mass of the jet-pairs, modeled with simplified distributions. Taking advantage of all this information, and starting from a combination of biased and agnostic priors, leads us to a very good posterior once we use the Bayesian framework to exploit the data and the mutual information of the observables at the event-by-event level. We show how, in this simplified model, the Bayesian framework outperforms the ABCD method sensitivity in obtaining the signal fraction in scenarios with $1\%$ and $0.5\%$ true signal fractions in the dataset. We also show that the method is robust against the absence of signal.
Null Hypothesis Test for Anomaly Detection
Oct 11, 2022
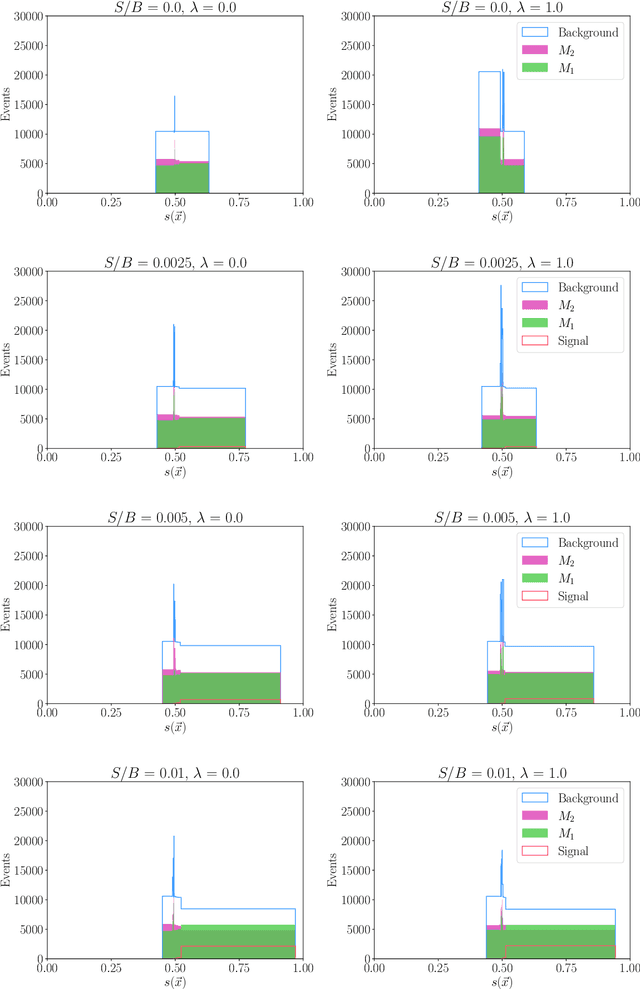
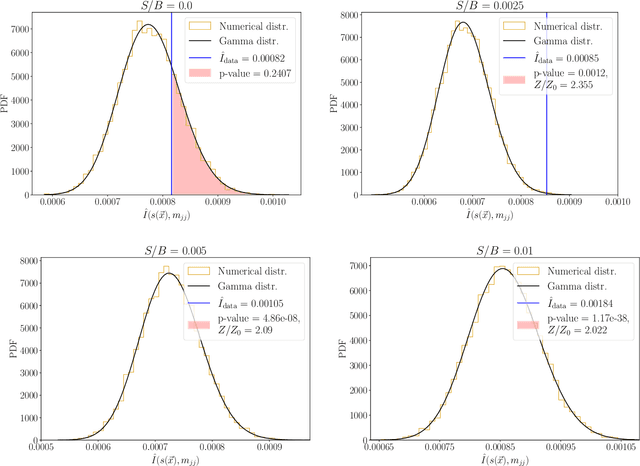
We extend the use of Classification Without Labels for anomaly detection with a hypothesis test designed to exclude the background-only hypothesis. By testing for statistical independence of the two discriminating dataset regions, we are able exclude the background-only hypothesis without relying on fixed anomaly score cuts or extrapolations of background estimates between regions. The method relies on the assumption of conditional independence of anomaly score features and dataset regions, which can be ensured using existing decorrelation techniques. As a benchmark example, we consider the LHC Olympics dataset where we show that mutual information represents a suitable test for statistical independence and our method exhibits excellent and robust performance at different signal fractions even in presence of realistic feature correlations.
A Machine Learning alternative to placebo-controlled clinical trials upon new diseases: A primer
Mar 26, 2020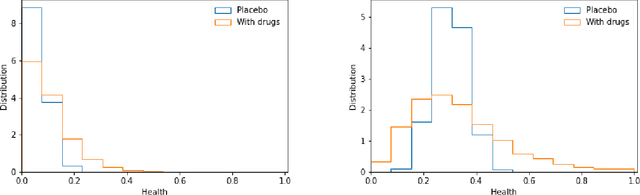
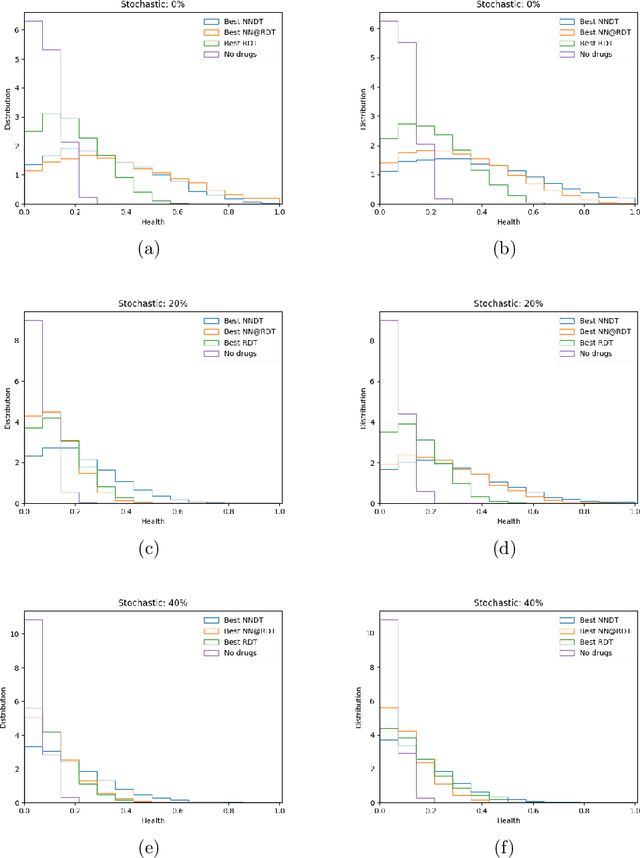
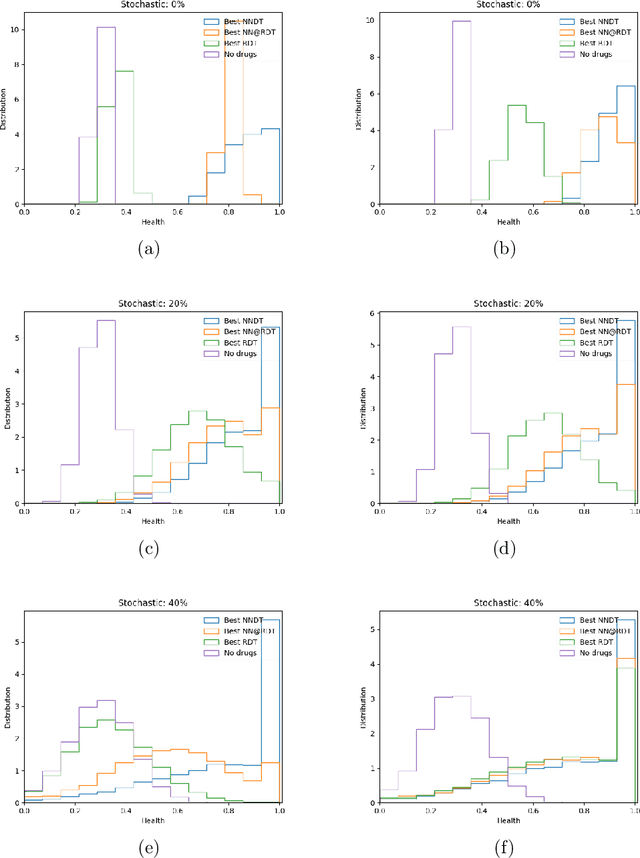
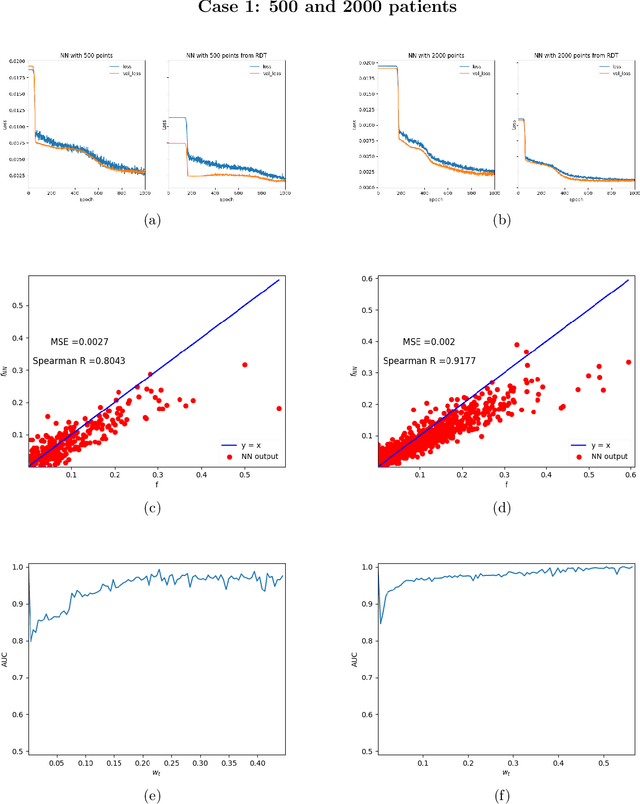
The appearance of a new dangerous and contagious disease requires the development of a drug therapy faster than what is foreseen by usual mechanisms. Many drug therapy developments consist in investigating through different clinical trials the effects of different specific drug combinations by delivering it into a test group of ill patients, meanwhile a placebo treatment is delivered to the remaining ill patients, known as the control group. We compare the above technique to a new technique in which all patients receive a different and reasonable combination of drugs and use this outcome to feed a Neural Network. By averaging out fluctuations and recognizing different patient features, the Neural Network learns the pattern that connects the patients initial state to the outcome of the treatments and therefore can predict the best drug therapy better than the above method. In contrast to many available works, we do not study any detail of drugs composition nor interaction, but instead pose and solve the problem from a phenomenological point of view, which allows us to compare both methods. Although the conclusion is reached through mathematical modeling and is stable upon any reasonable model, this is a proof-of-concept that should be studied within other expertises before confronting a real scenario. All calculations, tools and scripts have been made open source for the community to test, modify or expand it. Finally it should be mentioned that, although the results presented here are in the context of a new disease in medical sciences, these are useful for any field that requires a experimental technique with a control group.
Intelligent Arxiv: Sort daily papers by learning users topics preference
Feb 06, 2020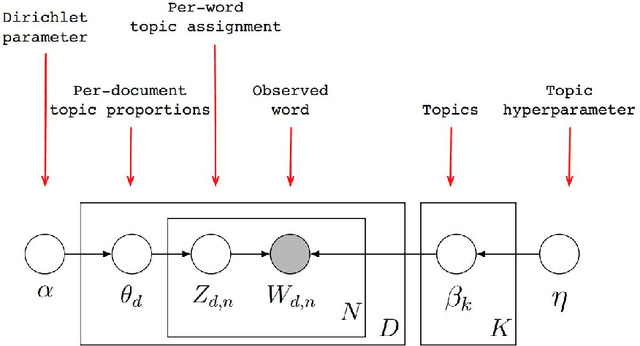
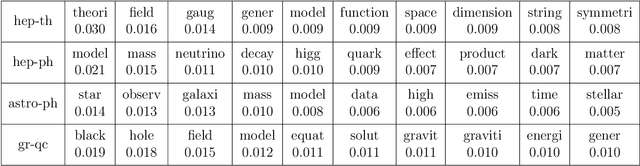
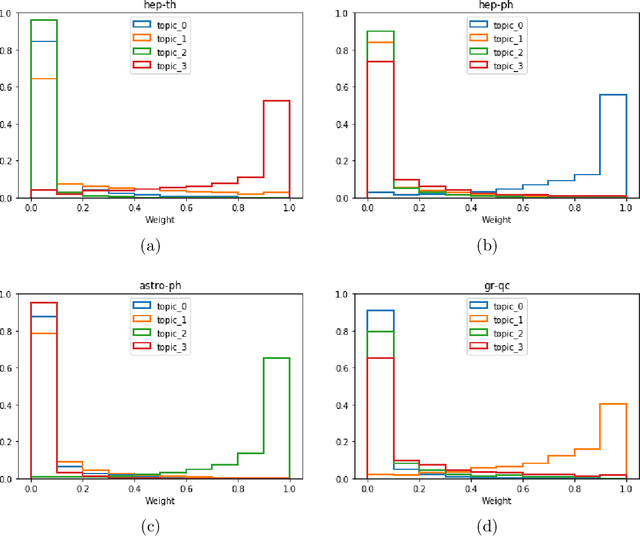
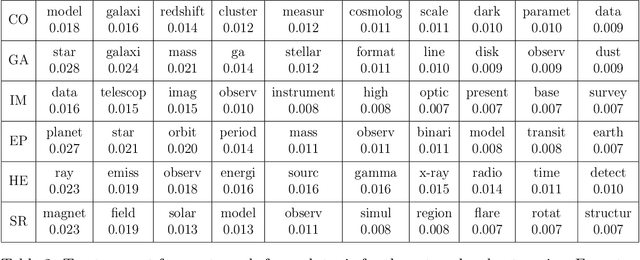
Current daily paper releases are becoming increasingly large and areas of research are growing in diversity. This makes it harder for scientists to keep up to date with current state of the art and identify relevant work within their lines of interest. The goal of this article is to address this problem using Machine Learning techniques. We model a scientific paper to be built as a combination of different scientific knowledge from diverse topics into a new problem. In light of this, we implement the unsupervised Machine Learning technique of Latent Dirichlet Allocation (LDA) on the corpus of papers in a given field to: i) define and extract underlying topics in the corpus; ii) get the topics weight vector for each paper in the corpus; and iii) get the topics weight vector for new papers. By registering papers preferred by a user, we build a user vector of weights using the information of the vectors of the selected papers. Hence, by performing an inner product between the user vector and each paper in the daily Arxiv release, we can sort the papers according to the user preference on the underlying topics. We have created the website IArxiv.org where users can read sorted daily Arxiv releases (and more) while the algorithm learns each users preference, yielding a more accurate sorting every day. Current IArxiv.org version runs on Arxiv categories astro-ph, gr-qc, hep-ph and hep-th and we plan to extend to others. We propose several new useful and relevant implementations to be additionally developed as well as new Machine Learning techniques beyond LDA to further improve the accuracy of this new tool.