 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImprovement and generalization of ABCD method with Bayesian inference
Feb 12, 2024To find New Physics or to refine our knowledge of the Standard Model at the LHC is an enterprise that involves many factors. We focus on taking advantage of available information and pour our effort in re-thinking the usual data-driven ABCD method to improve it and to generalize it using Bayesian Machine Learning tools. We propose that a dataset consisting of a signal and many backgrounds is well described through a mixture model. Signal, backgrounds and their relative fractions in the sample can be well extracted by exploiting the prior knowledge and the dependence between the different observables at the event-by-event level with Bayesian tools. We show how, in contrast to the ABCD method, one can take advantage of understanding some properties of the different backgrounds and of having more than two independent observables to measure in each event. In addition, instead of regions defined through hard cuts, the Bayesian framework uses the information of continuous distribution to obtain soft-assignments of the events which are statistically more robust. To compare both methods we use a toy problem inspired by $pp\to hh\to b\bar b b \bar b$, selecting a reduced and simplified number of processes and analysing the flavor of the four jets and the invariant mass of the jet-pairs, modeled with simplified distributions. Taking advantage of all this information, and starting from a combination of biased and agnostic priors, leads us to a very good posterior once we use the Bayesian framework to exploit the data and the mutual information of the observables at the event-by-event level. We show how, in this simplified model, the Bayesian framework outperforms the ABCD method sensitivity in obtaining the signal fraction in scenarios with $1\%$ and $0.5\%$ true signal fractions in the dataset. We also show that the method is robust against the absence of signal.
Towards a method to anticipate dark matter signals with deep learning at the LHC
May 25, 2021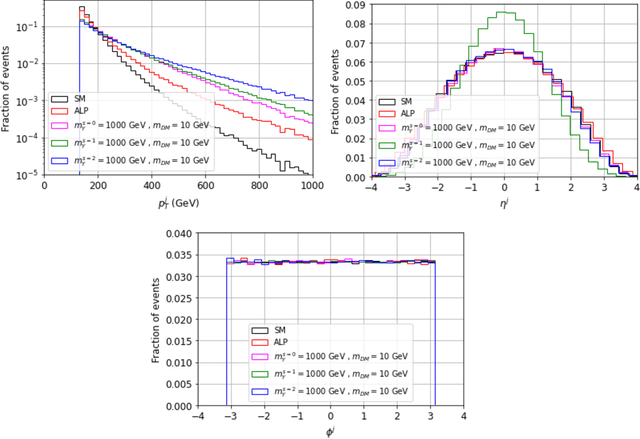
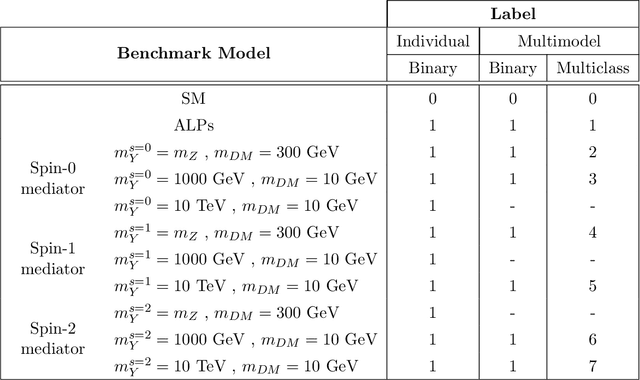
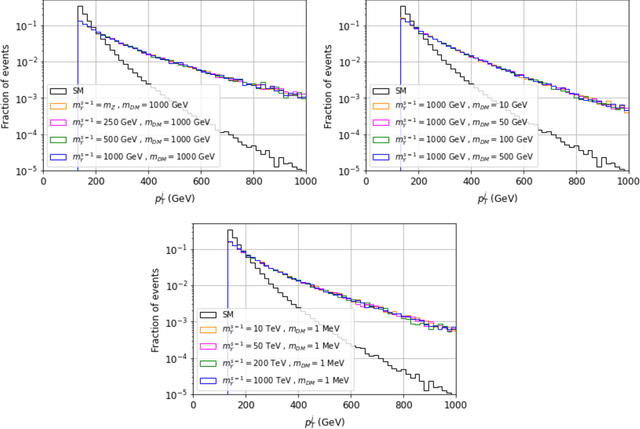
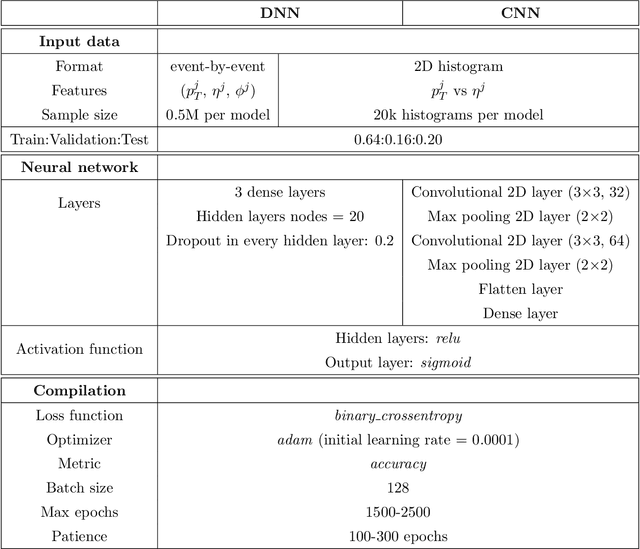
We study several simplified dark matter (DM) models and their signatures at the LHC using neural networks. We focus on the usual monojet plus missing transverse energy channel, but to train the algorithms we organize the data in 2D histograms instead of event-by-event arrays. This results in a large performance boost to distinguish between standard model (SM) only and SM plus new physics signals. We use the kinematic monojet features as input data which allow us to describe families of models with a single data sample. We found that the neural network performance does not depend on the simulated number of background events if they are presented as a function of $S/\sqrt{B}$, where $S$ and $B$ are the number of signal and background events per histogram, respectively. This provides flexibility to the method, since testing a particular model in that case only requires knowing the new physics monojet cross section. Furthermore, we also discuss the network performance under incorrect assumptions about the true DM nature. Finally, we propose multimodel classifiers to search and identify new signals in a more general way, for the next LHC run.