 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Machine Learning alternative to placebo-controlled clinical trials upon new diseases: A primer
Mar 26, 2020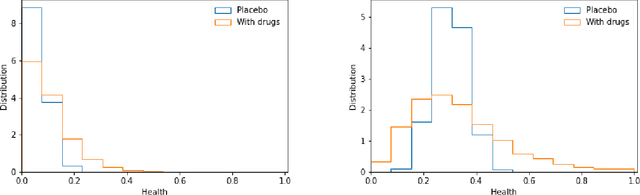
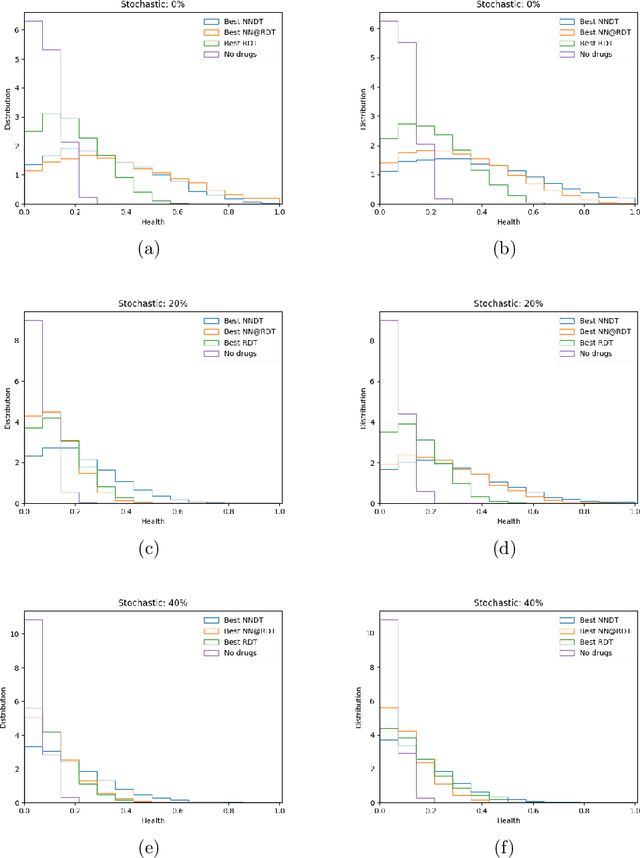
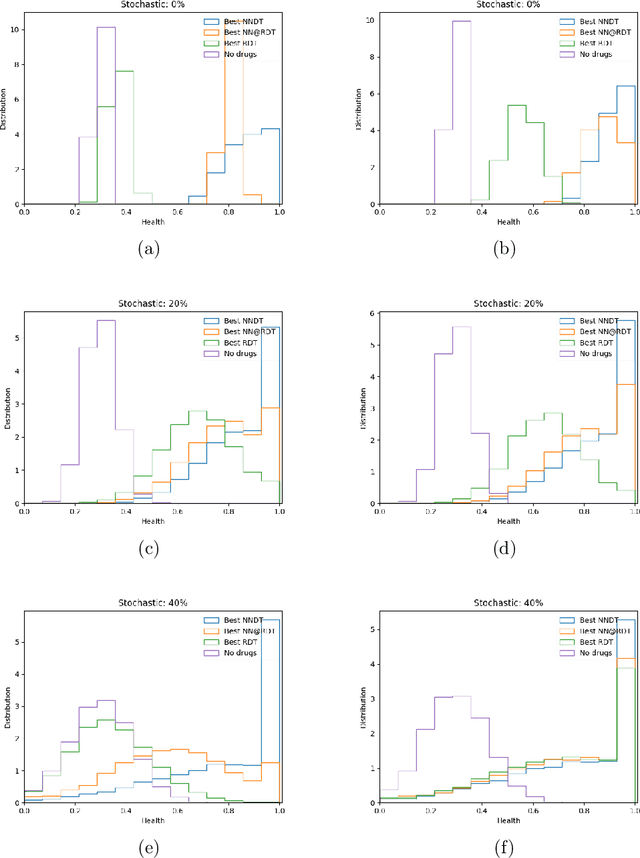
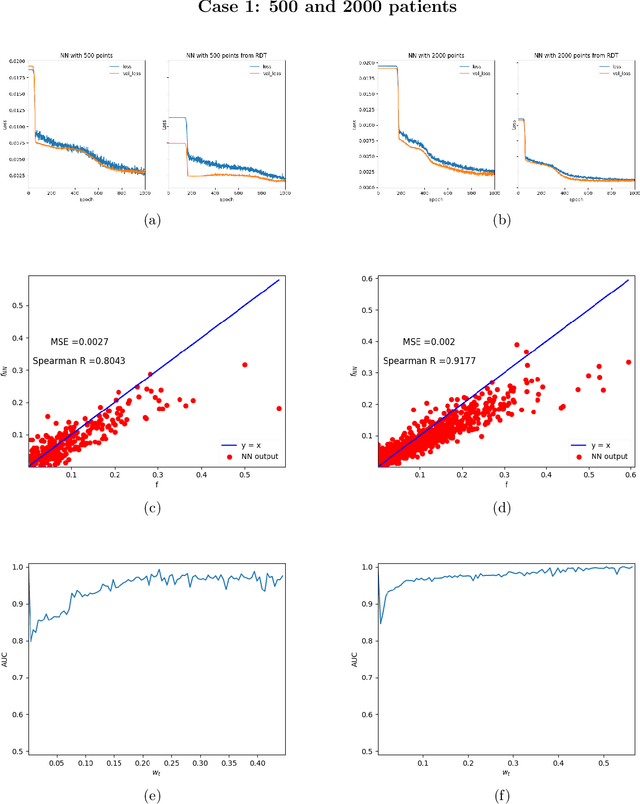
The appearance of a new dangerous and contagious disease requires the development of a drug therapy faster than what is foreseen by usual mechanisms. Many drug therapy developments consist in investigating through different clinical trials the effects of different specific drug combinations by delivering it into a test group of ill patients, meanwhile a placebo treatment is delivered to the remaining ill patients, known as the control group. We compare the above technique to a new technique in which all patients receive a different and reasonable combination of drugs and use this outcome to feed a Neural Network. By averaging out fluctuations and recognizing different patient features, the Neural Network learns the pattern that connects the patients initial state to the outcome of the treatments and therefore can predict the best drug therapy better than the above method. In contrast to many available works, we do not study any detail of drugs composition nor interaction, but instead pose and solve the problem from a phenomenological point of view, which allows us to compare both methods. Although the conclusion is reached through mathematical modeling and is stable upon any reasonable model, this is a proof-of-concept that should be studied within other expertises before confronting a real scenario. All calculations, tools and scripts have been made open source for the community to test, modify or expand it. Finally it should be mentioned that, although the results presented here are in the context of a new disease in medical sciences, these are useful for any field that requires a experimental technique with a control group.
Intelligent Arxiv: Sort daily papers by learning users topics preference
Feb 06, 2020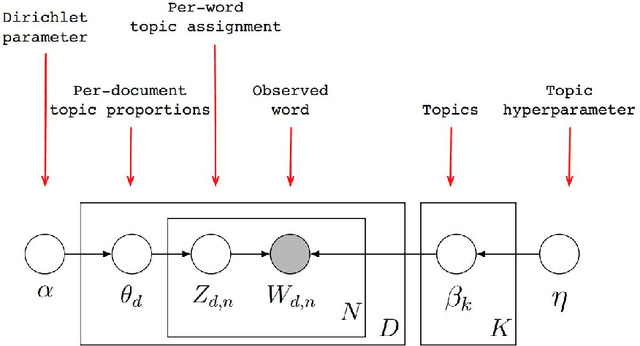
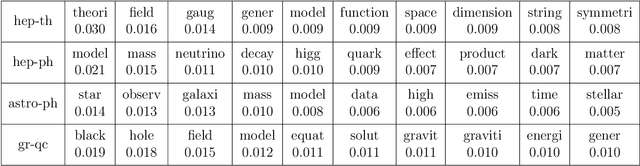
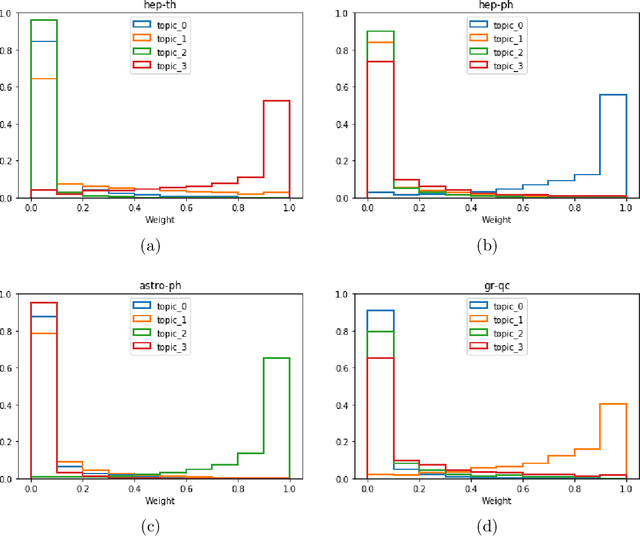
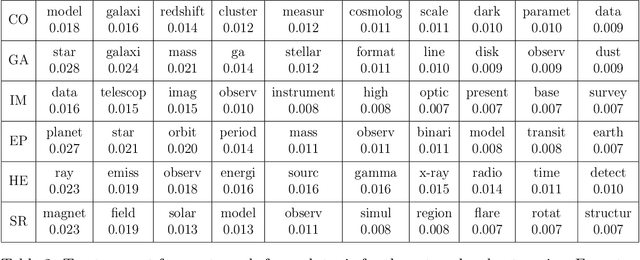
Current daily paper releases are becoming increasingly large and areas of research are growing in diversity. This makes it harder for scientists to keep up to date with current state of the art and identify relevant work within their lines of interest. The goal of this article is to address this problem using Machine Learning techniques. We model a scientific paper to be built as a combination of different scientific knowledge from diverse topics into a new problem. In light of this, we implement the unsupervised Machine Learning technique of Latent Dirichlet Allocation (LDA) on the corpus of papers in a given field to: i) define and extract underlying topics in the corpus; ii) get the topics weight vector for each paper in the corpus; and iii) get the topics weight vector for new papers. By registering papers preferred by a user, we build a user vector of weights using the information of the vectors of the selected papers. Hence, by performing an inner product between the user vector and each paper in the daily Arxiv release, we can sort the papers according to the user preference on the underlying topics. We have created the website IArxiv.org where users can read sorted daily Arxiv releases (and more) while the algorithm learns each users preference, yielding a more accurate sorting every day. Current IArxiv.org version runs on Arxiv categories astro-ph, gr-qc, hep-ph and hep-th and we plan to extend to others. We propose several new useful and relevant implementations to be additionally developed as well as new Machine Learning techniques beyond LDA to further improve the accuracy of this new tool.