 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to pick the best anomaly detector?
Nov 18, 2025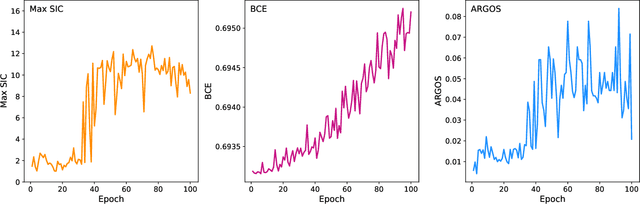
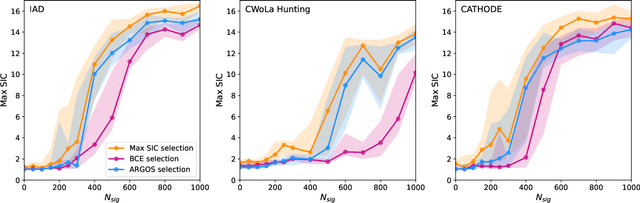
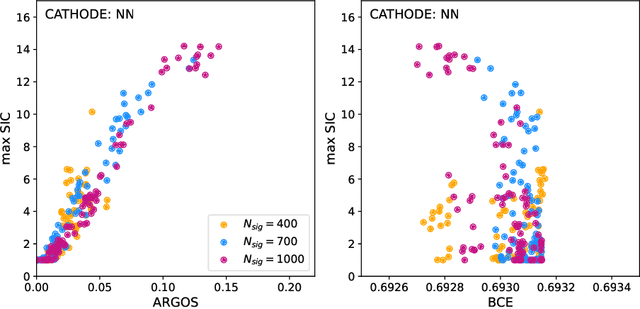
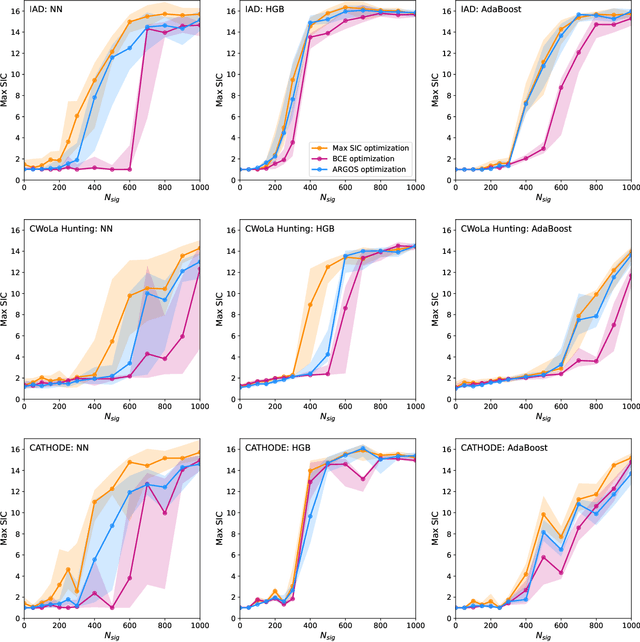
Anomaly detection has the potential to discover new physics in unexplored regions of the data. However, choosing the best anomaly detector for a given data set in a model-agnostic way is an important challenge which has hitherto largely been neglected. In this paper, we introduce the data-driven ARGOS metric, which has a sound theoretical foundation and is empirically shown to robustly select the most sensitive anomaly detection model given the data. Focusing on weakly-supervised, classifier-based anomaly detection methods, we show that the ARGOS metric outperforms other model selection metrics previously used in the literature, in particular the binary cross-entropy loss. We explore several realistic applications, including hyperparameter tuning as well as architecture and feature selection, and in all cases we demonstrate that ARGOS is robust to the noisy conditions of anomaly detection.
Aspen Open Jets: Unlocking LHC Data for Foundation Models in Particle Physics
Dec 13, 2024Foundation models are deep learning models pre-trained on large amounts of data which are capable of generalizing to multiple datasets and/or downstream tasks. This work demonstrates how data collected by the CMS experiment at the Large Hadron Collider can be useful in pre-training foundation models for HEP. Specifically, we introduce the AspenOpenJets dataset, consisting of approximately 180M high $p_T$ jets derived from CMS 2016 Open Data. We show how pre-training the OmniJet-$\alpha$ foundation model on AspenOpenJets improves performance on generative tasks with significant domain shift: generating boosted top and QCD jets from the simulated JetClass dataset. In addition to demonstrating the power of pre-training of a jet-based foundation model on actual proton-proton collision data, we provide the ML-ready derived AspenOpenJets dataset for further public use.
CaloChallenge 2022: A Community Challenge for Fast Calorimeter Simulation
Oct 28, 2024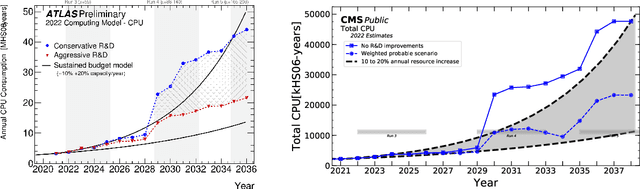
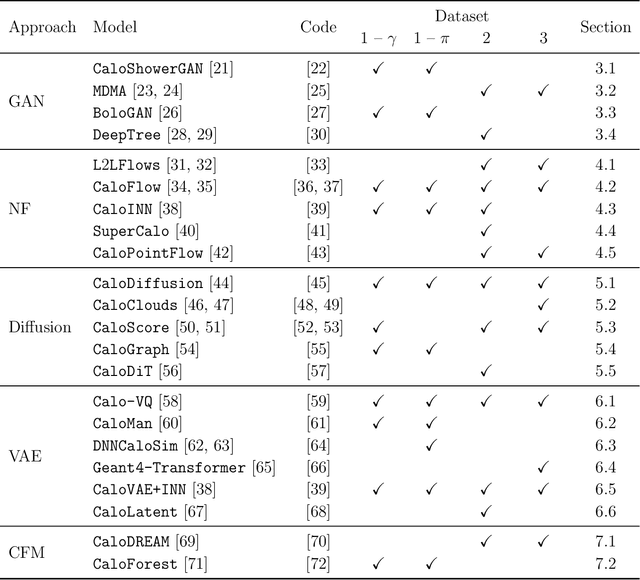
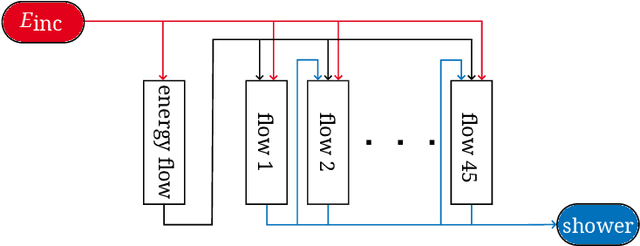
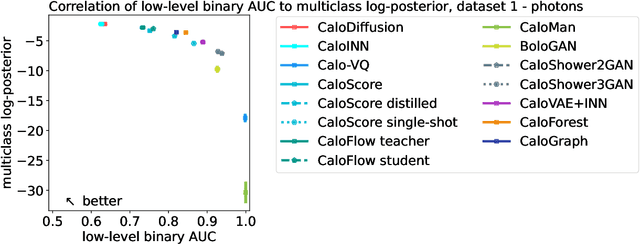
We present the results of the "Fast Calorimeter Simulation Challenge 2022" - the CaloChallenge. We study state-of-the-art generative models on four calorimeter shower datasets of increasing dimensionality, ranging from a few hundred voxels to a few tens of thousand voxels. The 31 individual submissions span a wide range of current popular generative architectures, including Variational AutoEncoders (VAEs), Generative Adversarial Networks (GANs), Normalizing Flows, Diffusion models, and models based on Conditional Flow Matching. We compare all submissions in terms of quality of generated calorimeter showers, as well as shower generation time and model size. To assess the quality we use a broad range of different metrics including differences in 1-dimensional histograms of observables, KPD/FPD scores, AUCs of binary classifiers, and the log-posterior of a multiclass classifier. The results of the CaloChallenge provide the most complete and comprehensive survey of cutting-edge approaches to calorimeter fast simulation to date. In addition, our work provides a uniquely detailed perspective on the important problem of how to evaluate generative models. As such, the results presented here should be applicable for other domains that use generative AI and require fast and faithful generation of samples in a large phase space.
SIGMA: Single Interpolated Generative Model for Anomalies
Oct 27, 2024A key step in any resonant anomaly detection search is accurate modeling of the background distribution in each signal region. Data-driven methods like CATHODE accomplish this by training separate generative models on the complement of each signal region, and interpolating them into their corresponding signal regions. Having to re-train the generative model on essentially the entire dataset for each signal region is a major computational cost in a typical sliding window search with many signal regions. Here, we present SIGMA, a new, fully data-driven, computationally-efficient method for estimating background distributions. The idea is to train a single generative model on all of the data and interpolate its parameters in sideband regions in order to obtain a model for the background in the signal region. The SIGMA method significantly reduces the computational cost compared to previous approaches, while retaining a similar high quality of background modeling and sensitivity to anomalous signals.
Universal New Physics Latent Space
Jul 29, 2024We develop a machine learning method for mapping data originating from both Standard Model processes and various theories beyond the Standard Model into a unified representation (latent) space while conserving information about the relationship between the underlying theories. We apply our method to three examples of new physics at the LHC of increasing complexity, showing that models can be clustered according to their LHC phenomenology: different models are mapped to distinct regions in latent space, while indistinguishable models are mapped to the same region. This opens interesting new avenues on several fronts, such as model discrimination, selection of representative benchmark scenarios, and identifying gaps in the coverage of model space.
Convolutional L2LFlows: Generating Accurate Showers in Highly Granular Calorimeters Using Convolutional Normalizing Flows
Jun 03, 2024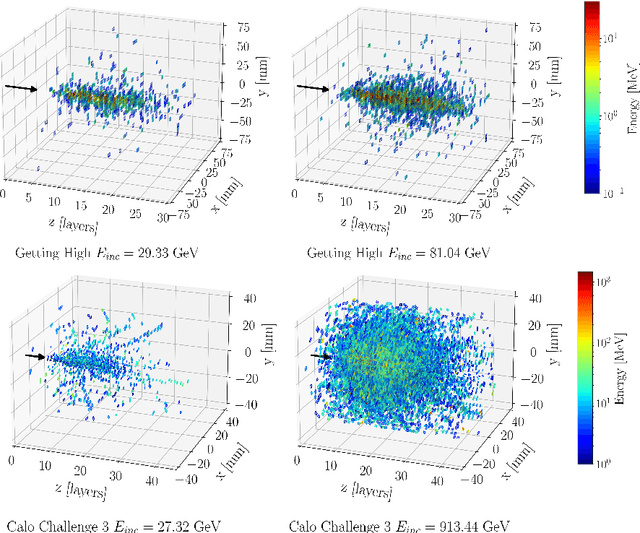
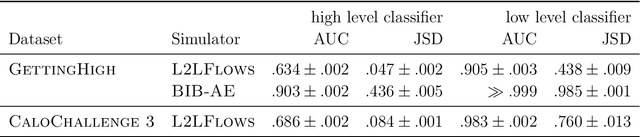
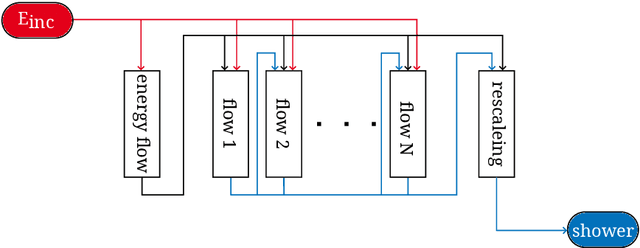
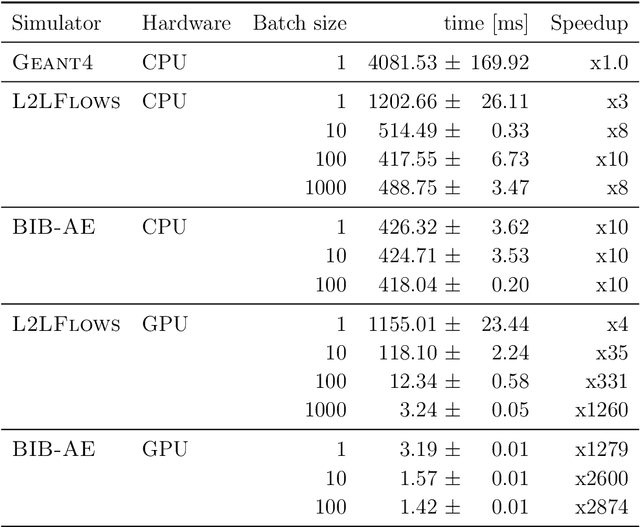
In the quest to build generative surrogate models as computationally efficient alternatives to rule-based simulations, the quality of the generated samples remains a crucial frontier. So far, normalizing flows have been among the models with the best fidelity. However, as the latent space in such models is required to have the same dimensionality as the data space, scaling up normalizing flows to high dimensional datasets is not straightforward. The prior L2LFlows approach successfully used a series of separate normalizing flows and sequence of conditioning steps to circumvent this problem. In this work, we extend L2LFlows to simulate showers with a 9-times larger profile in the lateral direction. To achieve this, we introduce convolutional layers and U-Net-type connections, move from masked autoregressive flows to coupling layers, and demonstrate the successful modelling of showers in the ILD Electromagnetic Calorimeter as well as Dataset 3 from the public CaloChallenge dataset.
Unifying Simulation and Inference with Normalizing Flows
Apr 29, 2024



There have been many applications of deep neural networks to detector calibrations and a growing number of studies that propose deep generative models as automated fast detector simulators. We show that these two tasks can be unified by using maximum likelihood estimation (MLE) from conditional generative models for energy regression. Unlike direct regression techniques, the MLE approach is prior-independent and non-Gaussian resolutions can be determined from the shape of the likelihood near the maximum. Using an ATLAS-like calorimeter simulation, we demonstrate this concept in the context of calorimeter energy calibration.
Residual ANODE
Dec 18, 2023We present R-ANODE, a new method for data-driven, model-agnostic resonant anomaly detection that raises the bar for both performance and interpretability. The key to R-ANODE is to enhance the inductive bias of the anomaly detection task by fitting a normalizing flow directly to the small and unknown signal component, while holding fixed a background model (also a normalizing flow) learned from sidebands. In doing so, R-ANODE is able to outperform all classifier-based, weakly-supervised approaches, as well as the previous ANODE method which fit a density estimator to all of the data in the signal region instead of just the signal. We show that the method works equally well whether the unknown signal fraction is learned or fixed, and is even robust to signal fraction misspecification. Finally, with the learned signal model we can sample and gain qualitative insights into the underlying anomaly, which greatly enhances the interpretability of resonant anomaly detection and offers the possibility of simultaneously discovering and characterizing the new physics that could be hiding in the data.
Flow Matching Beyond Kinematics: Generating Jets with Particle-ID and Trajectory Displacement Information
Nov 30, 2023We introduce the first generative model trained on the JetClass dataset. Our model generates jets at the constituent level, and it is a permutation-equivariant continuous normalizing flow (CNF) trained with the flow matching technique. It is conditioned on the jet type, so that a single model can be used to generate the ten different jet types of JetClass. For the first time, we also introduce a generative model that goes beyond the kinematic features of jet constituents. The JetClass dataset includes more features, such as particle-ID and track impact parameter, and we demonstrate that our CNF can accurately model all of these additional features as well. Our generative model for JetClass expands on the versatility of existing jet generation techniques, enhancing their potential utility in high-energy physics research, and offering a more comprehensive understanding of the generated jets.
Fast Parameter Inference on Pulsar Timing Arrays with Normalizing Flows
Oct 18, 2023Pulsar timing arrays (PTAs) perform Bayesian posterior inference with expensive MCMC methods. Given a dataset of ~10-100 pulsars and O(10^3) timing residuals each, producing a posterior distribution for the stochastic gravitational wave background (SGWB) can take days to a week. The computational bottleneck arises because the likelihood evaluation required for MCMC is extremely costly when considering the dimensionality of the search space. Fortunately, generating simulated data is fast, so modern simulation-based inference techniques can be brought to bear on the problem. In this paper, we demonstrate how conditional normalizing flows trained on simulated data can be used for extremely fast and accurate estimation of the SGWB posteriors, reducing the sampling time from weeks to a matter of seconds.