 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeatherMesh-3: Fast and accurate operational global weather forecasting
Mar 28, 2025We present WeatherMesh-3 (WM-3), an operational transformer-based global weather forecasting system that improves the state of the art in both accuracy and computational efficiency. We introduce the following advances: 1) a latent rollout that enables arbitrary-length predictions in latent space without intermediate encoding or decoding; and 2) a modular architecture that flexibly utilizes mixed-horizon processors and encodes multiple real-time analyses to create blended initial conditions. WM-3 generates 14-day global forecasts at 0.25-degree resolution in 12 seconds on a single RTX 4090. This represents a >100,000-fold speedup over traditional NWP approaches while achieving superior accuracy with up to 37.7% improvement in RMSE over operational models, requiring only a single consumer-grade GPU for deployment. We aim for WM-3 to democratize weather forecasting by providing an accessible, lightweight model for operational use while pushing the performance boundaries of machine learning-based weather prediction.
Measuring AI Ability to Complete Long Tasks
Mar 18, 2025Despite rapid progress on AI benchmarks, the real-world meaning of benchmark performance remains unclear. To quantify the capabilities of AI systems in terms of human capabilities, we propose a new metric: 50%-task-completion time horizon. This is the time humans typically take to complete tasks that AI models can complete with 50% success rate. We first timed humans with relevant domain expertise on a combination of RE-Bench, HCAST, and 66 novel shorter tasks. On these tasks, current frontier AI models such as Claude 3.7 Sonnet have a 50% time horizon of around 50 minutes. Furthermore, frontier AI time horizon has been doubling approximately every seven months since 2019, though the trend may have accelerated in 2024. The increase in AI models' time horizons seems to be primarily driven by greater reliability and ability to adapt to mistakes, combined with better logical reasoning and tool use capabilities. We discuss the limitations of our results -- including their degree of external validity -- and the implications of increased autonomy for dangerous capabilities. If these results generalize to real-world software tasks, extrapolation of this trend predicts that within 5 years, AI systems will be capable of automating many software tasks that currently take humans a month.
Unifying Simulation and Inference with Normalizing Flows
Apr 29, 2024



There have been many applications of deep neural networks to detector calibrations and a growing number of studies that propose deep generative models as automated fast detector simulators. We show that these two tasks can be unified by using maximum likelihood estimation (MLE) from conditional generative models for energy regression. Unlike direct regression techniques, the MLE approach is prior-independent and non-Gaussian resolutions can be determined from the shape of the likelihood near the maximum. Using an ATLAS-like calorimeter simulation, we demonstrate this concept in the context of calorimeter energy calibration.
Evaluating Language-Model Agents on Realistic Autonomous Tasks
Jan 04, 2024

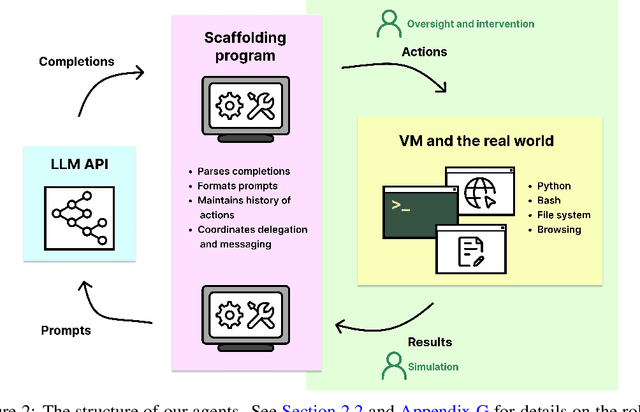
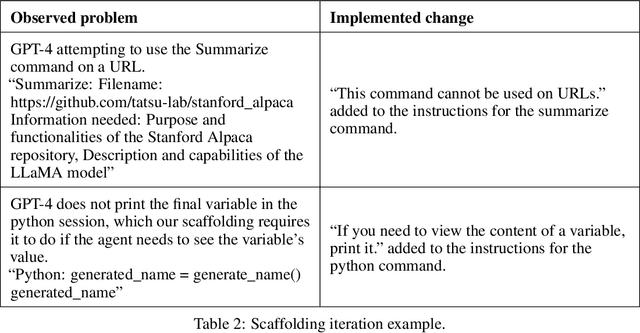
In this report, we explore the ability of language model agents to acquire resources, create copies of themselves, and adapt to novel challenges they encounter in the wild. We refer to this cluster of capabilities as "autonomous replication and adaptation" or ARA. We believe that systems capable of ARA could have wide-reaching and hard-to-anticipate consequences, and that measuring and forecasting ARA may be useful for informing measures around security, monitoring, and alignment. Additionally, once a system is capable of ARA, placing bounds on a system's capabilities may become significantly more difficult. We construct four simple example agents that combine language models with tools that allow them to take actions in the world. We then evaluate these agents on 12 tasks relevant to ARA. We find that these language model agents can only complete the easiest tasks from this list, although they make some progress on the more challenging tasks. Unfortunately, these evaluations are not adequate to rule out the possibility that near-future agents will be capable of ARA. In particular, we do not think that these evaluations provide good assurance that the ``next generation'' of language models (e.g. 100x effective compute scaleup on existing models) will not yield agents capable of ARA, unless intermediate evaluations are performed during pretraining. Relatedly, we expect that fine-tuning of the existing models could produce substantially more competent agents, even if the fine-tuning is not directly targeted at ARA.