 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHCAST: Human-Calibrated Autonomy Software Tasks
Mar 21, 2025To understand and predict the societal impacts of highly autonomous AI systems, we need benchmarks with grounding, i.e., metrics that directly connect AI performance to real-world effects we care about. We present HCAST (Human-Calibrated Autonomy Software Tasks), a benchmark of 189 machine learning engineering, cybersecurity, software engineering, and general reasoning tasks. We collect 563 human baselines (totaling over 1500 hours) from people skilled in these domains, working under identical conditions as AI agents, which lets us estimate that HCAST tasks take humans between one minute and 8+ hours. Measuring the time tasks take for humans provides an intuitive metric for evaluating AI capabilities, helping answer the question "can an agent be trusted to complete a task that would take a human X hours?" We evaluate the success rates of AI agents built on frontier foundation models, and we find that current agents succeed 70-80% of the time on tasks that take humans less than one hour, and less than 20% of the time on tasks that take humans more than 4 hours.
Measuring AI Ability to Complete Long Tasks
Mar 18, 2025Despite rapid progress on AI benchmarks, the real-world meaning of benchmark performance remains unclear. To quantify the capabilities of AI systems in terms of human capabilities, we propose a new metric: 50%-task-completion time horizon. This is the time humans typically take to complete tasks that AI models can complete with 50% success rate. We first timed humans with relevant domain expertise on a combination of RE-Bench, HCAST, and 66 novel shorter tasks. On these tasks, current frontier AI models such as Claude 3.7 Sonnet have a 50% time horizon of around 50 minutes. Furthermore, frontier AI time horizon has been doubling approximately every seven months since 2019, though the trend may have accelerated in 2024. The increase in AI models' time horizons seems to be primarily driven by greater reliability and ability to adapt to mistakes, combined with better logical reasoning and tool use capabilities. We discuss the limitations of our results -- including their degree of external validity -- and the implications of increased autonomy for dangerous capabilities. If these results generalize to real-world software tasks, extrapolation of this trend predicts that within 5 years, AI systems will be capable of automating many software tasks that currently take humans a month.
Modular addition without black-boxes: Compressing explanations of MLPs that compute numerical integration
Dec 04, 2024



The goal of mechanistic interpretability is discovering simpler, low-rank algorithms implemented by models. While we can compress activations into features, compressing nonlinear feature-maps -- like MLP layers -- is an open problem. In this work, we present the first case study in rigorously compressing nonlinear feature-maps, which are the leading asymptotic bottleneck to compressing small transformer models. We work in the classic setting of the modular addition models, and target a non-vacuous bound on the behaviour of the ReLU MLP in time linear in the parameter-count of the circuit. To study the ReLU MLP analytically, we use the infinite-width lens, which turns post-activation matrix multiplications into approximate integrals. We discover a novel interpretation of} the MLP layer in one-layer transformers implementing the ``pizza'' algorithm: the MLP can be understood as evaluating a quadrature scheme, where each neuron computes the area of a rectangle under the curve of a trigonometric integral identity. Our code is available at https://tinyurl.com/mod-add-integration.
RE-Bench: Evaluating frontier AI R&D capabilities of language model agents against human experts
Nov 22, 2024Frontier AI safety policies highlight automation of AI research and development (R&D) by AI agents as an important capability to anticipate. However, there exist few evaluations for AI R&D capabilities, and none that are highly realistic and have a direct comparison to human performance. We introduce RE-Bench (Research Engineering Benchmark, v1), which consists of 7 challenging, open-ended ML research engineering environments and data from 71 8-hour attempts by 61 distinct human experts. We confirm that our experts make progress in the environments given 8 hours, with 82% of expert attempts achieving a non-zero score and 24% matching or exceeding our strong reference solutions. We compare humans to several public frontier models through best-of-k with varying time budgets and agent designs, and find that the best AI agents achieve a score 4x higher than human experts when both are given a total time budget of 2 hours per environment. However, humans currently display better returns to increasing time budgets, narrowly exceeding the top AI agent scores given an 8-hour budget, and achieving 2x the score of the top AI agent when both are given 32 total hours (across different attempts). Qualitatively, we find that modern AI agents possess significant expertise in many ML topics -- e.g. an agent wrote a faster custom Triton kernel than any of our human experts' -- and can generate and test solutions over ten times faster than humans, at much lower cost. We open-source the evaluation environments, human expert data, analysis code and agent trajectories to facilitate future research.
Mathematical Models of Computation in Superposition
Aug 10, 2024Superposition -- when a neural network represents more ``features'' than it has dimensions -- seems to pose a serious challenge to mechanistically interpreting current AI systems. Existing theory work studies \emph{representational} superposition, where superposition is only used when passing information through bottlenecks. In this work, we present mathematical models of \emph{computation} in superposition, where superposition is actively helpful for efficiently accomplishing the task. We first construct a task of efficiently emulating a circuit that takes the AND of the $\binom{m}{2}$ pairs of each of $m$ features. We construct a 1-layer MLP that uses superposition to perform this task up to $\varepsilon$-error, where the network only requires $\tilde{O}(m^{\frac{2}{3}})$ neurons, even when the input features are \emph{themselves in superposition}. We generalize this construction to arbitrary sparse boolean circuits of low depth, and then construct ``error correction'' layers that allow deep fully-connected networks of width $d$ to emulate circuits of width $\tilde{O}(d^{1.5})$ and \emph{any} polynomial depth. We conclude by providing some potential applications of our work for interpreting neural networks that implement computation in superposition.
Compact Proofs of Model Performance via Mechanistic Interpretability
Jun 24, 2024



In this work, we propose using mechanistic interpretability -- techniques for reverse engineering model weights into human-interpretable algorithms -- to derive and compactly prove formal guarantees on model performance. We prototype this approach by formally proving lower bounds on the accuracy of 151 small transformers trained on a Max-of-$K$ task. We create 102 different computer-assisted proof strategies and assess their length and tightness of bound on each of our models. Using quantitative metrics, we find that shorter proofs seem to require and provide more mechanistic understanding. Moreover, we find that more faithful mechanistic understanding leads to tighter performance bounds. We confirm these connections by qualitatively examining a subset of our proofs. Finally, we identify compounding structureless noise as a key challenge for using mechanistic interpretability to generate compact proofs on model performance.
Provable Guarantees for Model Performance via Mechanistic Interpretability
Jun 18, 2024In this work, we propose using mechanistic interpretability -- techniques for reverse engineering model weights into human-interpretable algorithms -- to derive and compactly prove formal guarantees on model performance. We prototype this approach by formally proving lower bounds on the accuracy of 151 small transformers trained on a Max-of-$K$ task. We create 102 different computer-assisted proof strategies and assess their length and tightness of bound on each of our models. Using quantitative metrics, we find that shorter proofs seem to require and provide more mechanistic understanding. Moreover, we find that more faithful mechanistic understanding leads to tighter performance bounds. We confirm these connections by qualitatively examining a subset of our proofs. Finally, we identify compounding structureless noise as a key challenge for using mechanistic interpretability to generate compact proofs on model performance.
Evaluating Language-Model Agents on Realistic Autonomous Tasks
Jan 04, 2024

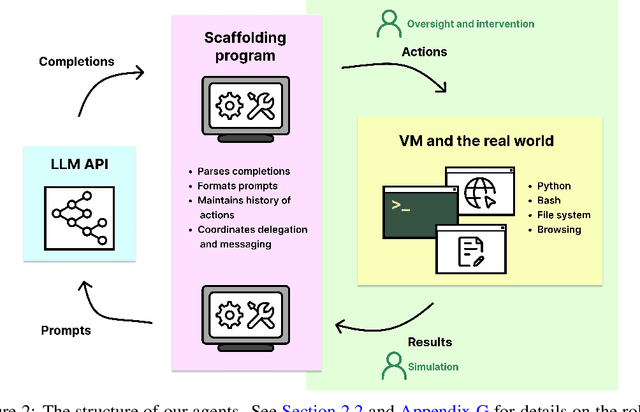
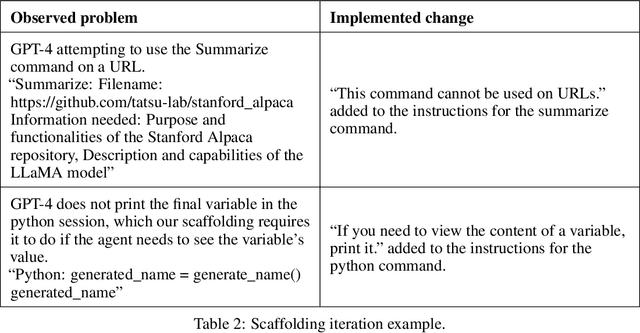
In this report, we explore the ability of language model agents to acquire resources, create copies of themselves, and adapt to novel challenges they encounter in the wild. We refer to this cluster of capabilities as "autonomous replication and adaptation" or ARA. We believe that systems capable of ARA could have wide-reaching and hard-to-anticipate consequences, and that measuring and forecasting ARA may be useful for informing measures around security, monitoring, and alignment. Additionally, once a system is capable of ARA, placing bounds on a system's capabilities may become significantly more difficult. We construct four simple example agents that combine language models with tools that allow them to take actions in the world. We then evaluate these agents on 12 tasks relevant to ARA. We find that these language model agents can only complete the easiest tasks from this list, although they make some progress on the more challenging tasks. Unfortunately, these evaluations are not adequate to rule out the possibility that near-future agents will be capable of ARA. In particular, we do not think that these evaluations provide good assurance that the ``next generation'' of language models (e.g. 100x effective compute scaleup on existing models) will not yield agents capable of ARA, unless intermediate evaluations are performed during pretraining. Relatedly, we expect that fine-tuning of the existing models could produce substantially more competent agents, even if the fine-tuning is not directly targeted at ARA.
A Toy Model of Universality: Reverse Engineering How Networks Learn Group Operations
Feb 06, 2023



Universality is a key hypothesis in mechanistic interpretability -- that different models learn similar features and circuits when trained on similar tasks. In this work, we study the universality hypothesis by examining how small neural networks learn to implement group composition. We present a novel algorithm by which neural networks may implement composition for any finite group via mathematical representation theory. We then show that networks consistently learn this algorithm by reverse engineering model logits and weights, and confirm our understanding using ablations. By studying networks of differing architectures trained on various groups, we find mixed evidence for universality: using our algorithm, we can completely characterize the family of circuits and features that networks learn on this task, but for a given network the precise circuits learned -- as well as the order they develop -- are arbitrary.
Progress measures for grokking via mechanistic interpretability
Jan 13, 2023



Neural networks often exhibit emergent behavior, where qualitatively new capabilities arise from scaling up the amount of parameters, training data, or training steps. One approach to understanding emergence is to find continuous \textit{progress measures} that underlie the seemingly discontinuous qualitative changes. We argue that progress measures can be found via mechanistic interpretability: reverse-engineering learned behaviors into their individual components. As a case study, we investigate the recently-discovered phenomenon of ``grokking'' exhibited by small transformers trained on modular addition tasks. We fully reverse engineer the algorithm learned by these networks, which uses discrete Fourier transforms and trigonometric identities to convert addition to rotation about a circle. We confirm the algorithm by analyzing the activations and weights and by performing ablations in Fourier space. Based on this understanding, we define progress measures that allow us to study the dynamics of training and split training into three continuous phases: memorization, circuit formation, and cleanup. Our results show that grokking, rather than being a sudden shift, arises from the gradual amplification of structured mechanisms encoded in the weights, followed by the later removal of memorizing components.